Generative AI is transforming computing, paving new avenues for humans to interact with computers in natural, intuitive ways. For enterprises, the prospect of generative AI is vast. Businesses can tap into their rich datasets to streamline time-consuming tasks—from text summarization and translation to insight prediction and content generation. But they must also navigate adoption challenges.
For example, cloud services run by general-purpose large language models (LLMs) simplify exploration. Yet these features may not always align with enterprise needs, as models are trained on broad datasets, instead of domain-specific data.
As such, organizations are building tailored solutions with myriad open-source tools. From validating compatibility to providing their own technical support, this can lengthen the time to successfully adopt generative AI in enterprises.
Designed for enterprise development, NVIDIA NeMo is an end-to-end platform for building custom generative AI apps anywhere. It offers a set of state-of-the-art microservices to enable a complete workflow, from automating distributed data processing, to training large-scale bespoke models using sophisticated 3D parallelism techniques, to connecting to your private data using retrieval-augmented generation (RAG).
Custom generative AI models created with NeMo can be deployed in NVIDIA NIM, a set of easy-to-use microservices designed to speed up generative AI deployment anywhere, on-premises or in the cloud.
For enterprises running their business on AI, NVIDIA AI Enterprise is the end-to-end software platform that provides the fastest and most efficient runtime for generative AI foundation models. It includes NeMo and NIM to streamline adoption with security, stability, manageability, and enterprise-class support.
Now, organizations can integrate AI into their operations, streamlining processes, enhancing decision-making capabilities, and driving greater value.
Production-ready generative AI with NVIDIA NeMo
NeMo simplifies the path to building custom, enterprise-grade generative AI models by providing end-to-end capabilities as microservices, as well as recipes for various model architectures (Figure 1).
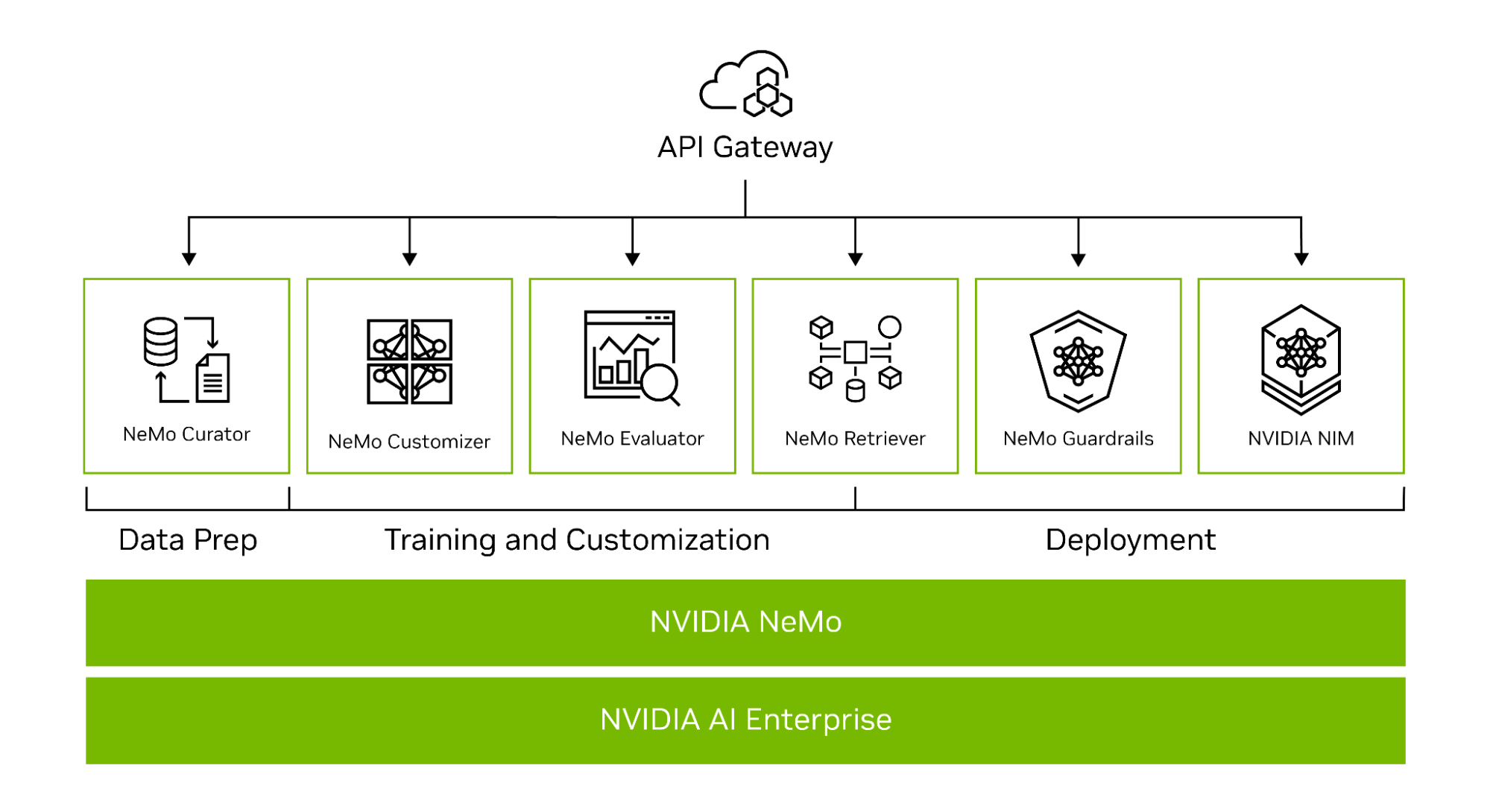
To help you create custom LLMs, the NeMo framework provides powerful tools:
- NeMo Curator for GPU-accelerated data curation of high-quality training data sets
- NeMo Customizer for simplified fine-tuning and alignment of LLMs
- NeMo Evaluator for automatic accuracy assessment of LLMs
- NeMo Retriever to connect custom models to proprietary business data using RAG
- NeMo Guardrails to safeguard an organization’s generative AI applications
NeMo Curator
The demand for high-quality datasets has become a critical factor in building functional LLMs.
NeMo streamlines the often-complex process of data curation with NVIDIA NeMo Curator, which addresses the challenges of curating trillions of tokens in multilingual datasets. Through its scalability, this tool empowers you to effortlessly handle tasks like data download, text extraction, cleaning, filtering, exact or fuzzy deduplication, and multilingual downstream task decontamination. To learn more, see Scale and Curate High-Quality Datasets for LLM Training with NeMo Curator.
Leveraging the power of cutting-edge technologies such as Dask, RAPIDS cuDF, RAPIDS cuGraph and PyTorch, NeMo Curator can scale data curation processes across thousands of networked GPUs, significantly reducing manual efforts and accelerating the development workflow.
One of the most striking advancements is in the process of data deduplication, where GPU acceleration has been shown to significantly outperform traditional CPU methods. Using a GPU for deduplication is up to 26 times faster and 6.5 times cheaper than relying on a CPU-based approach. This remarkable improvement not only reduces costs, but also enhances efficiency, enabling developers to process data at an unprecedented pace.
The scalability of NVIDIA technology is unparalleled, with the capacity to utilize thousands of GPUs. This scalability is crucial for preparing large pretraining datasets within realistic time frames, a task that is becoming increasingly important as AI models grow in complexity and size.
When it comes to performance, LLMs benefit significantly when trained on tokens prepared by the NeMo Curator. This tool ensures that the data fed to LLMs is of the highest quality, leading to better-performing models.
In the near future, NeMo Curator will also support data curation for model customization such as supervised fine-tuning (SFT), and parameter efficient fine-tuning (PEFT) approaches including LoRA and P-tuning.
Apply for early access to NVIDIA NeMo microservices to get the latest NeMo Curator microservice. It also comes packaged in the NeMo framework container, available through the NVIDIA NGC catalog.
Distributed training at large scale
There are distinct challenges of acceleration and scale when training billion-parameter LLMs from scratch. The task requires extensive, distributed computing power, clusters of acceleration-based hardware and memory, dependable and scalable machine learning (ML) frameworks, and fault-tolerant systems.
At the core of the NeMo framework is the unification of distributed training and advanced parallelism. NeMo expertly uses GPU resources and memory across nodes, resulting in groundbreaking efficiency gains. By dividing the model and training data, NeMo enables seamless multi-node and multi-GPU training, significantly reducing training time and enhancing overall productivity.
Parallelism techniques
A notable feature of NeMo is its incorporation of various parallelism techniques:
- Data Parallelism
- Fully Sharded Data Parallelism (FSDP)
- Tensor Parallelism
- Pipeline Parallelism
- Sequence Parallelism
- Expert Parallelism
- Context Parallelism
Memory-saving techniques
Additionally, NeMo supports several memory-saving approaches:
- Selective Activation Recomputation (SAR)
- CPU offloading (activation, weights)
- Flash Attention (FA), Grouped Query Attention (GQA), Multi-Query Attention (MQA), Sliding Window Attention (SWA)
NeMo is the leading solution to support multimodality training at scale. The platform supports language and multimodal models including Llama 2, Falcon, CLIP, Stable Diffusion, LLaVA, and various text-based generative AI architectures including GPT, T5, BERT, Mixture of Experts (MoE), and RETRO. In addition to LLMs, NeMo supports several pretrained models for computer vision, automatic speech recognition, natural language processing and text-to-speech.
The NeMo framework container available through the NGC catalog provides all of the tools for organizations to train models on their own.
NVIDIA AI Foundation models
Although some generative AI apps require training an LLM from scratch, most organizations use pretrained models to build their customized LLMs. This approach jump-starts the process, saving time and resources.
By skipping the data collection and cleaning phases required on the vast dataset used to train an LLM from scratch, you can focus on fine-tuning the model using a much smaller dataset that’s specific to your needs. This accelerates the time to the final solution. Moreover, the burden of infrastructure setup and model training is greatly reduced, as pretrained models come with pre-existing knowledge, ready to be customized.
Accuracy is one of the more common measurements used to evaluate pretrained models, but there are also other considerations including model size, cost to fine-tune, latency, throughput, and commercial licensing options.
NVIDIA makes it easier for developers to achieve the best performance on accelerated infrastructure and streamline the transition to production AI with NVIDIA AI Foundation models.
NVIDIA AI Foundation models include leading community models optimized for performance and enterprise-grade NVIDIA models built from responsibility-sourced data.
NVIDIA TensorRT-LLM optimizes NVIDIA AI Foundation models for latency and throughput to deliver the highest performance. Training is performed with responsibly sourced data. These models deliver results similar to larger models, making them ideal for enterprise applications.
These models are formatted to take advantage of NeMo customization and parallelism techniques and tune faster with proprietary data.
With the newly launched NVIDIA API catalog, developers can experience the models directly from a browser or prototype with NVIDIA-hosted API endpoints for these models. And when ready to self-deploy, the foundation models can be downloaded and run on any GPU-accelerated data center, cloud, or workstation.
NeMo Customizer
Businesses across various industries require unique capabilities, and generative AI model customization is evolving to accommodate their needs. NeMo offers a variety of LLM customization techniques to refine generic, pretrained LLMs for specialized use cases. NVIDAI NeMo Customizer is a new high-performance, scalable microservice that helps developers simplify the fine-tuning and alignment of LLMs.
NeMo Customizer brings a suite of advanced capabilities to the forefront of machine learning model development. One of its standout features is the support for state-of-the-art fine-tuning and alignment techniques, which enables users to achieve superior model performance by precisely adjusting models to specific needs.
NeMo Customizer leverages advanced parallelism techniques, which not only enhance training performance but also considerably reduce the time required to train complex models. This aspect is particularly beneficial in today’s fast-paced development environments where speed and efficiency are paramount.
Designed to support the fine-tuning of larger models by scaling across multiple GPUs and multiple nodes, NeMo Customizer addresses one of the significant challenges in the field of deep learning.
This scalability ensures that even the most demanding models can be trained effectively, making the NeMo Customizer an invaluable tool for researchers and practitioners aiming to push the boundaries of what’s possible with AI. To learn more, see Fine-Tune and Align LLMs Easily with NVIDIA NeMo Customizer.
Organizations can apply for early access to NVIDIA NeMo microservices to get started with the NeMo Customizer microservice. Developers can begin customizing models immediately using the NeMo framework container available through the NGC catalog.
NeMo Evaluator
As organizations increasingly tailor LLMs to meet their unique operational needs, there arises a critical requirement to continuously evaluate and optimize these models to ensure they deliver the highest level of accuracy and responsiveness.
This ongoing evaluation process is vital not only for maintaining the performance of the models on tasks they were originally trained for, but also to ensure they adapt effectively to new, application-specific requirements.
NeMo Evaluator simplifies this complex task through automated benchmarking capabilities, enabling the comprehensive assessment of pretrained and fine-tuned LLMs. This tool supports a wide range of models, including foundation models, aligned models, and task-specific LLMs, among others, offering versatility in evaluation for various applications.
The microservice provides an open and extensible design, enabling evaluation of models with respect to many popular academic benchmarks and custom datasets. NeMo Evaluator is designed to ensure efficiency and flexibility for LLMs running locally, on any cloud or data center. For more details, see Streamline Evaluation of LLMs for Accuracy with NVIDIA NeMo Evaluator.
NeMo Evaluator extends the capabilities of the NeMo Curator and NeMo Customizer to offer a complete set of tools to help organizations build custom generative AI models. Apply for early access to NVIDIA NeMo microservices.
NeMo Retriever
NeMo Retriever is a collection of microservices enabling accelerated semantic search of enterprise data to deliver highly accurate responses through retrieval augmentation. For more details, see Translate Your Enterprise Data into Actionable Insights with NVIDIA NeMo Retriever.
These microservices are tailored to handle specific tasks, including:
- Ingesting large volumes of documents in the form of PDF files, office documents, and other rich text files.
- Encoding and storing these documents for semantic search.
- Interacting with existing relational databases.
- Searching for relevant pieces of information to answer questions.
With NeMo Retriever, organizations can access world-class information retrieval capabilities with the lowest latency, highest throughput, and maximum data privacy, enabling better use of proprietary data to generate business insights in real time.
Get started today with the NeMo Retriever microservices in the NVIDIA API catalog. For more information, check out the NVIDIA Generative AI Examples and code samples.
NeMo Guardrails
In the rapidly evolving landscape of generative AI, the importance of implementing robust safety measures cannot be overstated. As these AI applications become increasingly integrated into a wide range of industries, ensuring their safe and secure operation is paramount.
Guardrails serve as a crucial mechanism in this regard, acting as programmable constraints or rules that regulate the interaction between users and LLMs. Similar to the way physical guardrails on highways prevent vehicles from veering off course, these digital guardrails are designed to monitor, influence, and control a user’s interactions with AI systems.
They help to maintain the focus of AI interactions within predetermined boundaries, preventing the generation of hallucinatory, toxic, or misleading content and blocking malicious commands or unauthorized access to third-party applications. This system of checks and balances is essential for preserving the integrity and safety of generative AI applications across various domains.
NeMo Guardrails addresses these challenges by offering a sophisticated dialog management system that prioritizes accuracy, appropriateness, and security in applications powered by LLMs. It provides organizations with the tools needed to enforce safety and security protocols effectively, ensuring that their AI systems operate within the desired parameters.
NeMo Guardrails facilitates the easy programming and implementation of these safety measures, offering fuzzy programmable guardrails that enable flexible yet controlled user interactions. Its integration capabilities with enterprise-ready solutions, including Langchain and other third-party applications, bolster the security of LLM systems against potential threats.
By deeply integrating with the broader LLM ecosystem and supporting popular frameworks, NeMo Guardrails ensures that generative AI applications remain safe, secure, and aligned with organizational values, policies, and objectives. For more details, see NVIDIA Enables Trustworthy, Safe, and Secure Large Language Model Conversational Systems.
NeMo Guardrails is an open-source toolkit for easily developing safe and trustworthy LLM conversational systems that work with all LLMs, including OpenAI’s ChatGPT and NVIDIA NeMo. To get started, visit NVIDIA/NeMo-Guardrails on GitHub.
NVIDIA NIM
To support AI inference in production environments, the infrastructure and support systems must be robust, scalable, and efficient to facilitate the transition. Organizations are now recognizing the need to invest in and develop such infrastructures to stay competitive and harness the full potential of generative AI.
NVIDIA NIM inference microservices simplify the path to deploy optimized generative AI models in enterprise environments. NIM supports a broad spectrum of AI models—from open-source community models to NVIDIA AI Foundation models, as well as custom AI models. For more details, see NVIDIA NIM Offers Optimized Inference Microservices for Deploying AI Models at Scale.
Leveraging industry-standard APIs, developers can quickly build enterprise-grade AI applications with just a few lines of code. Built on robust foundations including open-source inference engines like NVIDIA Triton Inference Server, NVIDIA TensorRT-LLM, and PyTorch, NIM facilitates AI inferencing at scale, ensuring that AI applications can be deployed at scale with confidence into production.
To get started with NIM, explore the optimized models on the NVIDIA API catalog.
Achieving seamless enterprise-grade generative AI
As part of NVIDIA AI Enterprise, NeMo offers compatibility across multiple platforms, including clouds, data centers, and now, NVIDIA RTX-powered workstations and PCs. This enables a true develop-once-and-deploy-anywhere experience, eliminates the complexities of integration, and maximizes operational efficiency.
Industry AI adopters
NeMo has already gained significant traction among forward-thinking organizations looking to build custom LLMs. ServiceNow, Amdocs, Dropbox, Writer, and Korea Telecom have embraced NeMo, leveraging its capabilities to drive their AI-driven initiatives.
Due to its unparalleled flexibility and support, NeMo opens a world of possibilities. Businesses can design, train, and deploy sophisticated LLM solutions tailored to specific needs and industry verticals. By leveraging NVIDIA AI Enterprise and integrating NeMo into your workflows, your organization can unlock new avenues of growth, derive valuable insights, and deliver cutting-edge AI-powered applications to customers, clients, and employees alike.
Get started with NVIDIA NeMo
A game-changing solution, NVIDIA NeMo is bridging the gap between the vast potential of generative AI and the practical realities faced by enterprises. As a comprehensive platform for LLM development and deployment, NeMo helps businesses adopt AI technology efficiently and cost-effectively.
With the powerful capabilities of NVIDIA NeMo, enterprises can integrate AI into operations, streamline processes, enhance decision-making capabilities, and unlock new avenues for growth and success.
Get started with NVIDIA NeMo to build production-ready generative AI for your enterprise. To access the NVIDIA NeMo microservices, apply now for early access. You can also get packages in the NeMo framework container, available through the NVIDIA NGC catalog.