NVIDIA Metropolis
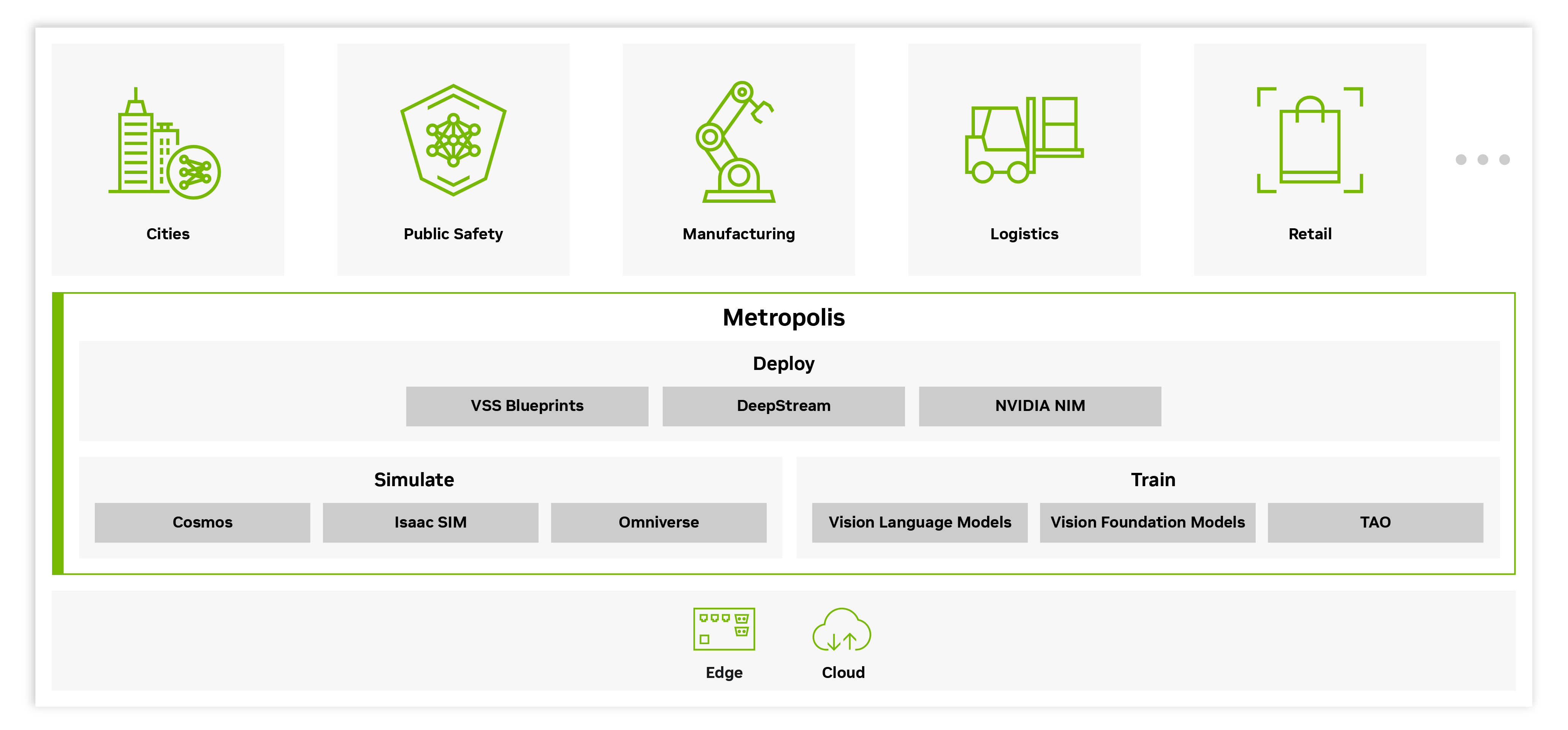
NVIDIA Metropolis is a collection of models, libraries, and blueprints that provides everything you need to build, deploy, and scale video analytics AI agents and applications, from the edge to the cloud. You can now easily transform raw video and sensor data from real-world environments into real-time, actionable insights. This helps your organization understand what’s happening in your physical spaces and respond intelligently, while delivering exceptional scale, throughput, cost-effectiveness, and faster time to production.
How Metropolis Works
Metropolis offers a cohesive, end-to-end stack of software building blocks that handle everything from video ingestion to insight generation to advanced agentic AI-powered analytics. These components can be deployed consistently across the whole compute spectrum—on the edge, in on-prem servers, or in the cloud—so the same applications can run close to where data is generated or centrally at scale.
Agentic Video Search at Scale With NVIDIA VSS Blueprint and Skills
Dive into the details of the new VSS 3.0 skills in agentic search, modular design, reference workflows, and more.
Create Vision AI Applications With NVIDIA DeepStream Skills
Learn how to generate complete, GPU-accelerated NVIDIA DeepStream video analytics pipelines using simple natural language prompts.
Try DeepStream Skills
Fine-Tune Vision AI Models With NVIDIA TAO Skills
Try a suite of agent skills and tools for fine-tuning vision AI models with natural language prompts.
Solve the Training Data Challenge With Agent Skills
Use agent skills to quickly generate synthetic data for visual inspection or augment videos for edge-cases.
Get Started With Metropolis
Start using the latest Metropolis vision language and vision foundation models.
NVIDIA Cosmos
Meet the first OmniModel that sees, reasons, generates many outcomes, and teaches physical agents how to act in the real world.
Vision AI NIMs
Discover GPU-optimized microservices that bring ready-to-use vision and multimodal models through simple APIs.
Embeddings
Turn images, videos, and text into vector representations for physical AI and multimodal understanding using NVIDIA models like Cosmos Embed, C-RADIO, and NV-CLIP.
Post-train your vision AI models with domain-specific data to boost accuracy.
Cosmos Cookbook
Access recipes to post-train Cosmos WFMs with supervised fine-tuning and reinforcement learning.
Learn MoreTAO
Explore a suite of agent skills and tools for fine-tuning vision AI models with coding agents and natural language prompts.
Start developing vision AI applications with foundational Metropolis frameworks.
NVIDIA Metropolis Blueprint For Video Search and Summarization (VSS)
The VSS blueprint lets you build customizable video analytics AI agents to deliver powerful insights with seamless edge-to-cloud integration. VSS also brings skills to build these agents from simple natural language prompts using coding agents.Î
Try It NowNVIDIA DeepStream
This is a complete streaming analytics toolkit for AI-based multi-sensor processing, video, audio, and image understanding.
Learn MoreGenerate high-quality synthetic data to safely and efficiently train your AI models.
Physical AI Dataset
Unblock data bottlenecks with an open-source, validated dataset for training vision AI in industries, cities, robotics, and autonomous systems—now free on Hugging Face.
Explore the NVIDIA Physical AI DatasetAgent Skills for Synthetic Data Generation
Build a synthetic data generation pipeline with your own video or image data. Then, curate, augment, and evaluate it with Cosmos open WFMs to accelerate vision AI model development.
Isaac Sim
Enable developers to create realistic synthetic data from complex 3D environments to train vision AI models.
Starter Kits
Develop Video Analytics AI Agents
Build intelligent systems that can see, understand, and interact with the world through computer vision and real-time visual reasoning.
Build a Vision Inference Pipeline
Develop a streaming pipeline with DeepStream that ingests videos, preprocesses frames, and runs optimized vision AI models.
Build Agents for Smart City and Warehouse Operation
Explore examples for optimized VSS blueprint configuration with sample data, tailored prompts, and report templates.
Post-Train NVIDIA Cosmos 3
Boost accuracy for your use cases with automated LoRA fine-tuning and AutoML using NVIDIA TA0 agent skills
Fine-Tune Vision Foundation Models
Adapt powerful pre-trained vision backbones with targeted domain data so they specialize on your tasks while retaining their broad visual understanding.
Tech Blog : Build a Real-Time Visual Inspection Pipeline
Generate Synthetic Data
Create synthetic images and videos to expand training datasets, reduce collection costs, and improve vision model robustness across diverse scenarios.
More Resources
Ethical AI
NVIDIA believes Trustworthy AI is a shared responsibility and we have established policies and practices to enable development for a wide array of AI applications. When downloaded or used in accordance with our terms of service, developers should work with their supporting model team to ensure this model meets requirements for the relevant industry and use case and addresses unforeseen product misuse.
For more detailed information on ethical considerations for this model, please see the Model Card++ Explainability, Bias, Safety & Security, and Privacy Subcards. Please report security vulnerabilities or NVIDIA AI Concerns here.
Develop, deploy, and scale AI-enabled video analytics applications with
NVIDIA Metropolis.