
Mixture of experts (MoE) large language model (LLM) architectures have recently emerged, both in proprietary LLMs such as GPT-4, as well as in community models with the open-source release of Mistral Mixtral 8x7B. The strong relative performance of the Mixtral model has raised much interest and numerous questions about MoE and its use in LLM architectures. So, what is MoE and why is it important?
A mixture of experts is an architectural pattern for neural networks that splits the computation of a layer or operation (such as linear layers, MLPs, or attention projection) into multiple “expert” subnetworks. These subnetworks each independently perform their own computation, the results of which are combined to create the final output of the MoE layer. MoE architectures can be either dense, meaning that every expert is used in the case of every input, or sparse, meaning that a subset of experts is used for every input.
This post focuses primarily on the application of MoE in LLM architectures. To learn more about applying MoE in other domains, see Scaling Vision with Sparse Mixture of Experts, Mixture-of-Expert Conformer for Streaming Multilingual ASR, and FEDformer: Frequency Enhanced Decomposed Transformer for Long-term Series Forecasting.
Mixture of experts in LLM architectures
This section provides some background information and highlights the benefits of using MoE in LLM architectures.
Model capacity
Model capacity can be defined as the level of complexity that a model is capable of understanding or expressing. Generally, models with larger numbers of parameters (when sufficiently trained) have historically proven to have larger capacity.
How does MoE factor into capacity? Models with more parameters generally have greater capacity, and MoE models can effectively increase capacity relative to a base model by replacing layers of the model with MoE layers in which the expert subnetworks are the same size as the original layer.
Researchers have investigated the accuracy of MoE models against fully dense models of similar size trained on the same amount of tokens (MoE size: E*P parameters compared to fully dense size: EP parameters). The fully dense models generally outperform, although this is still an active area of research. For more details, see Unified Scaling Laws for Routed Language Models.
This raises the question, why not just use a dense model? The answer here lies in sparse MoE, and specifically the fact that sparse MoEs are more flop-efficient per parameter used.
Consider Mixtral 8x7B, a model that uses eight-expert MoE, where only two experts are used for each token. In this case, in any given forward pass of a single token within the model, the number of parameters used for any given token in a batch is much lower (12 billion parameters used of a total 46 billion parameters). This requires less compute compared to using all eight experts or a similarly-sized fully dense model. Given that tokens are batched together in training, most if not all experts are used. This means that in this regime, a sparse MoE uses less compute and the same amount of memory capacity compared to a dense model of the same size.
In a world in which GPU hours are a highly coveted resource, training a fully dense model over a massive scale is prohibitively expensive in terms of both time and cost. The Llama 2 set of models (fully dense) trained by Meta reportedly spent 3.3 million NVIDIA A100 GPU hours in pretraining. To put this in context, 3.3 million GPU hours on 1,024 GPUs at full capacity with no downtime would take approximately 134 days. This does not account for any experimentation, hyperparameter sweeps, or training interruptions.
MoE trains larger models while reducing cost
MoE models help reduce cost by being more flop-efficient per weight, meaning that under regimes with fixed time or compute cost constraints, more tokens can be processed and the model can be further trained. Given that models with more parameters need more samples to fully converge, this essentially means that we can train better MoE models than dense models on a fixed budget.
MoE provides decreased latency
With large prompts and batches where computation is the bottleneck, MoE architecture can be used to deliver decreased first-token serving latency. Latency decreases are made even more important as use cases like retrieval-augmented generation (RAG) and autonomous agents may require many calls to the model, compounding single-call latency.
How do MoE architectures work?
Two key components contribute to MoE models. First, the “expert” subnetworks that compose the mixture, which are used for both dense and sparse MoE. Second, the routing algorithm used by sparse models to determine which experts process which tokens. In some formulations for dense and sparse MoE, the MoE may include a weighting mechanism that is used to perform a weighted average of expert outputs. For the purpose of this post, we will focus on the sparse case.
In many published papers, the MoE technique is applied to Multi-Layer Perceptrons (MLPs) within transformer blocks. In this case, the MLP within the transformer block is usually replaced with a set of expert MLP subnetworks, the results of which are combined to produce the MLP MoE output using averaging or summation.
Research has also suggested that the concept of MoE can be extrapolated to other parts of the transformer architecture. The recent paper SwitchHead: Accelerating Transformers with Mixture-of-Experts Attention suggests that MoE can also be applied to the projection layers that transform inputs into Q, K, and V matrices to be consumed by the attention operation. Other papers have proposed the application of the conditional execution MoE concept to the attention heads themselves.
Routing networks (or algorithms) are used to determine which of the experts are activated in the case of a particular input. Routing algorithms can vary from simple (uniform selection or binning across average values of tensors) to complex, as explained in Mixture-of-Experts with Expert Choice Routing.
Among many factors that determine the applicability of a given routing algorithm to a problem, two core factors are often discussed: model accuracy under a specific routing regime and load balancing under a specific regime. Choosing the right routing algorithm can be a trade-off between accuracy and flop efficiency. A perfectly load-balanced routing algorithm might reduce the accuracy per token, while the most accurate routing algorithm might unevenly distribute tokens between experts.
Many proposed routing algorithms are designed to maximize model accuracy while minimizing the bottleneck presented by any given expert. While Mixtral 8x7B uses a Top-K algorithm to route tokens, papers such as Mixture-of-Experts with Expert Choice Routing introduce concepts to ensure that experts are not overly routed to. This prevents the formation of bottlenecks.
Experimenting with the Mixtral model
In practice, what does each expert learn? Do they specialize in low-level lingual constructs, such as punctuation, verbs, adjectives, and so forth, or are they the masters of high-level concepts and domains, such as coding, math, biology, and law?
To this end, we designed an experiment using the Mixtral 8x7B model. This model has 32 sequential transformer blocks, wherein each MLP layer is replaced with a sparse MoE block with eight experts, of which only two are activated for each token. The remaining layers, including self-attention and normalization layers, are shared by all the tokens.
It is worth noting that when reading the name 8x7B, one could imagine the experts being eight separate full networks, each of 7 billion parameters, and each token is fully processed end-to-end by one of these eight full networks (Figure 1). This design would yield an 8x7B = 56B model.
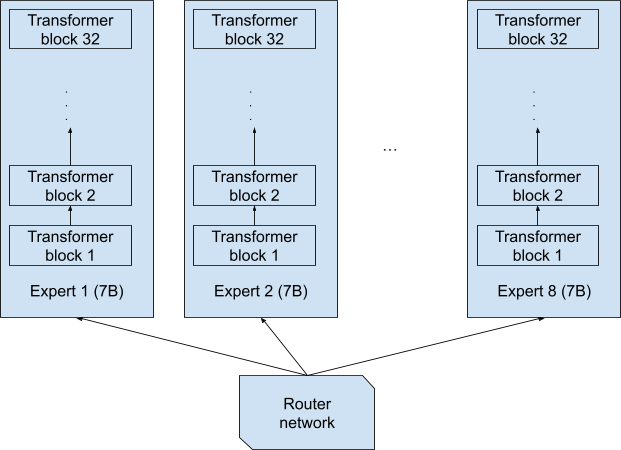
While this is certainly a plausible design, it wasn’t the one used in Mixtral 8x7B. The actual design is depicted in Figure 2, with each token processed by 7 billion parameters. Note that a token and its copy (which is processed by the second-picked expert at each layer) is processed by only 12.9 billion parameters in total, not 2x7B = 14B. And the whole network is only 47 billion, not 8x7B = 56B parameters, due to the shared layers.
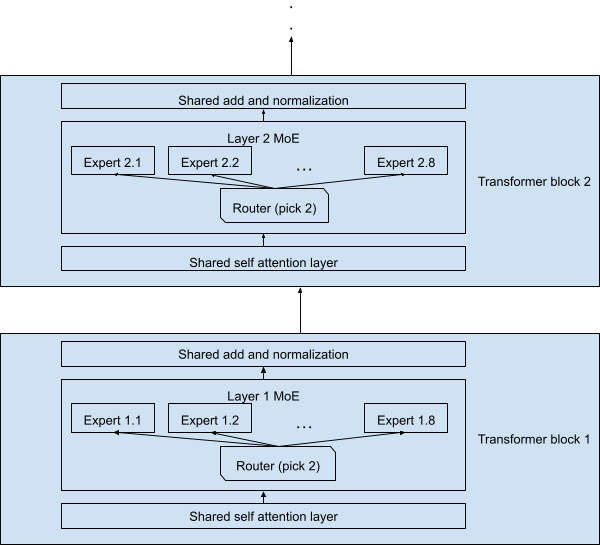
Therefore, each of the tokens passing through the network must go through a lattice-like structure, with \(\binom{8}{2} = 28\) possible combinations of two experts at each layer. Mixtral 8x7B has 32 transformer blocks, thus there are a total of \(28^{32}\) possible instantiations of the network.
If we consider each of these instantiations as a “full-stack expert” (one that processes a token end to end), is it possible to find out what expertise they offer? Unfortunately, since 28^{32} is a really large number (~2×10^{46}), which is orders upon orders of magnitude larger than all the data used to train LLMs (~3T to 10T tokens for most LLMs), rarely will any two tokens be processed by the same instantiation. Thus, we will study what each layer expert specializes on as opposed to each full expert combination.
Experimental results
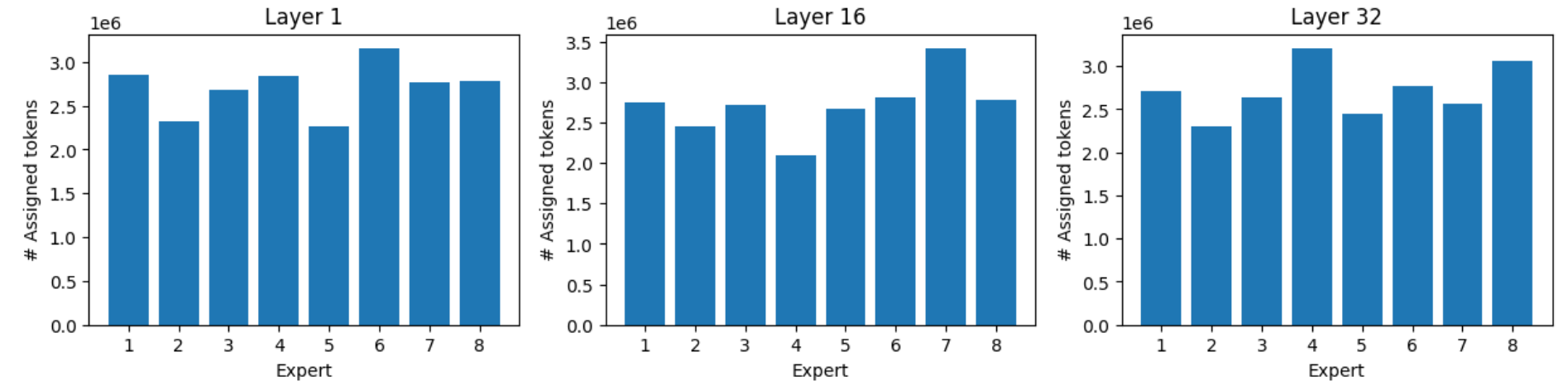
We ran all the samples of the Massive Multitask Language Understanding (MMLU) benchmark through the model. This includes multiple-choice questions on 57 topics, as diverse as abstract algebra, world religions, professional law, anatomy, astronomy, and business ethics, to name a few. We recorded the token-expert assignment for each of the eight experts on layers 1, 16, and 32.
Upon parsing the data, several observations are worth noting.
Load balancing
Thanks to load balancing, the experts receive equalized loads, yet the most busy expert still receives up to 40–60% more tokens than the least busy one.
Domain-expert assignment
Some domains activate some experts more than others.
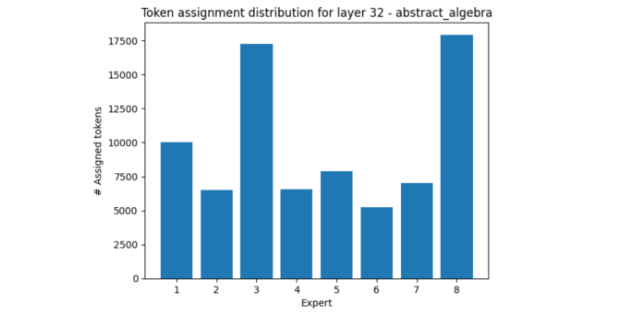
In layer 32, one such example is abstract algebra, which makes use of experts three and eight much more than others.
The area of professional law, on the other hand, mostly activates expert four while muting experts three and eight, relatively.
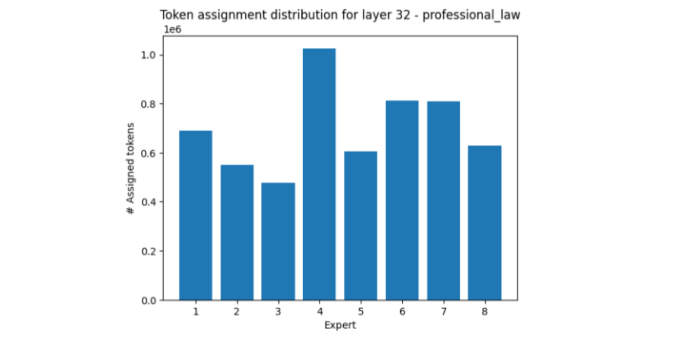
World religions is another fascinating example, in that expert seven receives more than 5x less tokens than expert eight.
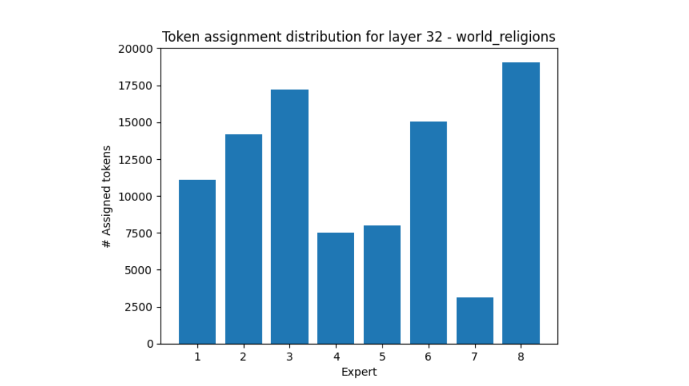
These experimental results show that the experts’ load distribution tends towards uniformity across a diverse range of topics. However, when samples all fall exclusively under a certain topic, there could be a large distributional imbalance.
Most preferred tokens by experts
The word cloud in Figure 7 shows which tokens were most frequently processed by each expert.

Most preferred experts by tokens
Does each token have a preferred expert? Each token seems to have a more preferred set of experts, as the following examples show.
Expert assignment for token “:” , all “:” tokens are processed by experts one and seven in layer one, and experts three and eight in layer 32 (Figure 8). Figures 9, 10, and 11 show the expert assignment for various tokens.
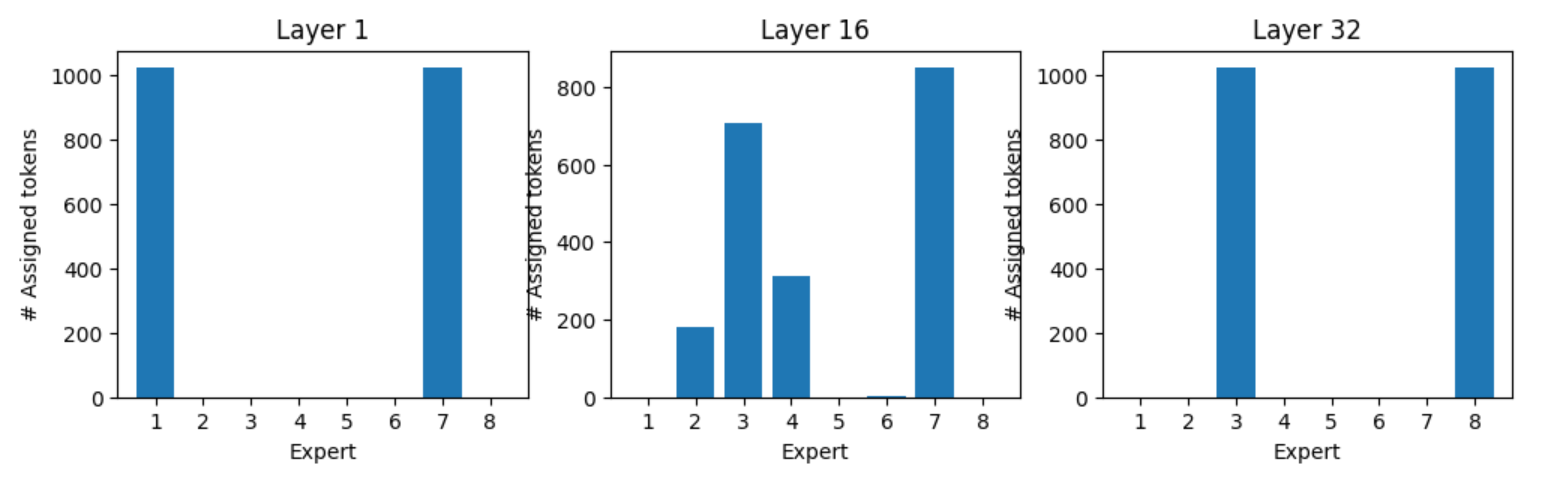
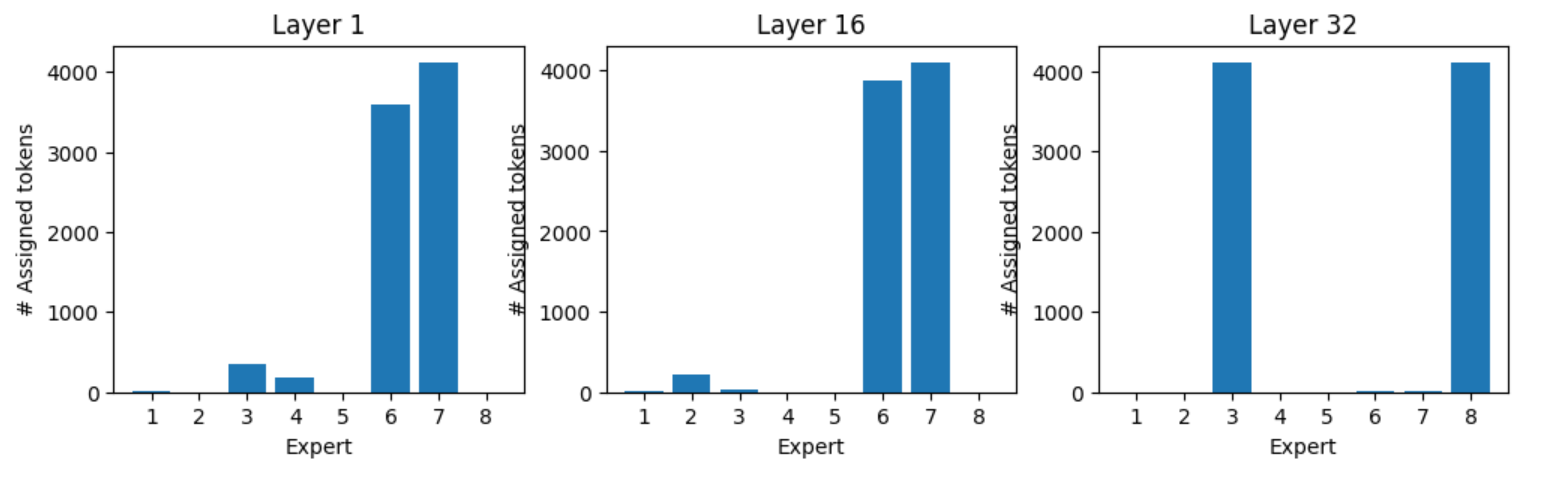
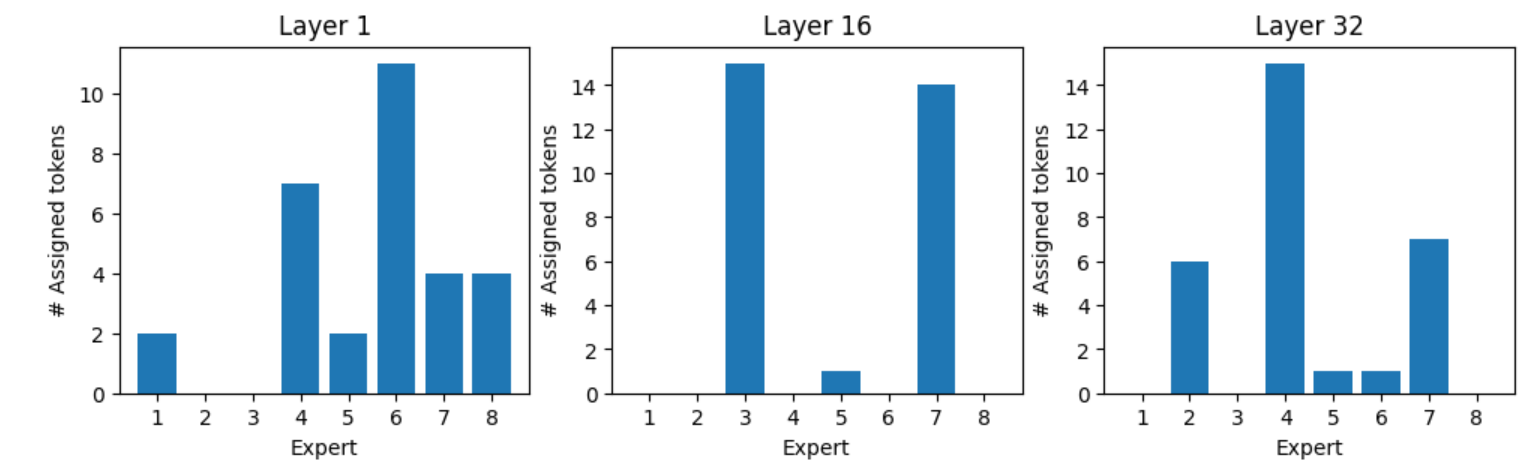
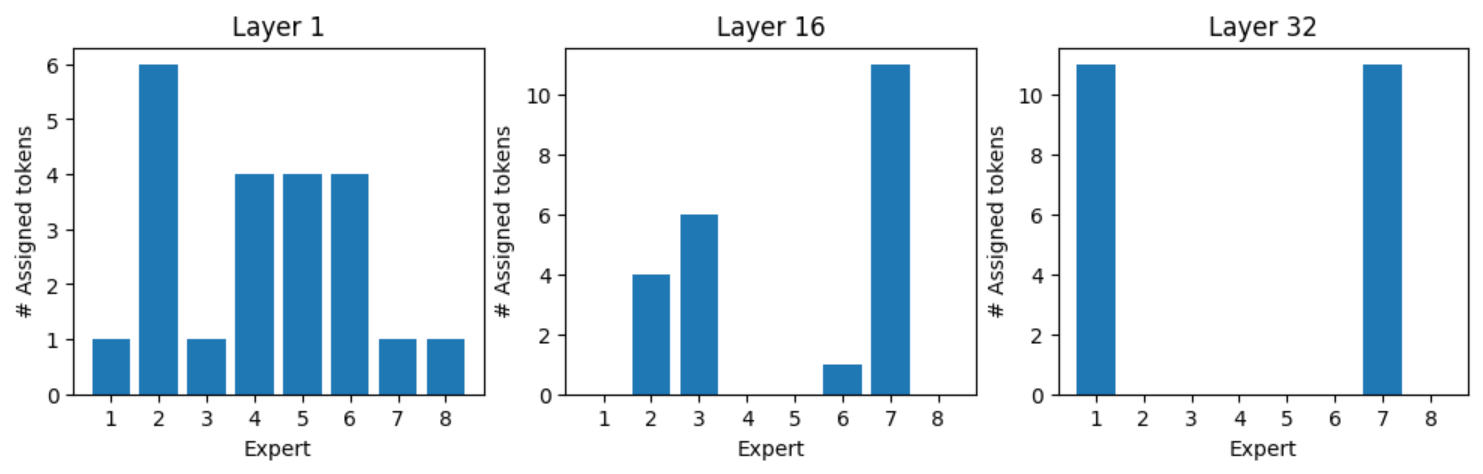
Summary
MoE models provide demonstrable benefits to model pretraining throughput, enabling a more expressive sparse MoE model to be trained on the same amount of compute as a dense model. This leads to more competitive models under the same compute budget. MoE models can target the entire network, or specific layers within the existing network. Generally, sparse MoE with routing is applied to ensure that only some experts are used.
Our experiments explore how tokens are assigned and the relative load balance between experts. These experiments show that despite the load-balancing algorithm, there could still be large distributional imbalances, potentially affecting inference inefficiency, as some experts finish their work early while others are overloaded. This is an interesting area of active research.
You can try Mixtral 8x7B Instruct, as well as other AI models on build.nvidia.com.
Want to learn more? Don’t miss the panel session, Mistral AI: Frontier AI in Your Hands from NVIDIA GTC.
Learn how NVIDIA Blackwell NVL72 runs 10x faster and delivers 1/10 the token cost for MoE models in this blog.
