
When interacting with a virtual assistant, you give a command and receive a verbal response. The technology powering this generated voice response is known as text-to-speech (TTS).
TTS applications are highly useful as they enable greater content accessibility for those who use assistive devices. With the latest TTS techniques, you can generate a synthetic voice from only a few minutes of audio data–this is ideal for those who have lost their voice and only have limited recordings.
In fact, the use of TTS is growing as a result of recent advances:
- Running an end-to-end TTS pipeline in a few milliseconds for natural interactions.
- Customizing AI models and pipelines at inference time to generate expressive synthetic voice.
- Deploying in all cloud, data centers, at the edge, or on embedded devices.
This post explains how speech synthesis systems operate and then introduces both common and novel uses of TTS technology.
How speech synthesis systems work
As the name suggests, text-to-speech, or speech synthesis, is the process of transforming written text into natural, human-like speech audio. In an end-to-end TTS pipeline, these are the key models and modules that make this conversion possible:
- Text normalization and preprocessing: Turns numbers and abbreviations into words.
- Text encoding: Converts text into an encoded vector that is used as an input to a spectrogram generator.
- Spectrogram generator: Generates spectrogram from an encoded text vector.
- Vocoder model: Takes spectrograms as an input and generates a synthetic voice that we can all hear.
In general, TTS is the last stage in applications such as virtual assistants, digital humans, and service robots.
Common TTS applications
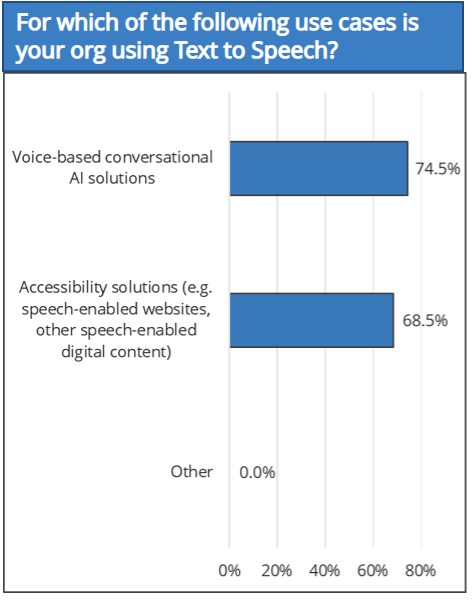
In the 2021 IDC Conversational AI Adoption Survey, among 251 companies, 74.5% reported using TTS in voice-based conversational AI solutions and 68.5% using TTS in accessibility solutions (Figure 1).
In several industries, speech synthesis is proving its functional purpose. You may have already observed TTS technology with the following use cases.
Virtual influencers
Virtual influencers are shifting the future of communication with any company or celebrity. Also referred to as virtual brand ambassadors or brand voices, virtual influencers can assist companies with promoting products and services, and celebrities can use them to stay in touch with fans 24/7.
In these use cases, TTS technology generates custom voices that are then integrated into an animated virtual influencer or digital ambassador.
Text narration
Text narration is the act of reading any type of text aloud. Available on websites and reading apps, this TTS feature benefits those who prefer listening to content. Individuals with visual difficulties can also use text narration to listen to the content they enjoy.
TTS is used to generate the voice used by these applications to read the text aloud. However, it is not as simple as it seems. To improve the listening experience, these applications’ voices must have the proper pitch, pace, and expressiveness.
Content creation
Audio and video content are popular, engaging mediums for people living in the modern world. TTS technology makes it possible for content creators to add voiceovers to videos or create podcasts.
To reach a wider audience, TTS technology can also be used to create audio versions of text content, such as blogs and news articles.
With the flexibility of a TTS pipeline, you can modify the pitch, pace, and volume of speech in applications such as voice changers, to make the voice more expressive.
Unique TTS applications
Beyond these everyday applications, entrepreneurs are exploring a variety of novel TTS applications. Featured in this post are companies using speech synthesis technology for compelling use cases.
Voice kiosks for smarter hospitals: Artisight
Artisight, an IoT sensor network for hospitals, promises to improve hospital operations, financial performance, and patient experiences. The company helps many of the best hospitals in the U.S. run more efficiently while giving patients a better experience by automating tasks, such as calling patients to registration windows and lab check-in.
TTS technology in hospitals can be used to share information with patients and visitors about the hospital’s services, facility directions, and general health announcements. This technology can also be made available in multiple languages to assist those who may not speak the primary language spoken at the hospital.
The preceding video shows how text-to-speech technology is used within hospital kiosks to announce patient badge ID numbers.
Challenges and solutions
In the past, hospital receptionists manually registered patients and notified them when a doctor was available. This time-consuming registration procedure reduced hospital efficiency and negatively impacted patient satisfaction.
Artisight developed smart hospital solutions, such as voice-enabled check-in and notification kiosks to improve the patient experience.
Voice-enabled kiosks powered by Artisight and NVIDIA Riva are delivering effective, speedy patient registration, reducing wait times by half, and eliminating data entry errors–all leading to increased staff productivity and patient happiness.
Human-like voice for digital avatars: NVIDIA
TTS technology enables computers to convert written text into spoken words, making it possible for digital humans to “speak” and communicate with users in a more naturally and engaging way.
To build trust and credibility with users, digital humans must speak with high accuracy, particularly when they are being used for education, entertainment, or other interactive purposes. Using TTS technology to produce speech that sounds natural and human-like can help digital humans capture the attention and interest of users.
As you can see in the NVIDIA Omniverse Avatar Cloud Engine (ACE) demo, Toy Jensen understands what Jensen Huang is asking and answers in a natural manner. Toy Jensen’s voice was created using NVIDIA Riva.
Challenges and solutions
Developing TTS for digital humans can be challenging, particularly in terms of creating speech that sounds natural and realistic depending on the region and language. This is because TTS systems created using traditional and statistical algorithms can result in speech that sounds robotic or mechanical and may not be well received by users.
Additionally, digital human applications involve creating speech that is flexible and adaptable, which can be a challenge because TTS systems rely on factors, such as datasets and the type of models and modules used. This can make it difficult for developers to produce nuanced and expressive speech.
Finally, creating efficient and scalable TTS systems is important because digital humans may have to generate large amounts of speech in real time without sacrificing quality.
At NVIDIA, we generated custom voices for digital human and avatar use cases, such as Toy Jensen and Violet with Riva. Riva helps you develop accurate TTS pipelines that can run in real time in just a few milliseconds—a necessity for natural speech. It also provides flexibility to control elements like pitch, duration, and volume to make a generated voice more expressive.
Get started with speech synthesis
You can begin integrating TTS capability with your apps, such as text narration for consuming content or unique voices for digital influencers. SDKs such as NVIDIA Riva help you develop applications that can deliver world-class accuracy and produce high-performance inference.
Try NVIDIA Riva TTS on your web browser or download the Riva Skills Quick Start Guide.
Related resources
Familiarize yourself with TTS by reading the free ebook, End-to-End Speech AI Pipelines. The ebook breaks down the models and modules used in an end-to-end TTS pipeline.
Or, explore different TTS terminologies with the post, A Guide to Understanding Essential Speech AI Terms.
Advanced developers can also check out the free ebook resource, Building Speech AI Applications, to learn how to build and deploy real-time TTS pipelines for apps.