cuQuantum
NVIDIA cuQuantum is an SDK of optimized libraries and tools that accelerate quantum computing emulations at both the circuit and device level by orders of magnitude.
Features and Benefits
Flexible
Choose the best approach for your work from algorithm-agnostic accelerated quantum circuit simulation methods.
State vector method features include optimized memory management and, gate application kernels.
Tensor Network Method features include accelerated tensor network contraction, order optimization, and approximate contractions.
Density matrix method features include arbitrary operator action on the state.
Scalable
Leverage the power of multi-node, multi-GPU clusters using the latest GPUs on premises or in the cloud.
Low-level C++ APIs provide increased control and flexibility for a single GPU and single-node multi-GPU clusters.
The high-level Python API supports drop-in multi-node execution.
Fast
Simulate bigger problems faster, and get more work done sooner.
Using an NVIDIA H200 Tensor Core GPU over CPU implementations delivers orders-of-magnitude speedups on key quantum problems, including random quantum circuits, Shor’s algorithm, and the Variational Quantum Eigensolver.
Leveraging the NVIDIA Eos supercomputer, cuQuantum generated a sample from a full-circuit simulation of the Google Sycamore processor in less than five minutes.
cuQuantum Framework Integrations
cuQuantum is integrated with leading quantum simulation frameworks. Download cuQuantum to dramatically accelerate performance using your framework of choice, with zero code changes.
Components
Tools to accelerate quantum emulations on NVIDIA hardware.
Largest Scale Dynamics
Designing quantum computers and devices has always been challenging. Simulations for these problems can be slow and limited in their ability to scale. cuQuantum now includes time dynamics functionality, which enables users to accelerate analog Hamiltonian dynamics to unprecedented scales. Users can now better understand how to optimize device design where quantum phenomena occur faster than before.
By distributing the state and operators across multi-GPU, multi-node systems, cuQuantum allows phase space exploration larger than ever before, only limited by the number of GPUs a user has access to.
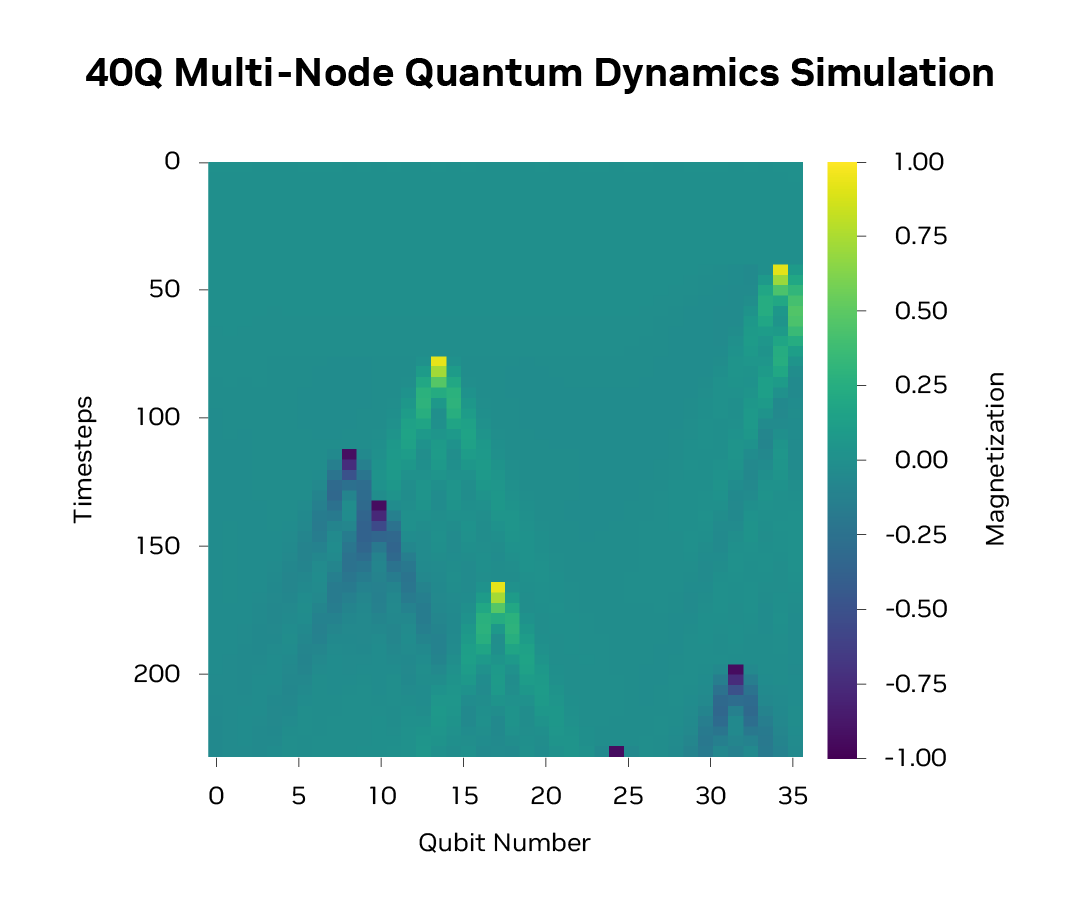
Google was able to scale simulations of analog dynamics on its processors to 40 qubits with 1024 GPUs using NVIDIA’s Eos supercomputer. This enables QPU builders like Google to understand long-range effects on their devices, perform validation, and design more effectively than ever before, ushering in a new age for QPU design.
Fastest GPU Implementations
The core operator action API gives developers of custom solvers the flexibility to apply arbitrary time-dependent operators to the quantum state more efficiently than was previously possible. Our advanced algorithms allow us to scale further with the same hardware memory.
This enables users to design better quantum systems more quickly than was previously possible. With multi-GPU memory, developers can drastically accelerate their QPU design cycle by simulating 473 different quantum systems in the time it formerly took to do just one. Strong scaling shows that these APIs can speed up a range of Hamiltonians and operator terms to even further accelerate the hardware development cycle.

cuDensityMat speeds up and scales simulations beyond what was previously possible with the next-best alternatives. Simulating a qudit coupler resonator is multiple orders of magnitude faster and can scale simulations to an arbitrary number of GPUs. This shows scaling to 1024 GPUs with NVIDIA GB200 NVL72 for a Hilbert space with 1.44 million levels. Users can now study much more complex systems and larger unit cells of quantum devices.
Multi-GPU Speedups
State vector simulation tracks the entire state of the system over time, through each gate operation. It’s an excellent tool for simulating deep or highly entangled quantum circuits, and for simulating noisy qubits.
Recent software updates to our offering have enabled a 5.53x speedup over previously reported numbers. When combined with ~2.5x speedups offered by NVIDIA Blackwell GPUs, users see even greater speedups over CPU implementations, despite CPU hardware and software improvements.

cuStateVec speeds up noisy simulations of critical quantum algorithms, such as the quantum Fourier transform, by 25x on NVIDIA GB200 NVL72 over a single GPU, achieving nearly linear scaling. This tool enables extremely fast noisy quantum simulations to be done with speed of light on the NVIDIA stack.
Multi-Node Speedups
This multi-node capability enables users of the NVIDIA Quantum platform to achieve the most performant quantum circuit simulations at supercomputer scales. On key problems like quantum phase estimation, quantum approximate optimization algorithm (QAOA), quantum volume, and more, the newest cuQuantum Appliance is over two orders of magnitude faster than previous implementations and seamlessly scales from a single GPU to a supercomputer.

Performance is benchmarked leveraging quantum volume with a depth of 30, along with QAOA and a small quantum phase estimation, run on NVIDIA GB200 NVL72 up to 40 qubits in single precision. On average, cuQuantum with B200 GPUs is 3x faster than H100s at 40 qubits.
Pathfinding Performance
Tensor network methods are rapidly gaining popularity to simulate hundreds or thousands of qubits for near-term quantum algorithms. Tensor networks scale with the number of quantum gates rather than the number of qubits. This makes it possible to simulate very large qubit counts with smaller gate counts on large supercomputers.
Tensor contractions dramatically reduce the memory requirement for running a circuit on a tensor network simulator. The research community is investing heavily in improving pathfinding methods for quickly finding near-optimal tensor contractions before running a simulation.
cuTensorNet provides state-of-the-art performance for both the pathfinding and contraction stages of tensor network simulation.
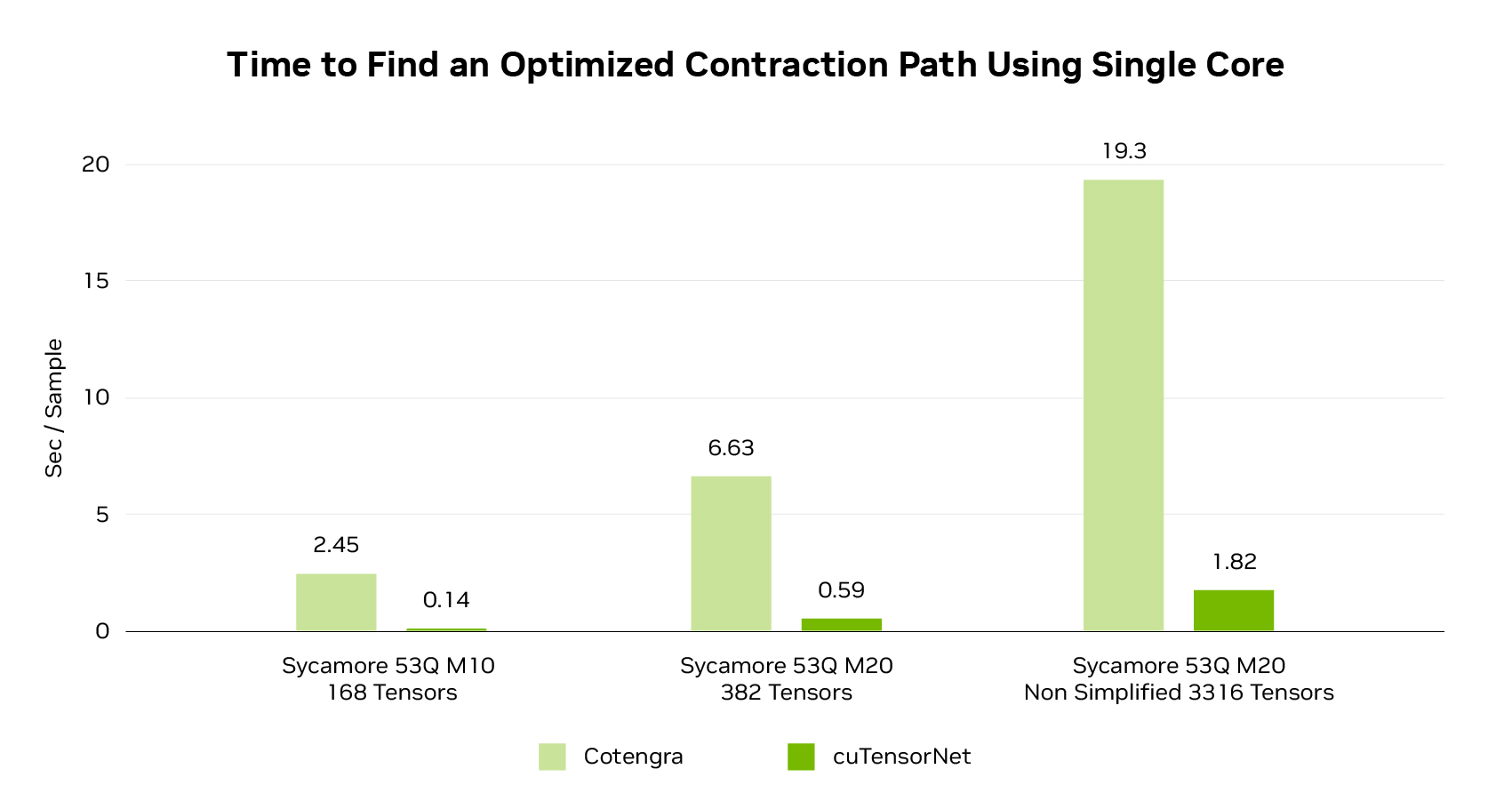
Performance for cuTensorNet pathfinding compared to Cotengra in terms of seconds per sample. Both runs are leveraging a single-core Xeon Platinum 8480+.
Sycamore refers to 53-qubit random quantum circuits of depth 10, and 20 from Arute et al., Quantum supremacy using a programmable superconducting processor. www.nature.com/articles/s41586-019-1666-5
Cotengra: Gray & Kourtis, Hyper-optimized Tensor Network Contraction, 2021. quantum-journal.org/papers/q-2021-03-15-410
Less Contraction Time, More Efficiency
When comparing contraction performance for cuTensorNet against Torch, cuPy, and NumPy, all runs leverage the same best contraction path. cuTensorNet, cuPy, and Torch all ran on one NVIDIA B200 GPU, and NumPy was run on a single-socket Emerald Rapids CPU.
Using cuQuantum, NVIDIA researchers simulated a quantum support vector machine for a wide range of classification problems using 65,000 qubits on the NVIDIA GB200 NVL72—orders of magnitude larger than the largest problem run on quantum hardware to date.


Sycamore Circuit: 53 qubits depth 10
Quantum Fourier Transform: 34 qubits
Inverse Quantum Fourier Transform: 36 qubits
Quantum Volume: 26 and 30 qubits with depth 30
QAOA: 36 qubits with one and four parameters
Approximate Tensor Network Methods
As quantum problems of interest can greatly vary in both size and complexity, researchers have developed highly customized approximate tensor network algorithms to address the gamut of possibilities. To enable easy integration with these frameworks and libraries, cuTensorNet provides a set of APIs to cover the following common use cases: tensor QR, tensor SVD, and gate split. These primitives enable users to accelerate and scale different types of quantum circuit simulators. A common approach to simulating quantum computers, which takes advantage of these methods, is Matrix Product States (MPS, also known as tensor train). Users can leverage these new cuTensorNet APIs to accelerate MPS-based quantum circuit simulators. The gate split and tensor SVD APIs enable nearly an order of magnitude speedup over state-of-the-art CPU implementations. Tensor QR is the most efficient, with nearly two orders-of-magnitude speedup over the same Xeon 8480+ CPU.
Learn More About cuTensorNet
MPS Singular Value Decomposition performance is measured in execution time as a function of bond dimension. We execute this on an NVIDIA B200 140 GB GPU and compare it to NumPy running on an EPYC 9124 data center CPU.
Fast Expectation Values
Simulating large-scale quantum systems and calculating the observables has been expensive with other approaches, such as Matrix Product State methods. Pauli propagation techniques express observables in terms of an expansion in products of Pauli operators and allow tracking of only the most important ones as the circuit is applied in reverse to the observable, leading to very efficient expectation value calculations. While this effort has largely been restricted to CPU hardware, cuQuantum offers primitives to drastically accelerate and scale this workload on GPUs today. This will enable cutting-edge researchers and quantum computer builders to validate and verify their results in regimes not previously possible.
Learn More About cuPauliProp
cuQuantum GPU simulations for pi/4 rotations of the 127 qubit IBM utility circuit show multiple orders of magnitude speedups for a range of truncation schemes on NVIDIA DGX B200 compared to Qiskit PauliProp on an Intel Xeon Platinum 8570 CPU.
High Sampling Rates
Understanding the effect of noise on Clifford circuits is a key for Quantum Error Correction (QEC) and hardware development. This involves simulating how rare noise events affect quantum measurements, which makes such simulation a critical workload for developing error correction codes and decoders to fix these errors. Users who leverage GPU acceleration are able to increase the rates at which they can perform offline real-time decoding with decoders and simulators in the same loop. Similarly, generating synthetic data to train AI-based decoders is often bottlenecked by CPU simulation. By bringing the emulation of Clifford circuits onto GPUs, this tool can add value to researchers on the cutting edge.
Learn More About cuStabilizer
Runtime performance on rotated surface code of different distances and 1 million shots with a physical error rate of 0.001, comparing stim plus cuStabilizer on an NVIDIA DGX B200 GPU with stim on an Intel Xeon Platinum 8570 CPU. For code distance 30, we see 1060x speedup.
Resources
Whether you’re a researcher, developer, or enthusiast, our resources are tailored to help you get the most out of your quantum simulations and algorithms. Explore these resources to unlock the full potential of cuQuantum and accelerate your quantum research and development.