Tutorials

July 30, 2026
Run High-Performance Core Math at Scale with NVIDIA nvmath-python

July 29, 2026
How to Self-Host a Validated AI Coding Assistant with NVIDIA NeMo Guardrails

July 26, 2026
NVIDIA Nemotron 3 Ultra Leads Open Models on Accuracy and Efficiency in Agentic RTL Coding
News

July 31, 2026
NVIDIA Video Codec SDK 13.1: Zero-Copy Transcode, AV1 B-Frames, and Frame-Accurate Seek

July 26, 2026
Advancing Semiconductor Innovation Across Materials Engineering and Manufacturing

July 15, 2026
Build a Multi-Camera 3D Tracking Application with NVIDIA DeepStream 9.1 Skills

July 14, 2026
Lessons From the Leaderboard: What 5,000+ Kagglers Taught Us About Improving AI Reasoning
Training
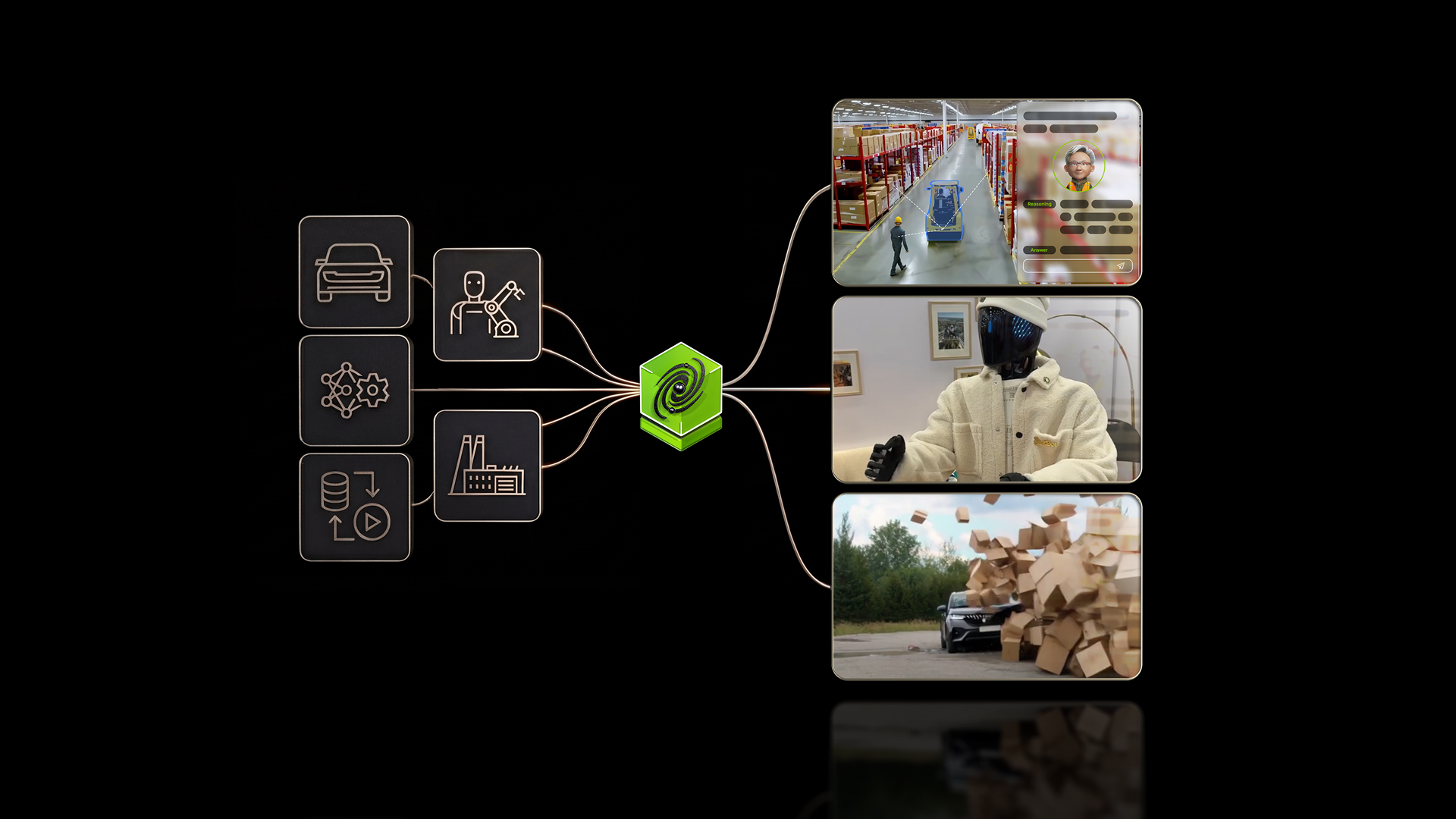
The NVIDIA Cosmos Cookoff Is Here

Global Webinar: What's New With NVIDIA Certification in 2026