GTC Silicon Valley-2019: Efficient Distributed Storage I/O using NVMe and GPUDirect in a PCIe Network
Note: This video may require joining the NVIDIA Developer Program or login
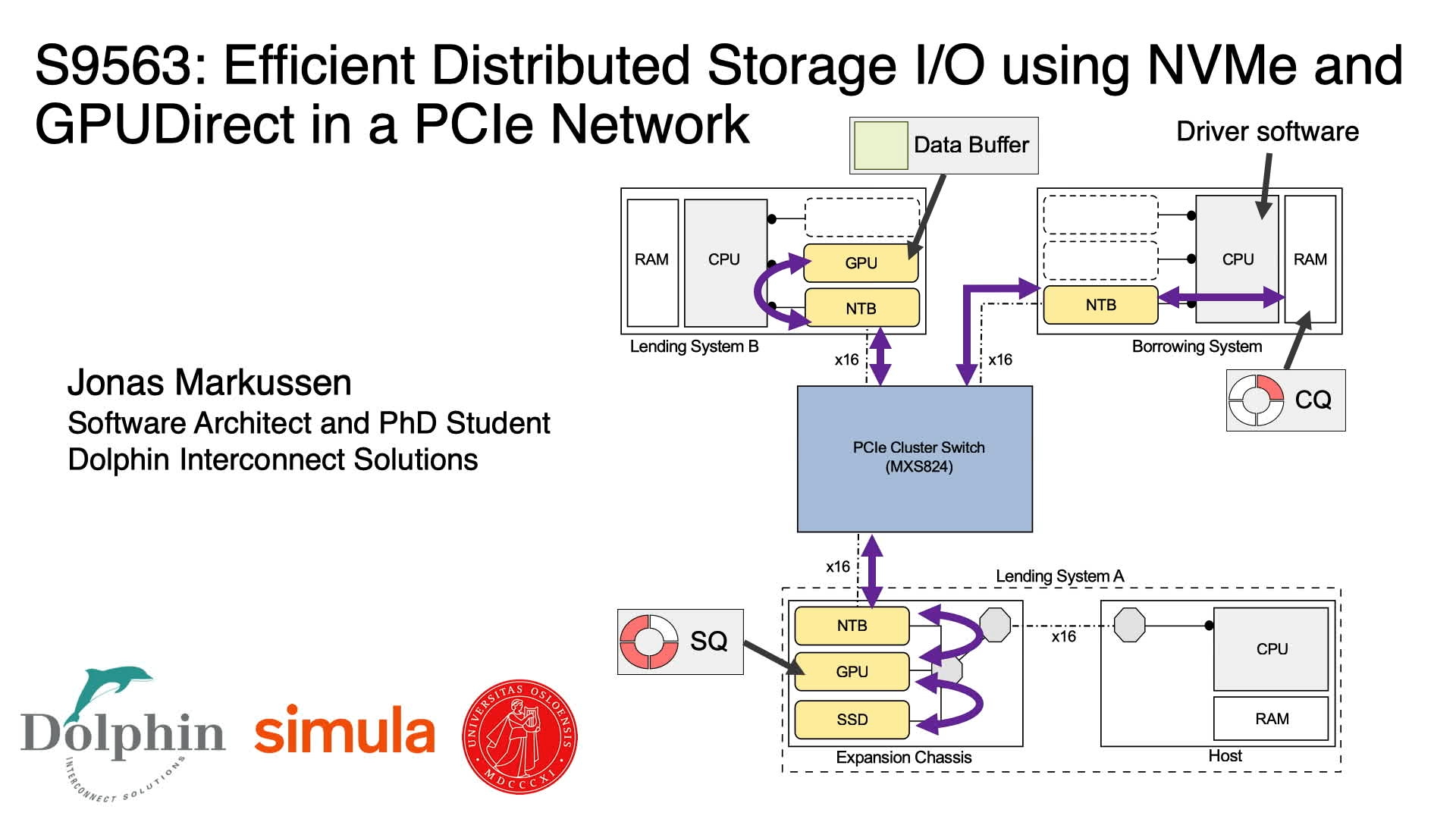
GTC Silicon Valley-2019 ID:S9563:Efficient Distributed Storage I/O using NVMe and GPUDirect in a PCIe Network
Jonas Markussen(Dolphin Interconnect Solutions)
Loading and storing file content to remote disk in CUDA applications typically requires using traditional file and network abstractions provided by the operating system. We'll show how GPUDirect changes that, making it possible to expose GPU memory directly to third-party devices such as NVM Express (NVMe). We'll introduce our proof-of-concept software library for creating GPU-Oriented storage applications with GPUDirect-capable GPUs and commodity NVMe disks residing in multiple remote hosts. Learn how we use the memory-mapping capabilities of PCIe non-transparent bridges to set up efficient I/O data paths between GPUs and disks that are attached to different root complexes (hosts) in a PCIe network. We'll demonstrate how our solution can initiate remote disk I/O from within a CUDA kernel. We will also compare our approach to state-of-the-art NVMe over fabrics and share our results for running a distributed workload on multiple GPUs using a remote disk.