
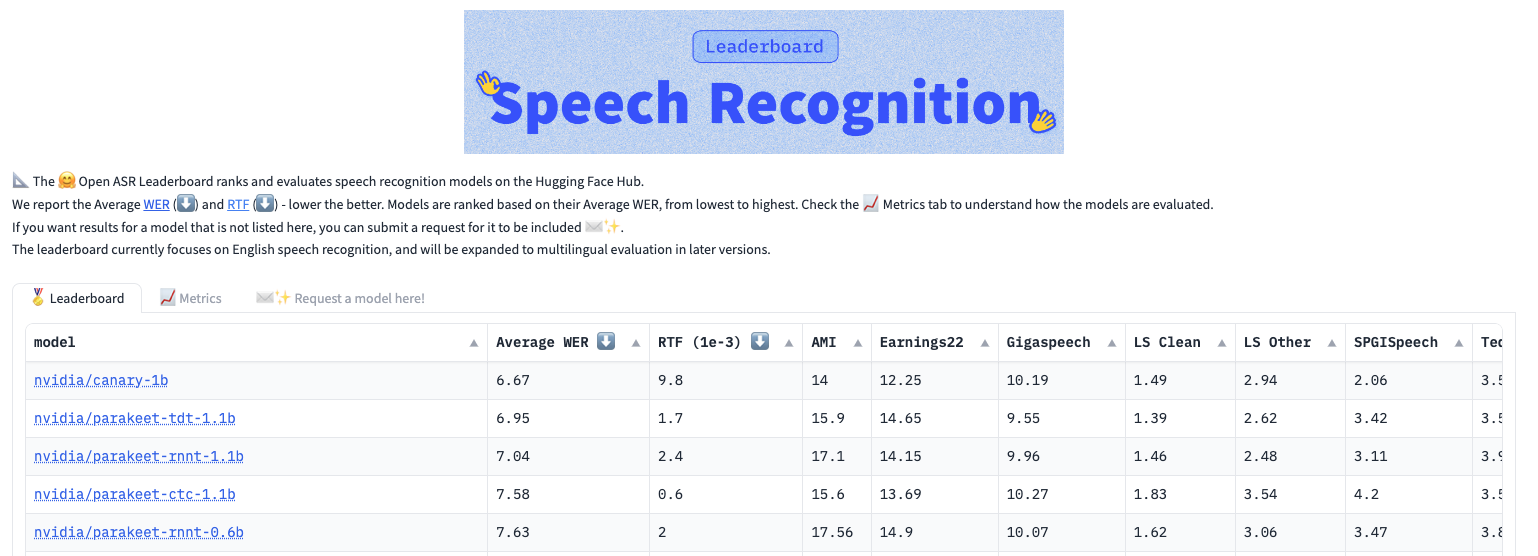
Speech and translation AI models developed at NVIDIA are pushing the boundaries of performance and innovation. The NVIDIA Parakeet automatic speech recognition (ASR) family of models and the NVIDIA Canary multilingual, multitask ASR and translation model currently top the Hugging Face Open ASR Leaderboard. In addition, a multilingual P-Flow-based text-to-speech (TTS) model won the LIMMITS ’24 challenge by synthesizing a speaker’s voice into seven languages using a short audio clip.
This post details how several of these best-in-the-world models are breaking new ground in speech and translation AI, from speech recognition to custom voice creation.
NVIDIA Parakeet speech recognition models
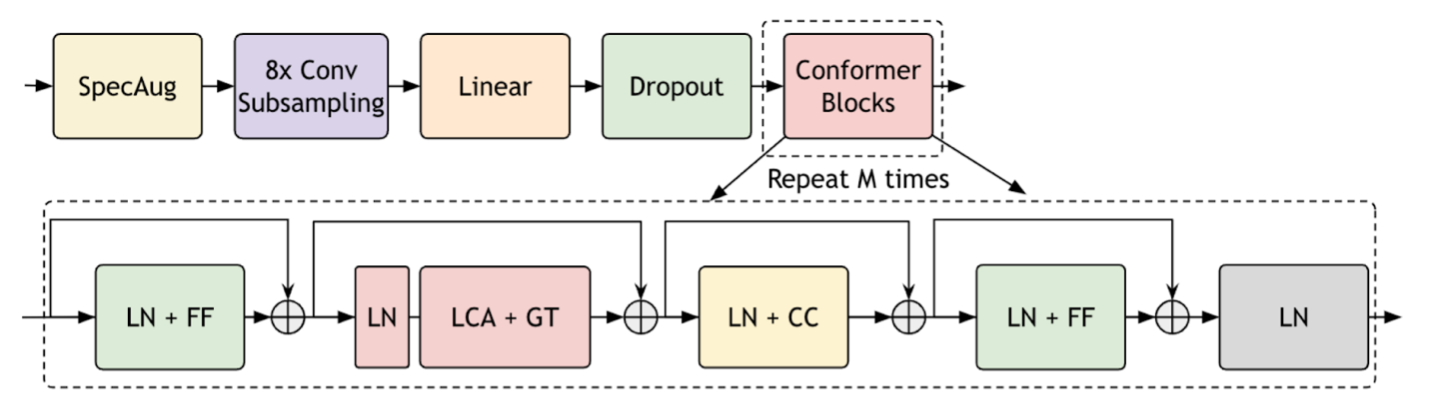
The NVIDIA Parakeet family of models includes Parakeet CTC 1.1B, Parakeet CTC 0.6B, Parakeet RNNT 1.1B, Parakeet RNNT 0.6B, and Parakeet-TDT 1.1B. These models provide robust English speech transcription with a variety of options for different customer applications, accuracy, speed, and other requirements. The models come in two sizes: 0.6 billion and 1.1 billion parameters.
Key advantages of Parakeet models include:
- State-of-the-art accuracy delivered with superior word error rate (WER) across diverse audio sources and domains.
- Fast inference speed of 1,336 hours of audio in one hour of real time for transcription with Parakeet CTC 1.1 B, 1,212 with Parakeet TDT 1.1B, and 1,120 with Parakeet RNN-T 1.1B. Note measurements conducted outside of Hugging Face leaderboard evaluations with the additional algorithmic and CUDA-level optimizations.
- Superior noise robustness to background speech and non-speech segments.
- Seamless integration and customization as models come with ready-to-use pretrained checkpoints, facilitating ease of deployment for inference and fine-tuning tasks.
The effectiveness of the Parakeet CTC and RNNT models lies in end-to-end training using the fast conformer (FC) encoder, recurrent neural network transducer (RNNT) and connectionist temporal classification (CTC) decoders. For more details, see Investigating End-to-End ASR Architectures for Long Form Audio Transcription and Fast Conformer with Linearly Scalable Attention for Efficient Speech Recognition.
Parakeet-TDT model for turbocharging speech recognition
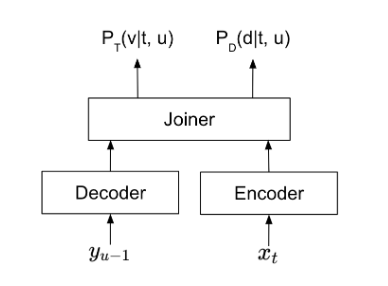
The Parakeet-TDT (token-and-duration transducer) 1.1B model achieves the best accuracy among the Parakeet family when transcribing spoken English while running 64% faster than the second-best Parakeet model at the Hugging Face leaderboard evaluations.
What makes Parakeet-TDT 1.1B stand out in terms of speed and accuracy is its TDT model architecture, which is a novel sequence modeling architecture developed by NVIDIA. To learn more, see Efficient Sequence Transduction by Jointly Predicting Tokens and Durations.
Parakeet-TDT 1.1B decouples token and duration predictions and uses duration output to skip majority blank predictions. The reduction of wasteful computation during the recognition process significantly accelerates inference and enhances robustness to noisy speech, compared to traditional transducer models.
Canary multilingual model for speech recognition and translation
Canary 1B is a multilingual multitasking model with state-of-the-art accuracy on multiple benchmarks. It transcribes English, German, French, and Spanish speech both with and without punctuation and capitalization (PnC). It also supports bidirectional English translation from and to German, French, and Spanish. With an average WER of 6.67%, Canary is currently the most accurate model on the Hugging Face Open ASR Leaderboard, outperforming all other models by a wide margin.
Canary is an encoder-decoder model built on several innovations. The encoder is a fast conformer, optimized for ~3x compute savings and ~4x memory savings compared to the conformer encoder.
The Canary encoder processes audio in the form of a log-Mel spectrogram and the transformer decoder generates output text tokens in an auto-regressive manner. The decoder is prompted with unique tokens to control whether Canary performs transcription or translation. Canary also incorporates the concatenated tokenizer, offering explicit control of the output token space. For more information, see Unified Model for Code-Switching Speech Recognition and Language Identification Based on Concatenated Tokenizer.
P-Flow for custom voice creation
NVIDIA won the LIMMITS ‘24 voice challenge by harnessing the P-Flow zero-shot TTS model to create a customized high-quality personalized voice for a speaker. P-Flow can use a speech prompt as short as three seconds. Zero-shot refers to generating speech with the voice characteristics of a speaker not in the model training data. The speech created by the P-Flow model matches the voice in the speech prompt, and is preferred in human likeness and voice similarity compared to state-of-the-art counterparts.
P-Flow consists of a speech-prompted text encoder for speaker voice adaptation, and a flow-matching generative decoder for fast, high-quality speech synthesis. The encoder uses speech prompts and text inputs to generate a speaker-conditional text representation. The decoder uses this speaker-conditional text representation to synthesize high-quality personalized speech significantly faster than in real time. To learn more, see P-Flow: A Fast and Data-Efficient Zero-Shot TTS through Speech Prompting.
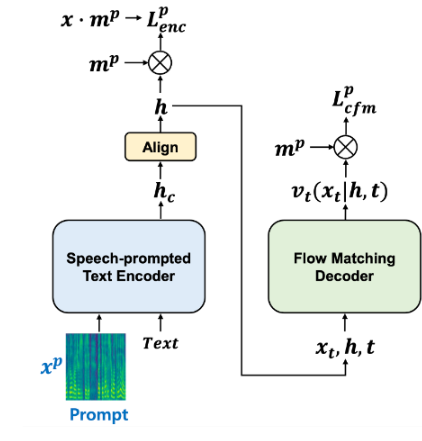
P-Flow creates high-quality voices without requiring super-large datasets, complex training setups, representation quantization steps, pretraining tasks, or slow autoregressive formulations.
For the voice challenge, the NVIDIA team extended the zero-shot TTS ability of P-Flow from its original language, English, to include seven additional Indic languages. This effectively creates a multilingual TTS system such that an unseen speaker can speak in any of seven targeted languages with a native accent, given just a three-second speech prompt.
The following samples showcase the NVIDIA-built multilingual P-Flow-based TTS. Starting with a three-second voice sample of a Kannada speaker, the model produces the same vocal qualities with native Hindi and English accents.
Input
The input is a three-second sample of a native Kannada speaker saying, “Thanks to their work driving AI forward, Akshit Arora and Rafael Valle could someday speak to their spouses’ families in their native languages.”
Output
The output is a similar-sounding synthesized voice reading input text in Hindi and English.
Hindi:
English:
Conclusion
NVIDIA speech and translation AI models are pushing the boundaries of performance and innovation. With its RNNT and CTC variants, the Parakeet family of models offers a spectrum of options, balancing accuracy and speed to suit diverse deployment needs. The Parakeet-TDT model sets a new benchmark by coupling superior accuracy with unprecedented speed, epitomizing efficiency in speech recognition.
The Canary multilingual model emerges as the new standard, excelling in speech recognition and translation across multiple languages with unparalleled accuracy.
The P-Flow multilingual model enables the creation of custom voices, offering a fast and data-efficient solution for personalized speech synthesis. By harnessing P-Flow, NVIDIA synthesized speaker voices across multiple languages with remarkable fidelity and efficiency.
The groundbreaking Parakeet-CTC and P-Flow models are available now, exclusively for enterprises. This restriction is to prevent potential misuse of the P-Flow zero-shot TTS in the form of, for example, voice impersonation of public figures and non-consenting individuals.
Parakeet-RNNT, Parakeet-TDT, and the Canary models will be available soon as part of NVIDIA Riva. Experience speech and translation AI models through the NVIDIA API catalog and run them on-premises with NVIDIA NIM — cloud, data center, workstation, or PC. NVIDIA LaunchPad provides the necessary hardware and software stacks on private-hosted infrastructure for additional exploration.
Join us in person or virtually for these NVIDIA GTC 2024 sessions to learn more about the potential of AI-driven communication:
- Speech AI Demystified
- Speaking in Every Language: A Quick Start Guide to TTS Models for Accented, Multilingual Communication
- Build a RAG-Powered Application with a Human Voice Interface
- Mastering Speech AI for Multilingual Multimedia Transformation
- Secure AI-Driven Translation in Video Conferencing
- Adapting Conformer-Based ASR Models for Conversations Over the Phone
- Behind the Scenes of Running a Conversational Character in a 3D Scene
- Multi-Speaker ASR with NVIDIA NeMo Toolkit —Training & Inference
