
As large language models (LLMs) continue to gain traction in enterprise AI applications, the demand for custom models that can understand and integrate specific industry terminology, domain expertise, and unique organizational requirements becomes increasingly important.
To address this growing need for customizing LLMs, the NVIDIA NeMo team has announced an early access program for NeMo Customizer, a high-performance, scalable microservice that simplifies the fine-tuning and alignment of LLMs.
Tuning generative AI with NeMo Customizer
Enterprises can tap into NVIDIA NeMo from anywhere. The end-to-end platform for developing custom generative AI includes tools for training, fine-tuning, retrieval-augmented generation (RAG), guardrailing, and data curation, along with pretrained models. It has offerings across the tech stack, from frameworks to higher-level API endpoints.
The NeMo Customizer microservice is a set of such API endpoints built on top of the NeMo framework to provide the easiest path for enterprises to get started with fine-tuning LLMs, thereby facilitating a fast, cost-effective way to adopt generative AI.
Customization techniques available in early access
The microservice initially supports two of the popular parameter-efficient fine-tuning techniques: low-rank adaptation (LoRA) and P-tuning.
LoRA
With the LoRA technique, the original model parameters are frozen and injected with trainable rank decomposition matrices. This reduces the number of trainable parameters by a factor of 10K, and GPU requirements by a factor of three. Several small LoRA modules can be trained for different tasks, eliminating the need to create several fine-tuned models. NeMo also provides the option to merge the trainable matrices with the original weights if the user considers it necessary.
P-tuning
P-tuning enables enterprise application developers to add new task capabilities to LLMs without overwriting or disrupting the previous tasks that LLMs have learned.
For this customization technique, the LLM parameters are frozen, and a long short-term memory (LSTM) or multi-layered perceptron (MLP) model called a prompt encoder is trained to predict virtual token embeddings. These virtual tokens do not represent any vocabulary of LLMs and are purely learned for tuning purposes.
Full alignment techniques
In addition to these parameter-efficient fine-tuning techniques, the NeMo Customizer microservice will add support for full alignment techniques in the future, including:
- Supervised fine-tuning (SFT)
- Reinforcement learning from human feedback (RLHF)
- Direct preference optimization (DPO)
- NeMo SteerLM
Meanwhile, the NeMo-Aligner GitHub repo is available for those eager to try full model alignment today. This is also part of the NeMo framework container in the NGC catalog.
Benefits of NeMo Customizer
NeMo Customizer simplifies LLM customization by leveraging the quickly deployable microservices, accelerates training performance using parallelism techniques, and scales to multi-GPU and multinodes. Furthermore, you can download and deploy these microservices anywhere, ensuring flexibility and control over development processes while maintaining data security.
Faster time to market
Leverage the familiarity of microservices and API architecture to accelerate development cycles and bring products to market faster.
These microservices provide flexibility and interoperability and can seamlessly integrate into existing workflows as APIs, regardless of the underlying technologies being used.
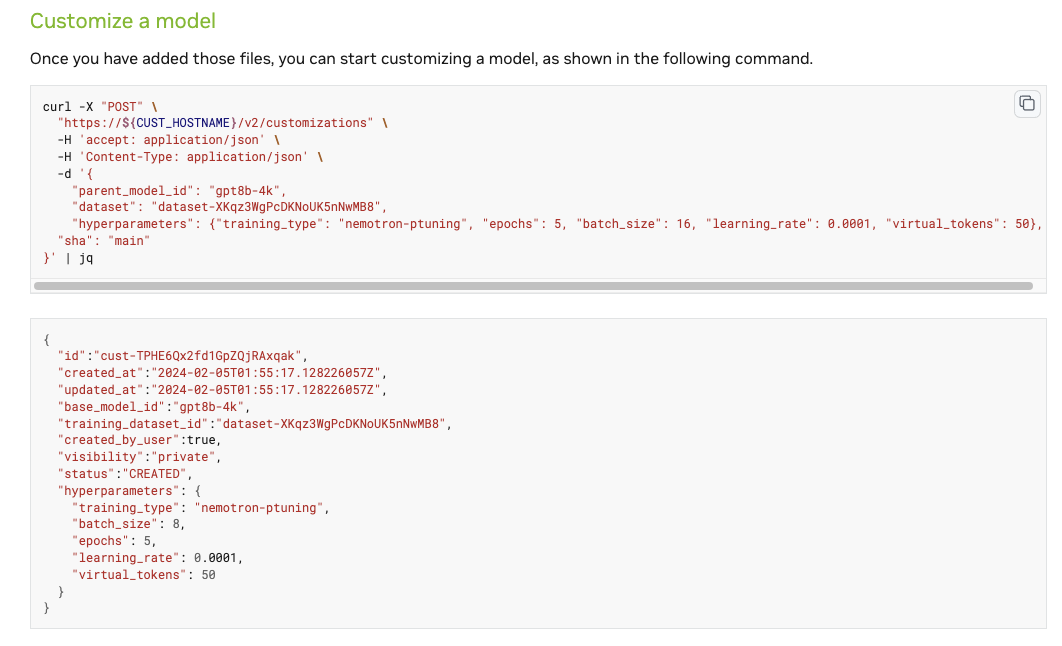
Figure 1 shows the sample cURL command and the response from the NeMo Customizer microservice.
Accelerated performance and scalability
Taking advantage of several parallelism techniques reduces the training time required for these LLMs. Larger models can be trained, as it supports multi-GPU and multinode architecture. These methods operate together to enhance the training process, thus ensuring optimal use of resources and improved training performance.
Customize anywhere
You can download NeMo Customizer microservice and run it on your preferred infrastructure, which means you’re not tied to any specific provider. This gives you more freedom and control over your development setup.
Infrastructure flexibility is a huge advantage for enterprises dealing with sensitive data because they can maintain tighter control and security by keeping everything on-premises. This guarantees sensitive information stays protected from potential risks or breaches that could occur on external platforms.
For example, as explained in Protecting Sensitive Data and AI Models with Confidential Computing, “Customer financial data in banking environments must be kept confidential and secure. Examples of activities that generate sensitive and personally identifiable information (PII) include credit card transactions, medical imaging or other diagnostic tests, insurance claims, and loan applications.”
Furthermore, NeMo Customizer microservice supports Kubernetes with access to an NFS-like file system and volcano scheduler. This enables batch scheduling capability that is commonly required for high-performance multinode fine-tuning of LLMs.
Sign up for early access
As part of the NeMo microservices early access program, you can request access to the NVIDIA NeMo Curator and NVIDIA NeMo Evaluator microservices. These provide data curation and automatic assessment of custom generative AI models across academic and custom benchmarks on any cloud or data center. Together, these microservices enable enterprises to easily build enterprise-grade custom generative AI and bring solutions to market faster.
To get started, apply for NeMo Customizer early access. Applications will be reviewed and a link to access the microservice container will be sent upon approval.
