
NVIDIA NeMo is an end-to-end platform for the development of multimodal generative AI models at scale anywhere—on any cloud and on-premises.
The NeMo team just released Canary, a multilingual model that transcribes speech in English, Spanish, German, and French with punctuation and capitalization. Canary also provides bi-directional translation, between English and the three other supported languages.
This post details the Canary model and how to use it.
Canary overview
Canary ranks at the top of the HuggingFace Open ASR Leaderboard with an average word error rate (WER) of 6.67%. It outperforms all other open-source models by a wide margin.
Canary is trained on a combination of public and in-house data. It uses 85K hours of transcribed speech to learn speech recognition. To teach Canary translation, we used NVIDIA NeMo text translation models to generate translations of the original transcripts in all supported languages.
Despite using an order of magnitude less data, Canary outperforms the similarly sized Whisper-large-v3, and SeamlessM4T-Medium-v1 models on both transcription and translation tasks. On the MCV 16.1 test sets for English, Spanish, French, and German, Canary had a WER of 5.77 (Figure 1).
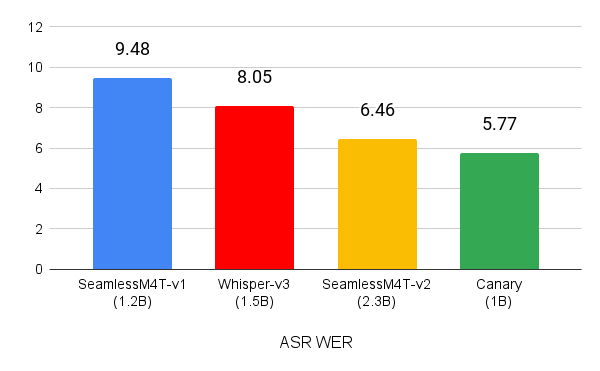
(lower is better)
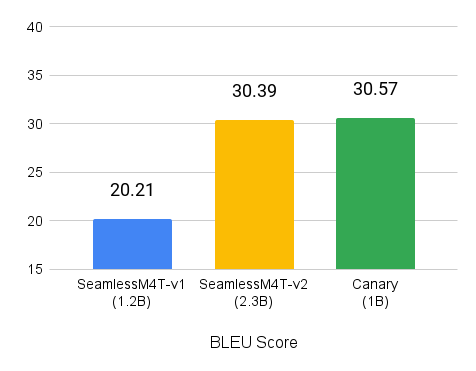
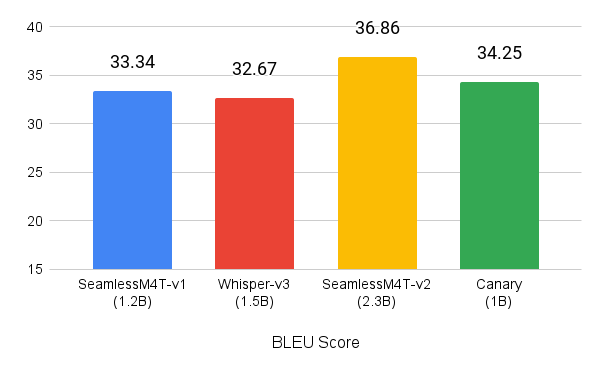
You can try the canary-1b model inside the Gradio demo. For more information about how to access Canary locally and build on top of it, see the NVIDIA/NeMo GitHub repo
Canary architecture
Canary is an encoder-decoder model built on NVIDIA innovations.
The encoder is Fast-Conformer, an efficient Conformer architecture optimized for ~3x savings on compute and ~4x savings on memory. The encoder processes audio in the form of log-mel spectrogram features and the transformer decoder generates output text tokens in an auto-regressive manner. The decoder is prompted with special tokens to control whether Canary performs transcription or translation.
Canary also incorporates the concatenated tokenizer, offering explicit control of output token space.
The model weights are distributed under a research-friendly non-commercial CC BY-NC 4.0 license, while the code used to train this model is available under the Apache 2.0 license from NeMo.
How to transcribe with Canary
To use Canary, install NeMo as a pip package. Install Cython and PyTorch (2.0 and later) before installing NeMo.
pip install nemo_toolkit['asr']
When NeMo is installed, use Canary to transcribe or translate audio files:
# Load Canary model
from nemo.collections.asr.models import EncDecMultiTaskModel
canary_model = EncDecMultiTaskModel.from_pretrained('nvidia/canary-1b')
# Transcribe
transcript = canary_model.transcribe(audio=["path_to_audio_file.wav"])
# By default, Canary assumes that input audio is in English and transcribes it.
# To transcribe in a different language, such as Spanish
transcript = canary_model.transcribe(
audio=["path_to_spanish_audio_file.wav"],
batch_size=1,
task='asr',
source_lang='es', # es: Spanish, fr: French, de: German
target_lang='es', # should be same as "source_lang" for 'asr'
pnc=True )
# To translate using Canary. For example, from English audio to French text
transcript = canary_model.transcribe(
audio=["path_to_english_audio_file.wav"],
batch_size=1,
task='ast',
source_lang='en',
target_lang='fr',
pnc=True )
Conclusion
The Canary multilingual model has emerged as the new standard, excelling in speech recognition and translation across English, Spanish, German, and French with unparalleled accuracy.
For more information about the Canary architecture, see the following resources:
- Fast Conformer with Linearly Scalable Attention for Efficient Speech Recognition
- Unified Model for Code-Switching Speech Recognition and Language Identification Based on Concatenates Tokenizer
Try canary-1b firsthand inside the Gradio demo or access the model locally through the NVIDIA/NeMo GitHub repo. Parakeet-CTC is also available now and other models will be available soon as part of NVIDIA Riva.
Experience speech and translation AI models through the NVIDIA API catalog and run them on-premises with NVIDIA NIM. For more exploration, NVIDIA LaunchPad provides the necessary hardware and software stacks on private hosted infrastructure.
Acknowledgments
Thanks to all the model authors who contributed to this post: Krishna Puvvada, Piotr Zelasko, He Huang, (Steve) Oleksii Hrinchuk, Nithin Koluguri, Somshubra Majumdar, Elena Rastorgueva, Kunal Dhawan, Zhehuai Chen, Vitaly Lavrukhin, Jagadeesh Balam, Boris Ginsburg
