
NVIDIA NeMo, an end-to-end platform for developing multimodal generative AI models at scale anywhere—on any cloud and on-premises—recently released Parakeet-TDT. This new addition to the NeMo ASR Parakeet model family boasts better accuracy and 64% greater speed over the previously best model, Parakeet-RNNT-1.1B.
This post explains Parakeet-TDT and how to use it to generate highly accurate transcriptions with a high real-time factor, processing 10 minutes of audio in a single second.
Parakeet-TDT model overview
Parakeet-TDT (Token-and-Duration Transducer) is a novel sequence modeling architecture developed by NVIDIA. Recent research confirms the superior speed and recognition accuracy of TDT models over conventional Transducers of similar sizes. For more details, see Efficient Sequence Transduction by Jointly Predicting Tokens and Durations.
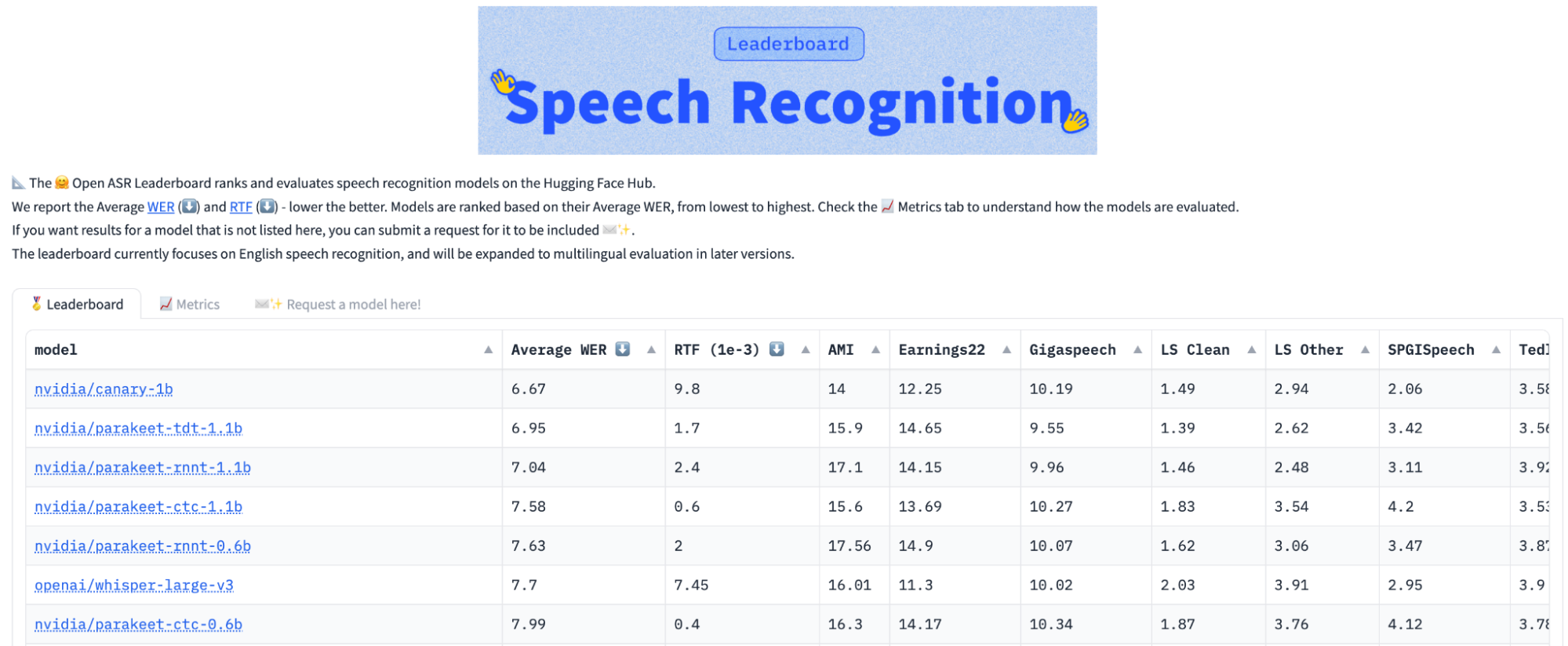
To put things in perspective, Parakeet-TDT with 1.1 billion parameters outperforms similar-sized Parakeet RNNT 1.1B in accuracy while running 64% faster, measured as the average performance among nine benchmarks on the Hugging Face Leaderboard.
Notably, Parakeet-TDT was the first model to achieve an average word error rate (WER) below 7.0 on the Hugging Face open ASR leaderboard (Figure 1). Its real-time factor (RTF) is 40% faster than the Parakeet RNNT 0.6B RTF, despite Parakeet RNNT 0.6B being about half the model size.
Understanding Token-and-Duration Transducer models
TDT models represent a significant advancement over traditional Transducer models by drastically reducing wasteful computations during the recognition process. To grasp this improvement, this section delves into the workings of a typical Transducer model.
A Transducer model consists of an encoder, decoder, and joiner (Figure 2). During speech recognition, the encoder processes audio signals, extracting crucial information from each frame. The decoder extracts information from already predicted text. The joiner then combines the outputs from the encoder and decoder, and predicts a text token for each audio frame.
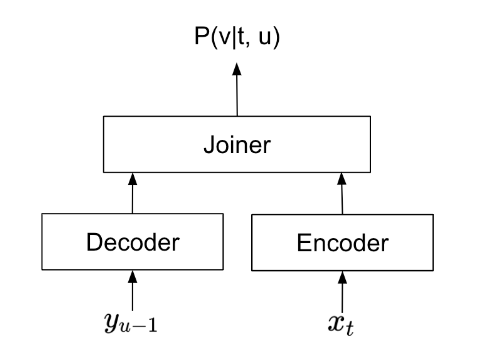
From the joiner’s perspective, a frame typically covers 40 to 80 milliseconds of audio signal, while on average people speak a word per 400 milliseconds. Certain frames don’t associate with any text output due to this discrepancy. For those frames, the Transducer would predict a “blank” symbol. A typical sequence of predictions of a Transducer is shown below:
“_ _ _ _ NVIDIA _ _ _ _ is _ _ _ a _ _ great _ _ _ _ _ place _ _ _ _ to work _ _ _”
Here, ’_’ represents the blank symbol. To generate the final recognition output, the model would delete all the blanks, and generate the output:
“NVIDIA is a great place to work”
The numerous blank symbols in the original output show that the Transducer model wasted a lot of time on “blank frames,” or frames for which the model predicts blanks that don’t contribute to the final output.
TDT is designed to mitigate wasted computation by intelligently detecting and skipping blank frames during recognition. As shown in Figure 3, when a TDT model processes a frame, it simultaneously predicts the following:
- Token probability \(P_T(v|t, u)\) is the token that should be predicted at the current frame.
- Duration probability of duration \(P_D(d|t, u)\) is the number of frames the current token lasts before the model can make the next token prediction.
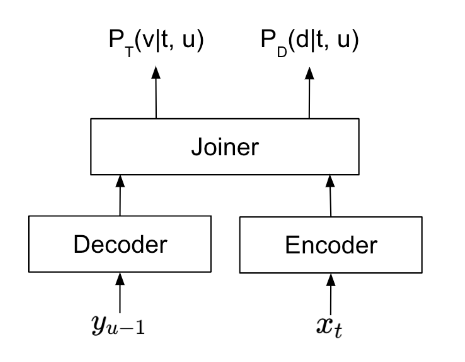
The TDT model is trained to maximize the number of frames skipped using the duration prediction, while maintaining the same recognition accuracy. In the previous example, unlike a conventional Transducer that predicts a token for every speech frame, the TDT model can simplify the process as follows:
frame 1: predict token=_, duration=4
frame 5: predict token=NVIDIA, duration=5
frame 10: predict token=is, duration=4
frame 14: predict token=a, duration=3
frame 17: predict token=great, duration=6
frame 23: predict token=place, duration=5
frame 28: predict token=to, duration=1
frame 29: predict token=work, duration=4
frame 33: reach the end of audio, recognition completed.
In the example, TDT can reduce the number of predictions the model has to make from 33 to eight. Extensive experiments with TDT models demonstrated that this optimization indeed leads to a substantial acceleration in recognition speed. In addition, TDT models exhibit enhanced robustness to noisy speech and token repetitions in the text compared to traditional Transducer models.
Note that this post simplifies certain aspects of Transducer models to better illustrate the design differences between Transducers and TDT. For more technical details, see Efficient Sequence Transduction by Jointly Predicting Tokens and Durations.
How to use Parakeet-TDT
To run speech recognition with Parakeet-TDT, you’ll need to install NVIDIA NeMo. It can be installed as a pip package, as shown below. Cython and PyTorch (2.0 and above) should be installed before trying to install NeMo.
pip install nemo_toolkit['asr']
Once NeMo is installed, you can use Parakeet-TDT to recognize your audio files as follows:
import nemo.collections.asr as nemo_asr
asr_model = nemo_asr.models.ASRModel.from_pretrained(model_name="nvidia/parakeet-tdt-1.1b")
transcript = asr_model.transcribe(["some_audio_file.wav"])
Conclusion
Parakeet-TDT, the latest addition to the NeMo Parakeet ASR models family, sets a new benchmark by coupling superior accuracy with unprecedented speed, epitomizing efficiency in speech recognition.
To learn more about the architecture behind the Parakeet-TDT ASR model, see Efficient Sequence Transduction by Jointly Predicting Tokens and Durations, Fast Conformer with Linearly Scalable Attention for Efficient Speech Recognition, and Investigating End-to-End ASR Architectures for Long Form Audio Transcription.
Parakeet-CTC is now available in the latest release of NeMo ASR. Other models will be available soon as part of NVIDIA Riva. Visit NVIDIA/NeMo on GitHub to access the Parakeet-TDT model locally. You can also experience speech and translation AI models through the NVIDIA API catalog and run them on-premises with NVIDIA NIM. NVIDIA LaunchPad provides the necessary hardware and software stacks on private hosted infrastructure for additional exploration.
