
GPU Gems 2
GPU Gems 2 is now available, right here, online. You can purchase a beautifully printed version of this book, and others in the series, at a 30% discount courtesy of InformIT and Addison-Wesley.
The CD content, including demos and content, is available on the web and for download.
Chapter 3. Inside Geometry Instancing
Francesco Carucci
Lionhead Studios
A great way to enrich the user experience in an interactive application is to present a credible world, full of small, interesting features and objects. From countless blades of grass, to trees, to generic clutter: it all improves the final perception and helps maintain the user's "suspension of disbelief." If the user can believe the world he is immersed in, he is more likely to be emotionally connected to that world—the Holy Grail of game development.
From a rendering point of view, achieving this richness translates into rendering many small objects, often each one similar to the next, with only small differences such as color, position, and orientation. For example, every tree in a big forest might be geometrically very similar, but all may be different in terms of their color or height. The user perceives a forest made of many unique trees and believes the world to be credible, enriching his or her game experience.
However, rendering a large number of small objects, each made from a few polygons, imposes a big strain on today's GPUs and rendering libraries. Graphics APIs such as Direct3D and OpenGL are not designed to efficiently render a small number of polygons thousands of times per frame (Wloka 2003).
This chapter addresses the problem of rendering many unique instances of the same geometry in Direct3D. Figure 3-1 shows an example from Black & White 2, a game in development at Lionhead Studios.

Figure 3-1 Geometry Instancing in Black & White 2
3.1 Why Geometry Instancing?
Submitting triangles to the GPU for rendering in Direct3D is a relatively slow operation. Wloka 2003 shows that a 1 GHz CPU can render only around 10,000 to 40,000 batches per second in Direct3D. On a more modern CPU, we can expect this number to be between 30,000 and 120,000 batches per second (around 1,000 to 4,000 batches per frame at 30 frames/sec). That's not much! It means that if we want to render a forest of trees, and we submit one tree per batch, we cannot render more than 4,000 trees, regardless of how many polygons are in a tree—with no CPU time left for the rest of the game. This situation is clearly not ideal. We would like to be able to minimize the number of state and texture changes in our application and render the same triangles multiple times within the same batch in a single call to Direct3D. Thus, we would minimize CPU time spent in submitting batches and free up that time for other systems, such as physics, artificial intelligence, and game logic.
3.2 Definitions
We first define concepts behind geometry instancing, to make clear the kinds of objects that are part of the problem.
3.2.1 Geometry Packet
A geometry packet is a description of a packet of geometry to be instanced, a collection of vertices and indices. A geometry packet can be described in terms of vertices—with position, texture coordinates, normal, possibly tangent space and bones information for skinning, and per-vertex colors—and in terms of indices into the vertex stream. This kind of description directly maps to the most efficient way to submit geometry to the GPU.
A geometry packet is an abstract description of a piece of geometry, where the geometric entities are expressed in model space without any explicit reference to the context in which they will be rendered.
Here's a possible description in code of a geometry packet; it includes both the geometric information for the object as well as its bounding sphere:
struct GeometryPacket
{
Primitive mPrimType void *mVertices;
unsigned int mVertexStride;
unsigned short *mIndices;
unsigned int mVertexCount;
unsigned int mIndexCount;
D3DXVECTOR3 mSphereCentre;
float mSphereRadius;
};3.2.2 Instance Attributes
Typical attributes per instance are the model-to-world transformation matrix, the instance color, and an animation player providing the bones used to skin the geometry packet.
struct InstanceAttributes
{
D3DXMATRIX mModelMatrix;
D3DCOLOR mInstanceColor;
AnimationPlayer *mAnimationPlayer;
unsigned int mLOD;
};3.2.3 Geometry Instance
A geometry instance is a geometry packet with the attributes specific to the instance. It directly connects a geometry packet and the instance attributes packet with which it's going to be rendered, giving an almost complete description of the entity ready to be submitted to the GPU.
Here's how a geometry instance structure might look in code:
struct GeometryInstance
{
GeometryPacket *mGeometryPacket;
InstanceAttributes mInstanceAttributes;
};3.2.4 Render and Texture Context
The render context is the current state of the GPU in terms of render states (such as alpha blending and testing states, active render target, and more). The texture context tracks the currently active textures. Render context and texture context are usually modeled with classes, as shown in Listing 3-1.
3.2.5 Geometry Batch
A batch is a collection of geometry instances and the render states and texture context to be used to render the collection. It always directly maps to a single DrawIndexedPrimitive() call, to simplify the design of the class.
Listing 3-2 is an abstract interface for a geometry batch class.
Example 3-1. Render and Texture Context Classes
class RenderContext
{
public:
// Begin the render context and make its render state active
//
void Begin(void);
// End the render context and restore previous render state,
// if necessary
//
void End(void);
private:
// Any description of the current render state and pixel
// and vertex shaders.
// D3DX Effect framework is particularly useful.
//
ID3DXEffect *mEffect;
// Application-specific render states
// . . .
};
class TextureContext
{
public:
// Set current textures to the appropriate texture stages
//
void Apply(void) const;
private:
Texture mDiffuseMap;
Texture mLightMap;
// . . .
};Example 3-2. GeometryBatch Class
class GeometryBatch
{
public:
// Remove all instances from the geometry batch
//
virtual void ClearInstances(void);
// Add an instance to the collection and return its ID.
// Return -1 if it can't accept more instances.
//
virtual int AddInstance(GeometryInstance *instance);
// Commit all instances, to be called once before the
// render loop begins and after every change to the
// instances collection
//
virtual unsigned int Commit(void) = 0;
// Update the geometry batch, eventually prepare GPU-specific
// data ready to be submitted to the driver, fill vertex and
// index buffers as necessary, to be called once per frame
//
virtual void Update(void) = 0;
// Submit the batch to the driver, typically implemented
// with a call to DrawIndexedPrimitive
//
virtual void Render(void) const = 0;
private:
GeometryInstancesCollection mInstances;
// . . .
};3.3 Implementation
The engine's renderer can see geometry instancing only in terms of the abstract interface of a GeometryBatch, which hides the specifics of the instancing implementation and provides services for managing instances, updating, and rendering a batch. This way, the engine can concentrate on sorting batches to minimize render state and texture changes, while the GeometryBatch takes care of the actual implementation and communication protocol with Direct3D.
Listing 3-3 shows a simple implementation of a render loop in pseudocode, sorting GeometryBatches first by render context and then by texture context, thus minimizing the number of render-state changes.
Example 3-3. Render Loop in Pseudocode
// Update phase
Foreach GeometryBatch in ActiveBatchesList GeometryBatch.Update();
// Render phase
Foreach RenderContext Begin RenderContext.BeginRendering();
RenderContext.CommitStates();
Foreach TextureContext Begin TextureContext.Apply();
Foreach GeometryBatch in the texture context GeometryBatch.Render();
End EndThe update and render phases can be kept separate in case we want to update all batches once and render several times: this idea is extremely useful when implementing shadow mapping or water reflection and refraction, for example.
In this chapter, we discuss four implementations of GeometryBatch and analyze their performance characteristics, with a particular interest in the memory footprint and flexibility of each technique.
Here's a brief summary:
- Static batching. The fastest way to instance geometry. Each instance is transformed once to world space, its attributes are applied, and then it's sent already transformed to the GPU with every frame. Although simple, static batching is the least flexible technique.
- Dynamic batching. The slowest way to instance geometry. Each instance is streamed to GPU memory every frame, already transformed and with attributes applied. Dynamic batching seamlessly supports skinning and provides the most flexible implementation.
- Vertex constants instancing. A hybrid implementation in which multiple copies of the geometry for each instance are copied once into GPU memory. Instance attributes are then set every frame through vertex constants, and a vertex shader completes geometry instancing.
- Batching with Geometry Instancing API. Using the Geometry Instancing API provided by DirectX 9 and fully supported in hardware by GeForce 6 Series GPUs, this implementation offers a flexible and fast solution to geometry instancing. Unlike all other methods, this does not require geometry packet replication in the Direct3D vertex stream.
3.3.1 Static Batching
In static batching, we want to transform all instances once and copy them to a static vertex buffer. The most noticeable advantages of static batching are its rendering efficiency and its compatibility with any GPU on the market, regardless of age.
To implement static batching, we first create a vertex buffer object (with its associated index buffer) to fill with the transformed geometry. This object must be big enough to accept the maximum number of instances we decide to handle. Because we fill the buffer once and never touch it again, we can create it with the D3USAGE_WRITEONLY flag, giving a useful hint to the driver to put the buffer in the fastest memory available:
HRESULT res;
res = lpDevice->CreateVertexBuffer(MAX_STATIC_BUFFER_SIZE, D3DUSAGE_WRITEONLY,
0, D3DPOOL_MANAGED, &mStaticVertexStream, 0);
ENGINE_ASSERT(SUCCEEDED(res));Whether to choose D3DPOOL_MANAGED or D3DPOOL_DEFAULT to create the buffer depends on the particular application and especially on the memory management strategy of the engine.
The next step is to implement the Commit() method to actually fill the vertex and index buffers with the transformed geometry that needs to be rendered.
Here is the Commit() method in pseudocode:
Foreach
GeometryInstance in Instances Begin Transform geometry in mGeometryPacket to
world space with instance mModelMatrix Apply other instance
attributes(like instance color) Copy
transformed geometry to the Vertex Buffer Copy
indices(with the right offset) to the Index Buffer Advance current pointer
to the Vertex Buffer Advance current pointer to the Index Buffer EndFrom now on, it's just a matter of submitting the instances we have already prepared with a simple call to DrawIndexedPrimitive(). The actual implementation of the Update() and Render() methods is trivial.
Static batching is the fastest way to render many instances, and it supports instances of different geometry packets inside the same geometry batch, but it has a few serious limitations:
- Large memory footprint. Depending on the size of each geometry packet and the number of instances being rendered, the memory footprint might become too big; for large worlds, it's easy to spend the video memory budget reserved for geometry. Falling back to AGP memory is possible, but that makes this technique slower and thus less appealing.
- No support for different levels of detail. Because all instances are copied once into the vertex buffer at commit time, choosing a level of detail valid for all situations is not easy and leads to suboptimal usage of the polygon budget. A semi-static solution is possible, in which all the levels of detail of a particular instance are instanced in the vertex buffer, while indices are streamed every frame, picking up the right level of detail for each instance. But this makes the implementation clumsier, defeating the purpose of this solution: simplicity and efficiency.
- No support for skinning.
- No direct support for moving instances. Implementing moving instances requires vertex shader logic with dynamic branching in order to be efficient. This can be prohibitive on older graphics cards. The end result would essentially be vertex constants instancing.
These limitations are addressed with the next technique, trading off rendering speed for additional flexibility.
3.3.2 Dynamic Batching
Dynamic batching overcomes the limitations of static batching at the cost of reducing rendering efficiency. A major advantage of dynamic batching is, like static batching, that it can be implemented on any GPU without support for advanced programmable pipelines.
The first step is to create a vertex buffer (and its associated index buffer) as dynamic by using the D3DUSAGE_DYNAMIC and D3DPOOL_DEFAULT flags. These flags ensure that the buffer is placed in the best possible memory location, given that we intend to dynamically update its contents.
HRESULT res;
res = lpDevice->CreateVertexBuffer(MAX_DYNAMIC_BUFFER_SIZE,
D3DUSAGE_DYNAMIC | D3DUSAGE_WRITEONLY, 0,
D3DPOOL_DEFAULT, &mDynamicVertexStream, 0);Choosing the right value for MAX_DYNAMIC_BUFFER_SIZE is vital in this implementation. Two choices dictating the actual value are possible:
- Choosing a value large enough to contain geometry for all instances that might be needed in a frame
- Choosing a value large enough to contain geometry for a certain number of instances
The first approach ensures a proper separation between updating and rendering a batch. Updating a batch means streaming all instances into the dynamic buffer; rendering just submits the geometry with a call to DrawIndexedPrimitive(). But this approach typically requires a large amount of graphics memory (that is, either video or AGP memory) and is less reliable in the worst case if we can't ensure that the buffer is always big enough during the life of the application.
The second solution requires interleaving between streaming geometry and rendering it: when the dynamic buffer is full, its geometry is submitted for rendering and the content of the buffer is discarded, ready for more instances to be streamed. For optimal performance, it is important to use the proper protocol, that is, locking the dynamic buffer with D3DLOCK_DISCARD at the beginning of a new batch of instances and with D3DLOCK_WRITEONLY for each new instance to be streamed. The drawback of this solution is that it requires locking the buffer and streaming geometry again each time the batch needs to be rendered, for example, when implementing shadow mapping.
The choice depends on the particular application and its requirements. In this chapter, we choose the first solution, for its simplicity and clarity, but we add a slight complication: dynamic batching naturally supports skinning, and we address this in our implementation.
The Update() method is very similar to the Commit() method we have already described in Section 3.3.1, but it is executed every frame. Here it is in pseudocode:
Foreach
GeometryInstance in Instances Begin Transform geometry in mGeometryPacket to
world space with instance mModelMatrix If instance needs skinning,
request a set of bones from mAnimationPlayer and
skin geometry Apply other instance
attributes(like instance color) Copy
transformed geometry to the Vertex Buffer Copy
indices(with the right offset) to the Index Buffer Advance current pointer
to the Vertex Buffer Advance current pointer to the Index Buffer EndIn this case, the Render() method is a trivial call to DrawIndexedPrimitive().
3.3.3 Vertex Constants Instancing
In vertex constants instancing, we take advantage of vertex constants to store instancing attributes. Vertex constants batching is very fast in terms of rendering performance, and it supports instances moving from frame to frame, but it pays in terms of flexibility.
The main limitations are these:
- Limited number of instances per batch, depending on the number of constants available; usually no more than 50 to 100 instances can be batched in a single call. However, this can be enough to significantly reduce the CPU load from draw calls.
- No skinning; vertex constants are already used to store instance attributes.
- Need graphics hardware support for vertex shaders.
The first step is to prepare a static vertex buffer (with its associated index buffer) to store multiple copies of the same geometry packets, stored in model space, one for each instance in the batch.
The vertex buffer layout is illustrated in Figure 3-2.
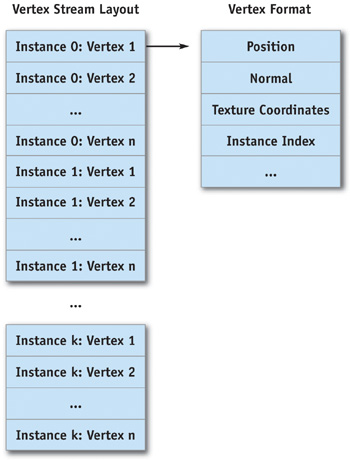
Figure 3-2 Vertex Buffer Layout
The source vertex format must be updated to add an integer index to each vertex, which is constant per instance, indicating which instance the geometry packet belongs to. This is similar to palette skinning, in which each vertex contains an index to the bone (or multiple bones) affecting it.
The updated vertex format is this:
struct InstanceVertex
{
D3DXVECTOR3
mPosition;
// Other vertex properties, such as normal and texture
// coordinates
WORD mInstanceIndex[4]; // Direct3D requires SHORT4
};The Commit() method prepares the vertex buffer with the proper layout after all instances have been added to the geometry batch.
The next step is to upload attributes for each instance being rendered. Suppose we have only the model matrix, describing instance position and orientation, and the instance color.
When using a DirectX 9-class GPU, we can use a maximum of 256 vertex constants; we can reserve 200 for instancing attributes. In our example, each instance requires 4 constants for the model matrix and 1 constant for instance color, for a total of 5 constants per instance, leading to a maximum of 40 instances per batch.
Listing 3-4 shows the Update() method. The actual instancing is done in the vertex shader, shown in Listing 3-5.
Example 3-4. The Update() Method
D3DXVECTOR4 instancesData[MAX_NUMBER_OF_CONSTANTS];
unsigned int count = 0;
for (unsigned int i = 0; i < GetInstancesCount(); ++i)
{
// write model matrix
instancesData[count++] = *(D3DXVECTOR4 *)&mInstances[i].mModelMatrix.m11;
instancesData[count++] = *(D3DXVECTOR4 *)&mInstances[i].mModelMatrix.m21;
instancesData[count++] = *(D3DXVECTOR4 *)&mInstances[i].mModelMatrix.m31;
instancesData[count++] = *(D3DXVECTOR4 *)&mInstances[i].mModelMatrix.m41;
// write instance color
instanceData[count++] = ConvertColorToVec4(mInstances[i].mColor));
}
lpDevice->SetVertexConstants(INSTANCES_DATA_FIRST_CONSTANT, instancesData,
count);Example 3-5. Vertex Shader for Vertex Constants Instancing
// vertex input declaration
struct vsInput
{
float4 position : POSITION;
float3 normal : NORMAL;
// other vertex data
int4 instance_index : BLENDINDICES;
};
vsOutput VertexConstantsInstancingVS(in vsInput input)
{
// get the instance index; the index is premultiplied
// by 5 to take account of the number of constants
// used by each instance
int instanceIndex = ((int[4])(input.instance_index))[0];
// access each row of the instance model matrix
float4 m0 = InstanceData[instanceIndex + 0];
float4 m1 = InstanceData[instanceIndex + 1];
float4 m2 = InstanceData[instanceIndex + 2];
float4 m3 = InstanceData[instanceIndex + 3];
// construct the model matrix
float4x4 modelMatrix = {m0, m1, m2, m3};
// get the instance color
float4 instanceColor = InstanceData[instanceIndex + 4];
// transform input position and normal to world space with
// the instance model matrix
float4 worldPosition = mul(input.position, modelMatrix);
float3 worldNormal = mul(input.normal, modelMatrix);
// output position, normal, and color
output.position = mul(worldPosition, ViewProjectionMatrix);
output.normal = mul(worldNormal, ViewProjectionMatrix);
output.color = instanceColor;
// output other vertex data
}The Render() sets the view projection matrix and submits all instances with a DrawIndexedPrimitive() call.
A possible optimization in production code is to store the rotational part of the model matrix as a quaternion, saving two vertex constants and increasing the maximum number of instances to around 70. A uniform scaling value can be stored in the w component of the translation vector. The model matrix is then reconstructed in the vertex shader, increasing its complexity and execution time.
3.3.4 Batching with the Geometry Instancing API
The last technique we present in this chapter is batching with the Geometry Instancing API exposed by DirectX 9 and fully implemented in hardware on GeForce 6 Series GPUs. As more hardware starts supporting the Geometry Instancing API, this technique will become more interesting, because it elegantly solves limitations imposed by vertex constants instancing, has a very limited memory footprint, and requires little intervention by the CPU. The only drawback of this technique is that it can only handle instances of the same geometry packet.
DirectX 9 provides the following call to access the Geometry Instancing API:
HRESULT SetStreamSourceFreq(UINT StreamNumber, UINT FrequencyParameter);StreamNumber is the index of the source stream and FrequencyParameter indicates the number of instances each vertex contains.
We first create two vertex buffers: a static one to store geometry for the single geometry packet we want to instance multiple times, and a dynamic one to store instance data. The two vertex streams are shown in Figure 3-3.
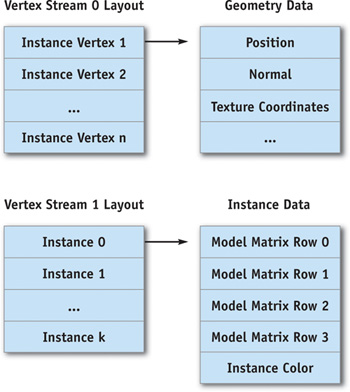
Figure 3-3 Vertex Streams for Instancing with the Geometry Instancing API
The Commit() method ensures that all instances are using only one geometry packet and copies its geometry to the static buffer.
The Update() method simply copies all instance attributes into the second stream. Even though this method looks very similar to the Update() method of a dynamic batch, CPU intervention and graphics bus (AGP or PCI Express) bandwidth are minimal. Moreover, we can choose to allocate a vertex buffer big enough to accept attributes for all instances without worrying about graphics memory consumption, because each instance attribute uses only a fraction of the memory consumed by a whole geometry packet.
The Render() method sets up two streams with the correct stream frequency and issues a DrawIndexedPrimitive() call to render all instances in one batch, as shown in Listing 3-6.
The GPU takes care of virtually duplicating vertices of the first stream and packing them together with the second stream. The vertex shader sees as input a vertex with its position in model space and an additional instance attribute giving the model matrix to transform it to world space.
Example 3-6. Setting Up Two Streams for Batching with the Geometry Instancing API
unsigned int instancesCount = GetInstancesCount();
// set up stream source frequency for the first stream
// to render instancesCount instances
// D3DSTREAMSOURCE_INDEXEDDATA tells Direct3D we'll use
// indexed geometry for instancing
lpDevice->SetStreamSourceFreq(0, D3DSTREAMSOURCE_INDEXEDDATA | instancesCount);
// set up first stream source with the vertex buffer
// containing geometry for the geometry packet
lpDevice->SetStreamSource(0, mGeometryInstancingVB[0], 0, mGeometryPacketDecl);
// set up stream source frequency for the second stream;
// each set of instance attributes describes one instance
// to be rendered
lpDevice->SetStreamSourceFreq(1, D3DSTREAMSOURCE_INSTANCEDATA | 1);
// set up second stream source with the vertex buffer
// containing all instances' attributes
pd3dDevice->SetStreamSource(1, mGeometryInstancingVB[0], 0,
mInstancesDataVertexDecl);The vertex shader code appears in Listing 3-7.
Example 3-7. Vertex Shader for Batching with the Geometry Instancing API
// vertex input declaration
struct vsInput
{
// stream 0
float4 position : POSITION;
float3 normal : NORMAL;
// stream 1
float4 model_matrix0 : TEXCOORD0;
float4 model_matrix1 : TEXCOORD1;
float4 model_matrix2 : TEXCOORD2;
float4 model_matrix3 : TEXCOORD3;
float4 instance_color : D3DCOLOR;
};
vsOutput GeometryInstancingVS(in vsInput input)
{
// construct the model matrix
float4x4 modelMatrix = {input.model_matrix0, input.model_matrix1,
input.model_matrix2, input.model_matrix3};
// transform input position and normal to world space
// with the instance model matrix
float4 worldPosition = mul(input.position, modelMatrix);
float3 worldNormal = mul(input.normal, modelMatrix);
// output position, normal, and color
output.position = mul(worldPosition, ViewProjectionMatrix);
output.normal = mul(worldNormal, ViewProjectionMatrix);
output.color = input.instance_color;
// output other vertex data
}With minimal CPU overhead and memory footprint, this technique can efficiently render many copies of the same geometry and is therefore the ideal solution in many scenarios. The only drawback is that it requires special hardware capabilities and doesn't easily support skinning.
To implement skinning, it would be possible to store all bones for all instances into a texture and fetch the right bones of the right instance with the texture fetch available in Shader Model 3.0 (which is required by the Geometry Instancing API). If this solution seems attractive, the performance impact of using texture fetches with this kind of access pattern is uncertain and should be tested.
3.4 Conclusion
This chapter defined the concepts behind geometry instancing and described four different techniques to achieve the goal of efficiently rendering the same geometry multiple times. Each technique has pros and cons, and no single technique clearly represents the ideal choice for every scenario. The best choice depends mainly on the application and on the type of objects being rendered.
Some scenarios and proposed solutions:
- An indoor scene with many static instances of the same geometry, which rarely or never move (such as walls or furniture). This is an ideal case for static batching.
- An outdoor scene with many instances of animated objects, as in a strategy game with big battles involving hundreds of soldiers. In this scenario, dynamic batching is probably the best solution.
- An outdoor scene with lots of vegetation and trees, many of which tend to modify their attributes (for example, trees and grass swaying in the wind), and lots of particle systems. This is probably the best scenario for the Geometry Instancing API.
Often the same application needs to rely on two or more techniques. Figures 3-4 and 3-5 show two examples. In such cases, hiding the implementation behind an abstract geometry batch concept makes the engine more modular and easier to maintain. As a result, the costs of implementing all the geometry-instancing techniques are greatly reduced for the entire application.

Figure 3-4 Combining Static Batching and Geometry Instancing in a Real Scene

Figure 3-5 Combining GPU and CPU Animation in a Real Scene
3.5 References
Cebenoyan, Cem. 2004. "Graphics Pipeline Performance." In GPU Gems, edited by Randima Fernando, pp. 473–486. Addison-Wesley. Available online at http://developer.nvidia.com/object/GPU_Gems_Samples.html
O'Rorke, John. 2004. "Managing Visibility for Per-Pixel Lighting." In GPU Gems, edited by Randima Fernando, pp. 245–257. Addison-Wesley.
Wloka, Matthias. 2003. "Batch, Batch, Batch: What Does It Really Mean?" Presentation at Game Developers Conference 2003. http://developer.nvidia.com/docs/IO/8230/BatchBatchBatch.pdf
Copyright
Many of the designations used by manufacturers and sellers to distinguish their products are claimed as trademarks. Where those designations appear in this book, and Addison-Wesley was aware of a trademark claim, the designations have been printed with initial capital letters or in all capitals.
The authors and publisher have taken care in the preparation of this book, but make no expressed or implied warranty of any kind and assume no responsibility for errors or omissions. No liability is assumed for incidental or consequential damages in connection with or arising out of the use of the information or programs contained herein.
NVIDIA makes no warranty or representation that the techniques described herein are free from any Intellectual Property claims. The reader assumes all risk of any such claims based on his or her use of these techniques.
The publisher offers excellent discounts on this book when ordered in quantity for bulk purchases or special sales, which may include electronic versions and/or custom covers and content particular to your business, training goals, marketing focus, and branding interests. For more information, please contact:
U.S. Corporate and Government Sales
(800) 382-3419
corpsales@pearsontechgroup.com
For sales outside of the U.S., please contact:
International Sales
international@pearsoned.com
Visit Addison-Wesley on the Web: www.awprofessional.com
Library of Congress Cataloging-in-Publication Data
GPU gems 2 : programming techniques for high-performance graphics and general-purpose
computation / edited by Matt Pharr ; Randima Fernando, series editor.
p. cm.
Includes bibliographical references and index.
ISBN 0-321-33559-7 (hardcover : alk. paper)
1. Computer graphics. 2. Real-time programming. I. Pharr, Matt. II. Fernando, Randima.
T385.G688 2005
006.66—dc22
2004030181
GeForce™ and NVIDIA Quadro® are trademarks or registered trademarks of NVIDIA Corporation.
Nalu, Timbury, and Clear Sailing images © 2004 NVIDIA Corporation.
mental images and mental ray are trademarks or registered trademarks of mental images, GmbH.
Copyright © 2005 by NVIDIA Corporation.
All rights reserved. No part of this publication may be reproduced, stored in a retrieval system, or transmitted, in any form, or by any means, electronic, mechanical, photocopying, recording, or otherwise, without the prior consent of the publisher. Printed in the United States of America. Published simultaneously in Canada.
For information on obtaining permission for use of material from this work, please submit a written request to:
Pearson Education, Inc.
Rights and Contracts Department
One Lake Street
Upper Saddle River, NJ 07458
Text printed in the United States on recycled paper at Quebecor World Taunton in Taunton, Massachusetts.
Second printing, April 2005
Dedication
To everyone striving to make today's best computer graphics look primitive tomorrow
- Copyright
- Inside Back Cover
- Inside Front Cover
- Part I: Geometric Complexity
-
- Chapter 1. Toward Photorealism in Virtual Botany
- Chapter 2. Terrain Rendering Using GPU-Based Geometry Clipmaps
- Chapter 3. Inside Geometry Instancing
- Chapter 4. Segment Buffering
- Chapter 5. Optimizing Resource Management with Multistreaming
- Chapter 6. Hardware Occlusion Queries Made Useful
- Chapter 7. Adaptive Tessellation of Subdivision Surfaces with Displacement Mapping
- Chapter 8. Per-Pixel Displacement Mapping with Distance Functions
- Part II: Shading, Lighting, and Shadows
-
- Chapter 9. Deferred Shading in S.T.A.L.K.E.R.
- Chapter 10. Real-Time Computation of Dynamic Irradiance Environment Maps
- Chapter 11. Approximate Bidirectional Texture Functions
- Chapter 12. Tile-Based Texture Mapping
- Chapter 13. Implementing the mental images Phenomena Renderer on the GPU
- Chapter 14. Dynamic Ambient Occlusion and Indirect Lighting
- Chapter 15. Blueprint Rendering and "Sketchy Drawings"
- Chapter 16. Accurate Atmospheric Scattering
- Chapter 17. Efficient Soft-Edged Shadows Using Pixel Shader Branching
- Chapter 18. Using Vertex Texture Displacement for Realistic Water Rendering
- Chapter 19. Generic Refraction Simulation
- Part III: High-Quality Rendering
-
- Chapter 20. Fast Third-Order Texture Filtering
- Chapter 21. High-Quality Antialiased Rasterization
- Chapter 22. Fast Prefiltered Lines
- Chapter 23. Hair Animation and Rendering in the Nalu Demo
- Chapter 24. Using Lookup Tables to Accelerate Color Transformations
- Chapter 25. GPU Image Processing in Apple's Motion
- Chapter 26. Implementing Improved Perlin Noise
- Chapter 27. Advanced High-Quality Filtering
- Chapter 28. Mipmap-Level Measurement
- Part IV: General-Purpose Computation on GPUS: A Primer
-
- Chapter 29. Streaming Architectures and Technology Trends
- Chapter 30. The GeForce 6 Series GPU Architecture
- Chapter 31. Mapping Computational Concepts to GPUs
- Chapter 32. Taking the Plunge into GPU Computing
- Chapter 33. Implementing Efficient Parallel Data Structures on GPUs
- Chapter 34. GPU Flow-Control Idioms
- Chapter 35. GPU Program Optimization
- Chapter 36. Stream Reduction Operations for GPGPU Applications
- Part V: Image-Oriented Computing
-
- Chapter 37. Octree Textures on the GPU
- Chapter 38. High-Quality Global Illumination Rendering Using Rasterization
- Chapter 39. Global Illumination Using Progressive Refinement Radiosity
- Chapter 40. Computer Vision on the GPU
- Chapter 41. Deferred Filtering: Rendering from Difficult Data Formats
- Chapter 42. Conservative Rasterization
- Part VI: Simulation and Numerical Algorithms
-
- Chapter 43. GPU Computing for Protein Structure Prediction
- Chapter 44. A GPU Framework for Solving Systems of Linear Equations
- Chapter 45. Options Pricing on the GPU
- Chapter 46. Improved GPU Sorting
- Chapter 47. Flow Simulation with Complex Boundaries
- Chapter 48. Medical Image Reconstruction with the FFT