
Across every industry, and every job function, generative AI is activating the potential within organizations—turning data into knowledge and empowering employees to work more efficiently.
Accurate, relevant information is critical for making data-backed decisions. For this reason, enterprises continue to invest in ways to improve how business data is stored, indexed, and accessed.
According to the IDC Global DataSphere Forecast 2023, there will be 11 zettabytes of unique enterprise data created in 2024. The amount of unique data created by enterprises is projected to grow to 20 zettabytes by 2027–of which 83% will be unstructured and half will be audio and video. The amount of unstructured data created in 2027 will be equivalent to nearly 800,000 Libraries of Congress. In an enterprise setting, this information must be mined out of data spread across multiple data lakes.
A multitude of sources are used to access this information, including live dashboards; manually generated reports that contain a mix of charts, tables, diagrams, and text; database queries; and generic search tools.
Both the content and context of information changes over time, thus requiring a recurring cycle of working with information across these sources and re-assessing evidence and decisions. When answering complex business questions, this process can be manually intensive and time-consuming. This can lead to the underutilization of information, as there isn’t an easy solution for accessing relevant data points.
Using generative AI, it is now possible to build a conversational interface that can use your tools and search your data to answer questions. In other words, now you can talk to your data to make faster, smarter decisions. NVIDIA NeMo Retriever can help with every step of this process.
What is NVIDIA NeMo Retriever?
Part of NVIDIA NeMo, an end-to-end platform for developing custom generative AI, NeMo Retriever is a collection of microservices enabling semantic search of enterprise data to deliver highly accurate responses using retrieval augmentation. Developers leverage a variety of GPU-accelerated microservices, each tailored to handle specific tasks, such as:
- Ingesting large volumes of documents in the form of PDF reports, office docs, and other rich text files.
- Encoding and storing the above for semantic search.
- Interacting with existing relational databases.
- Searching for relevant pieces of information to answer business questions.
These microservices are built on top of CUDA, NVIDIA TensorRT, NVIDIA Triton Inference Server, and many other SDKs from the NVIDIA software suite to maximize ease of use, reliability, and performance.
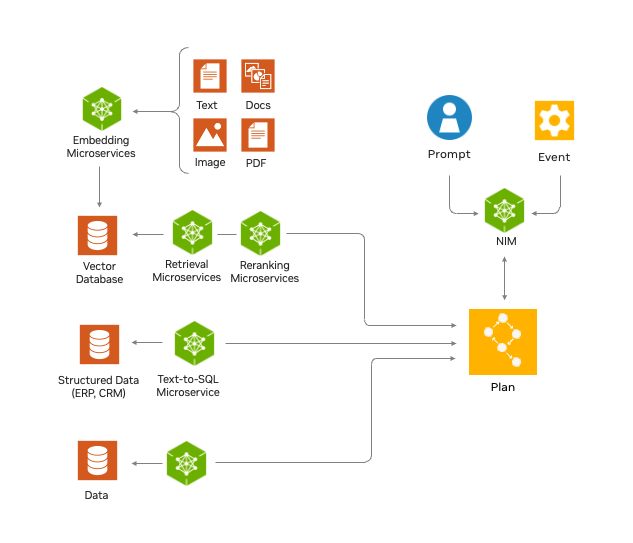
Answering complex business questions often requires effective planning, specialized tools, and extracting information from data spread across different modalities (Figure 1). This can be achieved by building LLM-powered AI agents. To provide guidelines around building agents powered by NeMo Retriever, the microservices are packaged with several reference agents.
These microservices and agents can accelerate the process of extracting information from vast amounts of data by enabling humans focus on “asking and answering the right questions,” which are often complex and require domain expertise, rather than spending time doing the manual, time-consuming work of finding and compiling relevant information to answer these questions.
Unlocking the world’s enterprise data
Data platform companies including Adobe, Cloudera, Cohesity, DataStax, NetApp, and Pure Storage are collaborating with NVIDIA to leverage NeMo Retriever to transform their data into valuable business insights.
- Adobe’s proprietary AI will help unlock the knowledge inside the world’s more than 3 trillion PDFs worldwide.
- Cloudera will expand its generative AI capabilities by integrating NeMo Retriever with Cloudera Machine Learning to unlock the potential of 25 exabytes of enterprise data.
- Cohesity data platform customers can add generative AI intelligence to their data backups and archives.
- DataStax Astra DB leverages NVIDIA NeMo Retriever and NVIDIA NIM inference microservices, improving the performance of RAG applications. Using NVIDIA H100 GPUs, they achieve an embedding and indexing latency of 10 ms.
- NetApp unlocks exabytes of data, empowering customers to securely “talk to their data” to access business insights.
- Pure Storage created a RAG pipeline leveraging NeMo Retriever microservices and NVIDIA GPUs and Pure Storage for all-flash enterprise storage. As a result, Pure accelerates time to insight for enterprises using their own internal data for AI training, ensuring the use of their latest data and eliminating the need for constant retraining of LLMs.
Enterprise retrieval use cases
Once enterprises establish easy access to their information, there are countless ways they can make better use of it. This section examines a few use cases. In each case, answering a business question requires answering a series of targeted questions–answers that can only be produced by extracting information across different modalities and data stores.
Analyzing software security vulnerabilities
The process of triaging software containers for common vulnerabilities and exposures (CVEs) requires searching hundreds of pieces of information from various, different data sources–a tedious manual process that can take days. An event-triggered LLM agent automates this process by executing many perceive-reason-act loops as if it’s talking with itself. Using NVIDIA NIM inference microservices, NeMo Retriever, and NVIDIA Morpheus cybersecurity AI framework can shorten this process to seconds.
Resolving technical issues
Consider the following scenario: a network solutions engineer is diagnosing issues in a data center. This engineer must examine machine logs and system metrics to better understand the situation at hand. The engineer must also look up specific pieces of information and behaviors of individual components to further identify the affected components. This information is distributed throughout various sources, such as technical documentation, schematics, and vendor SKU catalogs (Figure 2).
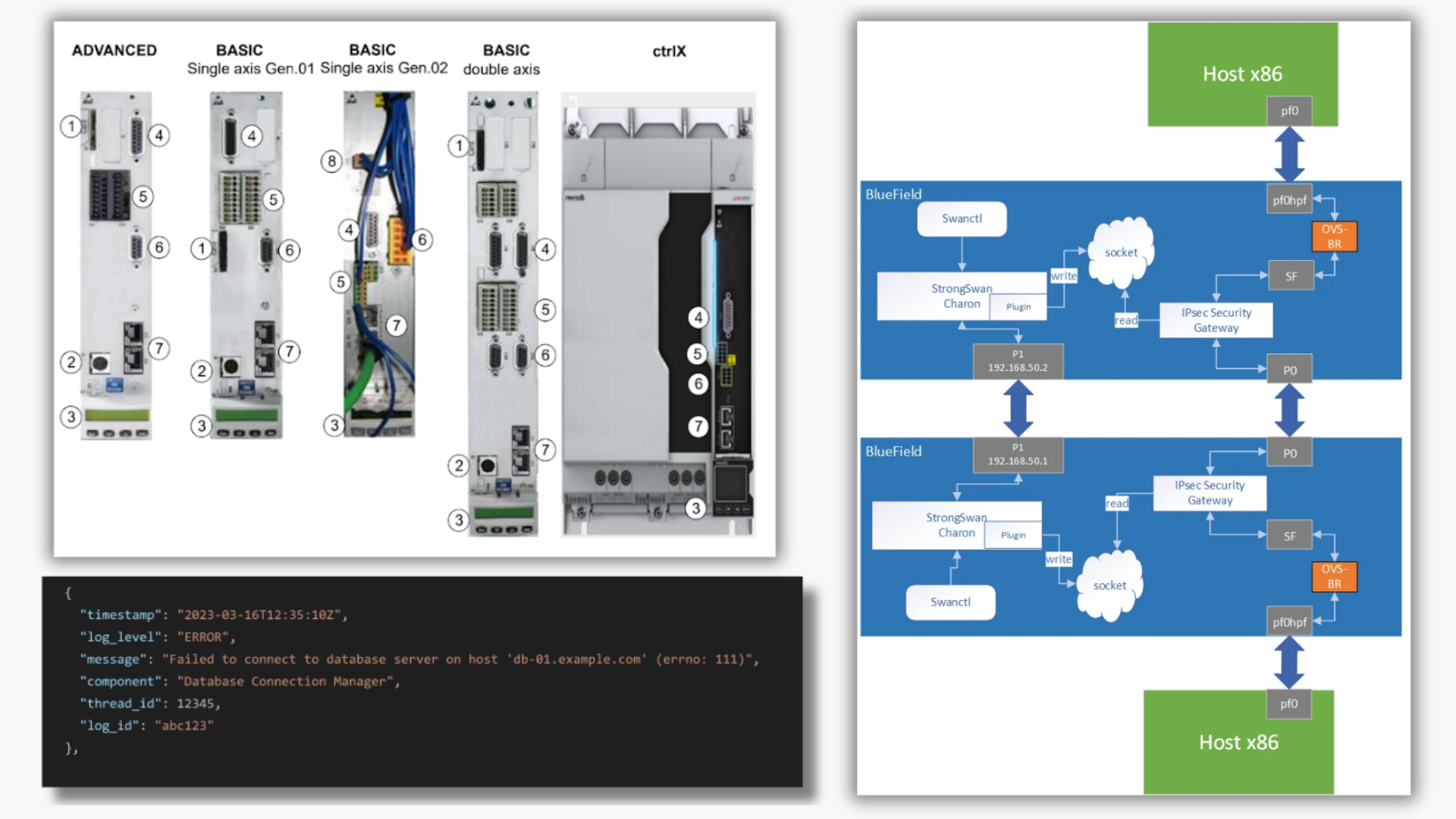
This process of technical diagnostics is an iterative one. Engineers often need to work backward from the issue, going through a series of individual components–across multiple hardware and software layers–to find the root cause. Each component has different utility, and serves a specific purpose in a larger system architecture. The iterative process involves looking up information about these components, judging whether the behavior in the logs matches the expected behavior, identifying alternatives in case of unexpected behavior, and then making decisions.
Giving subject matter experts conversational access to case-specific information saves time and energy, enabling them to focus on applying their technical expertise. This translates to cost savings associated with reducing down-time and increasing efficiency. This scenario is a common one, whether in a factory with a halted production floor or an IT facility experiencing network issues.
Copilot for financial analysis
A financial analyst spends a significant amount of time combing through reports, accounting statements, market data, macroeconomic trends, and more to assess the outlook for a business. More specifically, consider an analyst covering NVIDIA who is assessing the latest earnings results. This analyst will likely review the transcript and press releases, CFO commentaries, the 10-K and 10-Q reports, the quarterly presentations, and their results from their own proprietary models stored in structured databases.
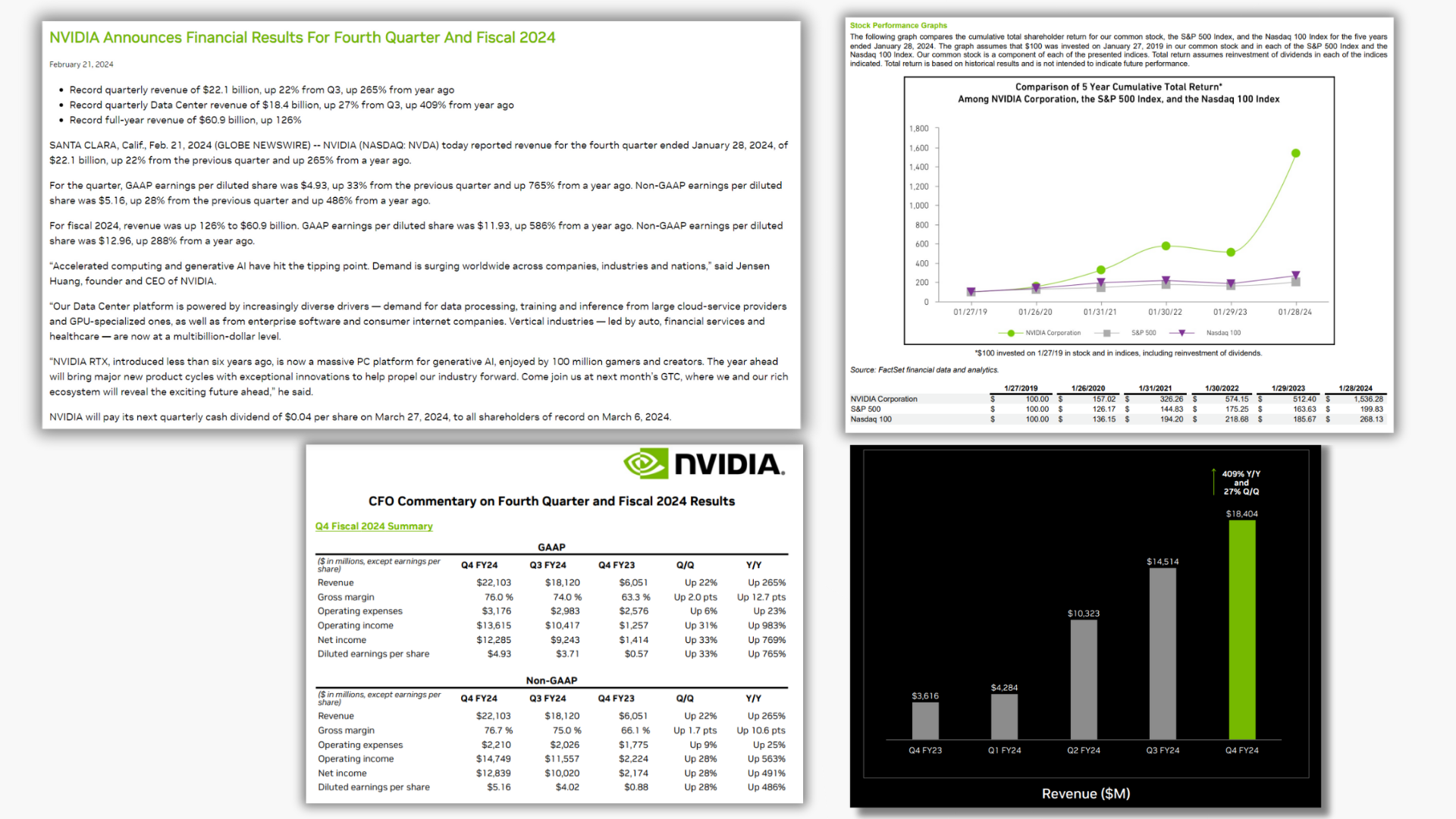
The financial analyst might ask questions such as:
- “What were the key takeaways from NVIDIA’s latest quarter?”
- “How much has NVIDIA’s free cash flow changed in the past nine months?”
- “How has NVDA performed compared to the S&P 500?”
These are basic prerequisite background questions an analyst may spend considerable time researching. The data needed to answer these questions is often found by referencing multiple reports across different quarters, extracting information from different cash flow tables. By streamlining the process of extracting data across multiple sources, the analyst can focus on their key revenue generation task: writing a report containing their review of the company’s performance.
Enterprise operations
Sales and operations teams require access to data about customer relations, financial transactions, and product inventory. They also leverage a multitude of reports around market trends, competitive landscape, and financial analysis which are compiled to make business decisions.
Additionally, SKU catalogs, vendor information, subject matter expert reviews, and other items are often needed as references when diving deeper into specifics. This data is often contained in organizational silos, in dashboards, or with individual employees. As a result, it can be underutilized because of fragmentation across sources.
Revenue is a key performance indicator for sales teams. Finding the correct information requires navigating multiple data sources. Whether the team is planning for the next quarter, educating and empowering customers, or closing deals, a unified conversational interface for accessing relevant information helps streamline processes and enables sellers to focus their expertise on revenue-generating tasks.
Summary
Like many use cases, those presented in this post require access to information spread across various modalities and datastores to make a system that can simplify answering complex business questions. NeMo Retriever maximizes ease of use, reliability, and performance of the necessary infrastructure to enable users to “talk to their data.”
You can try the NeMo Retriever microservices through the NVIDIA API catalog. To get started building applications that use retrieval-augmented generation, explore NVIDIA Generative AI Examples. To learn how to move your RAG application from pilot to production, see How to Take a RAG Application from Pilot to Production in Four Steps.
1Source: IDC, Global DataSphere Forecast, 2023
