
GPU Gems 2
GPU Gems 2 is now available, right here, online. You can purchase a beautifully printed version of this book, and others in the series, at a 30% discount courtesy of InformIT and Addison-Wesley.
The CD content, including demos and content, is available on the web and for download.
Chapter 12. Tile-Based Texture Mapping
Li-Yi Wei
NVIDIA Corporation
Many graphics applications such as games and simulations frequently use large textures for walls, floors, or terrain. There are several issues with large textures. First, they can consume significant storage, in either disk space, system memory, or graphics memory. Second, they can consume significant bandwidth, during either initial texture loading or rendering. Third, most graphics cards impose an upper limit on individual texture sizes. For example, the GeForce 6800 has an upper resolution limit of 4,096x4,096 for RGBA8 textures, and many other GPUs have stricter limitations.
One possible solution to address these problems is texture compression. However, existing GPU texture-compression techniques such as DXT have a limited compression ratio. In addition, texture compression cannot handle the problem of texture size limit.
An alternative approach is texture tiling, as shown in Figure 12-1. For example, if we have a large wall or floor consisting of repeating tiles, then obviously we don't have to store all the tiles. Instead, we could have just one tile and repeat it on the wall. For more complex patterns, we can dice up the wall or floor into smaller polygons and apply different texture tiles or texture coordinate transformations for each polygon. The advantage of this approach is that we can achieve infinite compression ratio in theory, because we can produce an arbitrarily large output from a few tiles. The disadvantage, however, lies in the complication of application code and data.

Figure 12-1 A Tile-Based Texture Map
Our goal is to present a tile-based texture-mapping scheme that is transparent to the application. Specifically, we do not require changing the original geometry or texture coordinates in order to use texture tiles. Instead, we implement the texture tiling as a fragment program that handles the details of accessing and filtering the tiled texture.
12.1 Our Approach
We represent a large texture as a small set of tiles and assemble the tiles into a large virtual texture on the fly for answering texture requests. To minimize visual repetition, we assemble the tiles nonperiodically. There is a huge literature on nonperiodic tiling, but for our method, we chose Wang tiles for their simplicity (Cohen et al. 2003). Wang tiles are square tiles in which each tile edge is encoded with a color. A valid tiling requires all shared edges between tiles to have matching colors. When a set of Wang tiles is filled with texture patterns that are continuous across matching tile edges, a valid tiling from such a set can produce an arbitrarily large texture without pattern discontinuity. A sample Wang tiling is shown in Figure 12-2.

Figure 12-2 Texture Tiling Using Wang Tiles
We extend the Wang tiling approach to a GPU-friendly implementation. Given a texture request (s, t), we first figure out on which tile it lands, based on the (s, t) location. We then fetch the corresponding texels from that input texture tile. Figure 12-3 illustrates the procedure. We carefully pack the texture tiles into a single texture map so that we can perform texture fetching and filtering on this single texture via texturing hardware.
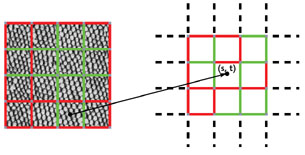
Figure 12-3 An Overview of Tile-Based Texture Mapping
12.2 Texture Tile Construction
There are several methods to construct the Wang tile set. One possibility is to draw the tiles manually; all we need to do is to ensure that the drawings are continuous across tile boundaries while producing sufficiently interesting tiling results. Figures 12-5 and 12-6, later in this chapter, show a tile set drawn by me and the tiling results, respectively. This manual approach works only for line art.
For natural texture patterns such as those from photographs, there are algorithmic ways to build the tile set, as described in Cohen et al. 2003, Section 3.2. We have found that this approach works well for many natural texture patterns, and we provide the source code on the accompanying CD. The sample tiles previously shown in Figure 12-1 were generated with this approach.
There are additional methods for constructing the tiles; we refer readers to Cohen et al. 2003 for more details.
12.3 Texture Tile Packing
One common problem with previous texture tiling or atlas approaches is the filtering issue. Specifically, given a collection of tiles, how do we perform filtering for the output virtual texture, especially when the sample is on the tile border and requires texels from multiple tiles for bilinear or trilinear filtering?
There are several possible solutions, among them performing texture filtering in the fragment program, or packing all tiles into a single texture and adding boundary padding between the tiles so that bilinear filtering would be correct. The first of these is computationally expensive, and the second consumes a large amount of texture memory.
In our approach, we pack all the texture tiles into a single texture map without any boundary padding, in a way that makes it possible to perform the texture filtering directly via the texturing hardware without fragment program emulation. We achieve this by packing a set of Wang tiles into a single texture map, ensuring that any tile edges shared between two tiles have identical edge color encoding. Because the tiles are built with a continuous pattern across identical edge colors, bilinear filtering directly across adjacent tiles produces the correct result. It is possible to prove that, for a complete tile set (that is, with all possible edge color combinations), it is always possible to pack the tiles in such a way. In addition, each tile is used only once, so there is no wasted texture memory.
Here we describe how the packing can be done, without going into detailed mathematical proofs, which can be found in Wei 2004. For clarity, we begin with packing in one dimension. We assume that we have a set of tiles with only one horizontal edge color and that we would like to pack them horizontally. The packing can be achieved with the following equation:
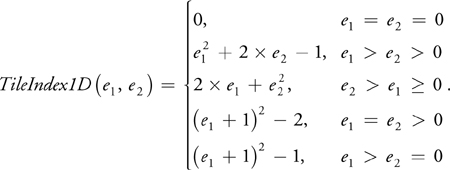
Basically, given a tile with left edge e 1 and right edge e 2, where e 1 and e 2 are integer indices starting from 0, this function computes the horizontal location of this tile within the packing. A sample 1D packing with three vertical edge colors can be found in Figure 12-4a.
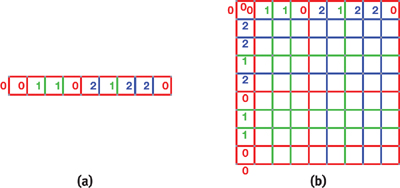
Figure 12-4 Examples of Tile Packing
The packing in 2D can be performed by computing vertical and horizontal indices separately using Equation 1. In other words, the horizontal tile location is computed from the left and right edges only, and the vertical tile location is computed from the top and bottom edges only. A 2D sample packing with three vertical and horizontal edge colors can be found in Figure 12-4b. The computation can be expressed in Cg-like code as shown in Listing 12-1.
Example 12-1. Code for Tile Packing
float TileIndex1D(const float e1, const float e2)
{
float result;
if (e1 < e2)
result = (2 * e1 + e2 * e2);
else if (e1 == e2)
if (e1 > 0)
result = ((e1 + 1) * (e1 + 1) - 2);
else
result = 0;
else if (e2 > 0)
result = (e1 * e1 + 2 * e2 - 1);
else
result = ((e1 + 1) * (e1 + 1) - 1);
return result;
}
float2 TileIndex2D(const float4 e)
{
float2 result;
// orthogonally compute the horizontal and vertical locations
// the x, y, z, w components of e store
// the south, east, north, and west edge coding
result.x = TileIndex1D(e.w, e.y);
result.y = TileIndex1D(e.x, e.z);
return result;
}12.4 Texture Tile Mapping
Given that the output virtual texture is composed from the tile set, we need to know which tile is used for each region of the texture. Specifically, for each texture coordinate (s, t), we need to be able to determine efficiently on which tile it lands.
There are two possible solutions for mapping tiles into the output texture. The first approach is simply to precompute the mapping and store the result into an index texture map. For example, if the output is composed of 128x128 tiles, then we use a 128x128 index texture to store the (row, column) location of each tile as in the input pack. Because the index texture map will have limited size, this approach isn't able to handle arbitrarily large textures. However, it is more than enough for most applications, and it is very efficient. Note that this index map does not require a mipmap pyramid because we do not require mipmap filtering for the (row, column) locations.
The second approach does not need this index texture at all; instead, the tile for each output region can be computed on the fly via a special fragment program with hashing. This approach has the advantage that it does not consume an extra texture map, and it does not suffer from the restriction on index texture map size, as in the first approach. However, in our current implementation, we have found the second approach too slow for real-time applications; so for the rest of this chapter, we discuss only the first approach. However, the second approach might be faster in future-generation GPUs, and we refer interested readers to Wei 2004 for more details.
Given that we have a precomputed index texture, the process for our tile-based texture mapping is actually pretty simple, and is best explained by the actual Cg program, as shown in Listing 12-2. Given the input coordinate, we first scale it with respect to the number of tiles in the output. We then use this scaled value to fetch the index texture, which will tell us which input tile to use. Finally, we use the fractional part of the scaled texture coordinate to fetch the final texel from the selected input tile. Note that in the final texture fetch, we need to specify the derivatives ddx and ddy to ensure the correct level-of-detail computation.
Example 12-2. Code for Tile Mapping
struct FragmentInput
{
float4 tex : TEX0;
float4 col : COL0;
};
struct FragmentOutput
{
float4 col : COL;
};
float2 mod(const float2 a, const float2 b)
{
// emulate integer mod operations in a float-only environment
return floor(frac(a / b) * b);
}
FragmentOutput fragment(FragmentInput input, uniform sampler2D tilesTexture,
uniform samplerRECT indexTexture)
{
FragmentOutput output;
// osizeh and osizev are the number of output tiles
// they are compile-time constants
float2 mappingScale = float2(osizeh, osizev);
// the scaling is required for RECT textures
// we will also need its fractional part in the final tex read
float2 mappingAddress = input.tex.xy * mappingScale;
// figure out which input tile to use
float4 whichTile = texRECT(indexTexture, mod(mappingAddress, mappingScale));
// isizeh and isizev are the number of input tiles
// they are compile-time constants
float2 tileScale = float2(isizeh, isizev);
// this is to ensure the correct input mipmap level is accessed
float2 tileScaledTex =
input.tex.xy * float2(osizeh / isizeh, osizev / isizev);
// fetch the final texel color
// note we need to specify ddx/ddy explicitly
output.col =
tex2D(tilesTexture, (whichTile.xy + frac(mappingAddress)) / tileScale,
ddx(tileScaledTex), ddy(tileScaledTex));
return output;
}12.5 Mipmap Issues
An inherent limitation of any tile-based texturing system is that mipmaps at lower resolutions are incorrect. There are actually several issues with mipmaps.
First, the maximum number of mipmap levels is constrained by the input tiles, which are of much smaller size than the output. For example, assuming we pack 4x4 tiles each with 32x32 pixels into a single 128x128 texture map, then the maximum number of mipmap levels is 8. Obviously, for any output texture larger than 128x128, we will not be able to access the coarser resolutions. In our experience, this is usually not a problem, because the tiles would reduce to a homogeneous void at lower resolutions anyway.
We also need to be careful when constructing the mipmap texture for the packed input. If you just use the automatic mipmap generation, chances are that the tiles will not be legal Wang tiles at lower mipmap resolutions. This can produce annoying aliasing artifacts when filtering across the tile boundary. Figure 12-5 demonstrates such a case.
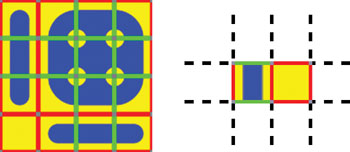
Figure 12-5 A Artifacts Caused by Filtering
As shown in Figure 12-5, in the output we
have two tiles
 , and
, and
 , adjacent to each other. If we have a request (s, t) that lands on the right edge of
, and assuming the filter kernel is sufficiently large, as can happen in lower-resolution mipmap levels, then a
correct filtering should involve a majority of the tile
. Unfortunately, because we always perform filtering in the input packing, the filtering would involve a
majority of
, adjacent to each other. If we have a request (s, t) that lands on the right edge of
, and assuming the filter kernel is sufficiently large, as can happen in lower-resolution mipmap levels, then a
correct filtering should involve a majority of the tile
. Unfortunately, because we always perform filtering in the input packing, the filtering would involve a
majority of
 instead, and this is obviously incorrect. A more serious problem occurs when the filter footprint just crosses
the boundary between
and
. In this case, the filtering result would change discontinuously in the input, with an abrupt switch from
filtering tiles
and
to
instead, and this is obviously incorrect. A more serious problem occurs when the filter footprint just crosses
the boundary between
and
. In this case, the filtering result would change discontinuously in the input, with an abrupt switch from
filtering tiles
and
to
 and
. And this artifact could exhibit itself both spatially and temporally.
and
. And this artifact could exhibit itself both spatially and temporally.
){kind=link}
To remove these artifacts, we have to sanitize the tiles at all lower-resolution mipmap levels to ensure that they are legal Wang tiles. We achieve this by averaging all tile edges with the same color ID across all tiles. This does not produce a theoretically correct result (unless you store the entire lower-resolution mipmap levels for the output), but it at least eliminates popping visual artifacts. An implementation of this algorithm is available on the accompanying CD.
Figure 12-6 demonstrates the sanitization effects on the rendering. Without tile correction, the rendering would contain noticeable discontinuity, as shown in case (a). With correction on tile edges, the results look much better, as shown in case (b). A more correct approach would be to sanitize both edges and corners, but we have found that this usually produces over-blurry results, as case (c) demonstrates. In our experience, because most textures are homogeneous at lower mipmap resolutions, it is usually sufficient to sanitize edges only.

Figure 12-6 Filtering Results at Lower-Resolution Mipmap Levels
12.6 Conclusion
We have presented a tile-based texture-mapping system that generates a large virtual texture from a small set of tiles. We have described a Cg program implementation that does not require changing geometry or texture coordinates in the application. Our implementation requires two texture reads to emulate one large virtual texture, and is roughly 50 to 25 percent slower than a single-texture program (as measured on a GeForce 6800 GT, depending on various factors such as filtering mode and original program complexity). However, the speed is still fast enough for most applications, and the savings in texture memory is substantial. There are quality limitations of our approach at lower-resolution mipmap levels, but as long as the tile set is built correctly, the result looks reasonable despite being theoretically incorrect.
12.7 References
Cohen, Michael F., Jonathan Shade, Stefan Hiller, and Oliver Deussen. 2003. "Wang Tiles for Image and Texture Generation." ACM Transactions on Graphics (Proceedings of SIGGRAPH 2003) 22(3), pp. 287–294.
Glanville, R. Steven. 2004. "Texture Bombing." In GPU Gems, edited by Randima Fernando, pp. 323–338. Addison-Wesley.
Lefebvre, Sylvain, and Fabrice Neyret. 2003. "Pattern Based Procedural Textures." In Proceedings of SIGGRAPH 2003 Symposium on Interactive 3D Graphics, pp. 203–212.
Losasso, Frank, and Hugues Hoppe. 2004. "Geometry Clipmaps: Terrain Rendering Using Nested Regular Grids." ACM Transactions on Graphics (Proceedings of ACM SIGGRAPH 2004) 23(3), pp. 769–776.
Tanner, Christopher, Christopher Migdal, and Michael Jones. 1998. "The Clipmap: A Virtual Mipmap." In Proceedings of SIGGRAPH 98, pp. 151–158.
Wei, Li-Yi. 2004. "Tile-Based Texture Mapping on Graphics Hardware." In Proceedings of Graphics Hardware 2004, pp. 55–63.
I would like to thank the people who helped me in my original paper (Wei 2004), Hugues Hoppe for pointing out the mipmap issue, Shaun Ho for recommending the submission of this technique for this book, and my NVIDIA colleagues for their help and support.
Copyright
Many of the designations used by manufacturers and sellers to distinguish their products are claimed as trademarks. Where those designations appear in this book, and Addison-Wesley was aware of a trademark claim, the designations have been printed with initial capital letters or in all capitals.
The authors and publisher have taken care in the preparation of this book, but make no expressed or implied warranty of any kind and assume no responsibility for errors or omissions. No liability is assumed for incidental or consequential damages in connection with or arising out of the use of the information or programs contained herein.
NVIDIA makes no warranty or representation that the techniques described herein are free from any Intellectual Property claims. The reader assumes all risk of any such claims based on his or her use of these techniques.
The publisher offers excellent discounts on this book when ordered in quantity for bulk purchases or special sales, which may include electronic versions and/or custom covers and content particular to your business, training goals, marketing focus, and branding interests. For more information, please contact:
U.S. Corporate and Government Sales
(800) 382-3419
corpsales@pearsontechgroup.com
For sales outside of the U.S., please contact:
International Sales
international@pearsoned.com
Visit Addison-Wesley on the Web: www.awprofessional.com
Library of Congress Cataloging-in-Publication Data
GPU gems 2 : programming techniques for high-performance graphics and general-purpose
computation / edited by Matt Pharr ; Randima Fernando, series editor.
p. cm.
Includes bibliographical references and index.
ISBN 0-321-33559-7 (hardcover : alk. paper)
1. Computer graphics. 2. Real-time programming. I. Pharr, Matt. II. Fernando, Randima.
T385.G688 2005
006.66—dc22
2004030181
GeForce™ and NVIDIA Quadro® are trademarks or registered trademarks of NVIDIA Corporation.
Nalu, Timbury, and Clear Sailing images © 2004 NVIDIA Corporation.
mental images and mental ray are trademarks or registered trademarks of mental images, GmbH.
Copyright © 2005 by NVIDIA Corporation.
All rights reserved. No part of this publication may be reproduced, stored in a retrieval system, or transmitted, in any form, or by any means, electronic, mechanical, photocopying, recording, or otherwise, without the prior consent of the publisher. Printed in the United States of America. Published simultaneously in Canada.
For information on obtaining permission for use of material from this work, please submit a written request to:
Pearson Education, Inc.
Rights and Contracts Department
One Lake Street
Upper Saddle River, NJ 07458
Text printed in the United States on recycled paper at Quebecor World Taunton in Taunton, Massachusetts.
Second printing, April 2005
Dedication
To everyone striving to make today's best computer graphics look primitive tomorrow
- Copyright
- Inside Back Cover
- Inside Front Cover
- Part I: Geometric Complexity
-
- Chapter 1. Toward Photorealism in Virtual Botany
- Chapter 2. Terrain Rendering Using GPU-Based Geometry Clipmaps
- Chapter 3. Inside Geometry Instancing
- Chapter 4. Segment Buffering
- Chapter 5. Optimizing Resource Management with Multistreaming
- Chapter 6. Hardware Occlusion Queries Made Useful
- Chapter 7. Adaptive Tessellation of Subdivision Surfaces with Displacement Mapping
- Chapter 8. Per-Pixel Displacement Mapping with Distance Functions
- Part II: Shading, Lighting, and Shadows
-
- Chapter 9. Deferred Shading in S.T.A.L.K.E.R.
- Chapter 10. Real-Time Computation of Dynamic Irradiance Environment Maps
- Chapter 11. Approximate Bidirectional Texture Functions
- Chapter 12. Tile-Based Texture Mapping
- Chapter 13. Implementing the mental images Phenomena Renderer on the GPU
- Chapter 14. Dynamic Ambient Occlusion and Indirect Lighting
- Chapter 15. Blueprint Rendering and "Sketchy Drawings"
- Chapter 16. Accurate Atmospheric Scattering
- Chapter 17. Efficient Soft-Edged Shadows Using Pixel Shader Branching
- Chapter 18. Using Vertex Texture Displacement for Realistic Water Rendering
- Chapter 19. Generic Refraction Simulation
- Part III: High-Quality Rendering
-
- Chapter 20. Fast Third-Order Texture Filtering
- Chapter 21. High-Quality Antialiased Rasterization
- Chapter 22. Fast Prefiltered Lines
- Chapter 23. Hair Animation and Rendering in the Nalu Demo
- Chapter 24. Using Lookup Tables to Accelerate Color Transformations
- Chapter 25. GPU Image Processing in Apple's Motion
- Chapter 26. Implementing Improved Perlin Noise
- Chapter 27. Advanced High-Quality Filtering
- Chapter 28. Mipmap-Level Measurement
- Part IV: General-Purpose Computation on GPUS: A Primer
-
- Chapter 29. Streaming Architectures and Technology Trends
- Chapter 30. The GeForce 6 Series GPU Architecture
- Chapter 31. Mapping Computational Concepts to GPUs
- Chapter 32. Taking the Plunge into GPU Computing
- Chapter 33. Implementing Efficient Parallel Data Structures on GPUs
- Chapter 34. GPU Flow-Control Idioms
- Chapter 35. GPU Program Optimization
- Chapter 36. Stream Reduction Operations for GPGPU Applications
- Part V: Image-Oriented Computing
-
- Chapter 37. Octree Textures on the GPU
- Chapter 38. High-Quality Global Illumination Rendering Using Rasterization
- Chapter 39. Global Illumination Using Progressive Refinement Radiosity
- Chapter 40. Computer Vision on the GPU
- Chapter 41. Deferred Filtering: Rendering from Difficult Data Formats
- Chapter 42. Conservative Rasterization
- Part VI: Simulation and Numerical Algorithms
-
- Chapter 43. GPU Computing for Protein Structure Prediction
- Chapter 44. A GPU Framework for Solving Systems of Linear Equations
- Chapter 45. Options Pricing on the GPU
- Chapter 46. Improved GPU Sorting
- Chapter 47. Flow Simulation with Complex Boundaries
- Chapter 48. Medical Image Reconstruction with the FFT