
Across the globe, enterprises are realizing the benefits of generative AI models. They are racing to adopt these models in various applications, such as chatbots, virtual assistants, coding copilots, and more.
While general-purpose models work well for simple tasks, they underperform when it comes to catering to the unique needs of various industries. Custom generative AI models outperform their general counterparts and meet enterprise requirements by incorporating domain-specific knowledge, understanding local cultural nuances, and aligning with brand voice and values.
The NVIDIA NeMo team is announcing the early access program for NVIDIA NeMo Curator, NVIDIA NeMo Customizer, and NVIDIA NeMo Evaluator microservices. Covering all development stages from data curation and customization to evaluation, these microservices simplify the process for users building custom generative AI models.
NVIDIA NeMo is an end-to-end platform for developing custom generative AI, anywhere. It includes tools for training, fine-tuning, retrieval-augmented generation, guardrailing, data curation, and pretrained models. It has offerings across the tech stack, from frameworks to high-level API endpoints (Figure 1).
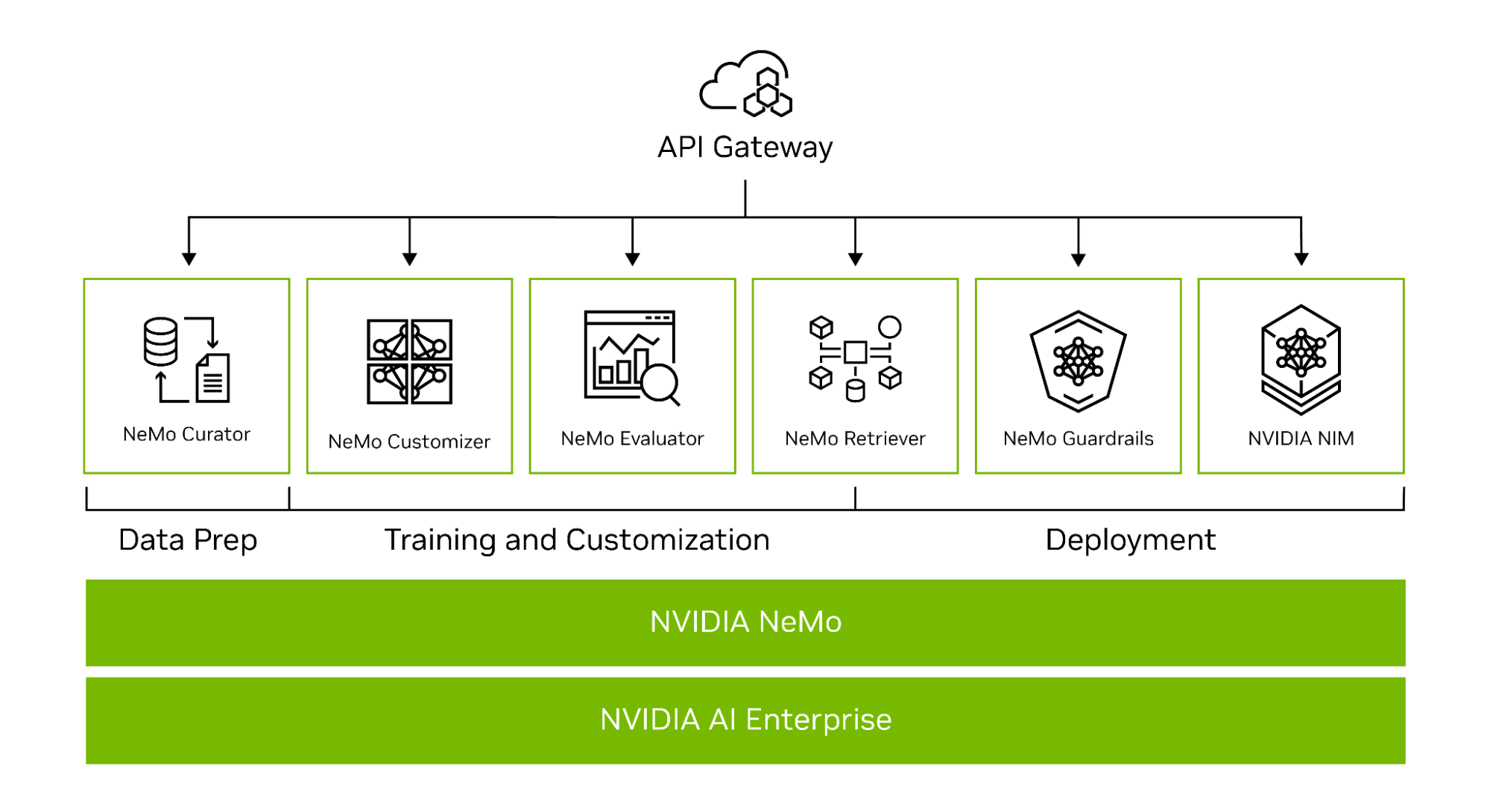
Part of NVIDIA CUDA-X microservices, the NeMo API endpoints are built on top of the NVIDIA libraries, providing an easy path for enterprises to get started with building custom generative AI.
Development microservices for custom generative AI
In the early access program, developers can request access to the NeMo Curator, NeMo Customizer, and the NeMo Evaluator microservices. Together, these microservices enable enterprises to build enterprise-grade custom generative AI and bring solutions to market faster.
The NeMo Curator microservice aids developers in curating data for pretraining and fine-tuning LLMs, while the NeMo Customizer enables fine-tuning and alignment. Lastly, with NeMo Evaluator developers can assess these models against academic or custom benchmarks and identify areas for improvement.
The following explores these microservices in detail.
NeMo Curator
NeMo Curator is a scalable and GPU-accelerated data-curation microservice that prepares high-quality datasets for pretraining and customizing generative AI models. Curator streamlines data-curation tasks such as data download, text extraction, cleaning, quality filtering, exact/fuzzy deduplication, and multilingual downstream task decontamination.
Curator supports the following:
- Fine-tuning techniques, such as, supervised fine-tuning (SFT), P-tuning, and low-rank adaptation (LoRA).
- A faster pipeline for data annotation that supports different kinds of metadata classifiers, including:
- Domain classifier for various domains such as healthcare, law, and more. Developers can use the most relevant data for domain-specific customization for model development, data blends, and enriching raw data
- Personal identifiable information (PII) detection to redact or remove the PII information at scale from the training data and comply with data privacy.
- Toxicity filter, to identify and remove irrelevant and toxic data with defined custom filters and categories
NeMo Customizer
NeMo Customizer is a high-performance, scalable microservice that simplifies fine-tuning and alignment of LLMs for domain-specific use cases. The microservice initially supports two popular parameter-efficient fine-tuning (PEFT) techniques: LoRA and p-tuning.
In addition, the NeMo Customizer microservice will add support for full alignment techniques in the future:
- SFT
- Reinforcement learning from human feedback (RLHF)
- Direct preference optimization (DPO)
- NVIDIA NeMo SteerLM
The NeMo Customizer microservice supports Kubernetes with access to an NFS-like file system and volcano scheduler for deployment. This enables batch scheduling capabilities, which are commonly required for high-performance multi-node fine-tuning of LLMs.
NeMo Evaluator
Customizing LLMs for specific tasks can cause catastrophic forgetting, a problem where the model forgets previously learned tasks. Enterprises using LLMs must assess performance on both original and new tasks, continuously optimizing the models for improved experiences. NeMo Evaluator provides automatic assessment of custom generative AI models across diverse academic and custom benchmarks on any cloud or data center.
It supports automated assessment through a selected collection of academic benchmarks including beyond the imitation game benchmark (BIG-Bench), Multilingual, BigCode Evaluation Harness, and Toxicity.
Supporting evaluation on custom datasets, NeMo Evaluator provides metrics such as accuracy, recall-oriented understudy for gisting evaluation (ROUGE), F1, and exact match.
It also enables the use of LLM-as-a-judge for comprehensive evaluation of model responses. It can leverage any NVIDIA NIM-supported LLM available in the NVIDIA API catalog for evaluating the model responses on the MT-Bench dataset.
Easily build custom generative AI
NeMo microservices offer the full benefits of the NeMo platform, such as accelerated performance and scalability. Developers can get faster training performance by leveraging parallelism techniques and scaling to multi-GPUs and multi-nodes when needed.
Microservices also offer enterprises benefits such as the ability to run on their preferred infrastructure, from on-prem to the cloud, enabling them control over data security, avoiding vendor lock-in, and reducing costs.
Regardless of the particular choices in the development stack, microservices offer adaptability and compatibility. They can be incorporated into current workflows as APIs easily, without concern for the specific technologies in use.
Sign up for early access
Sign up for NeMo microservices early access. Applications are reviewed case by case, with a link for accessing the microservice container sent to approved participants.
