
Generative AI has become a transformative force of our era, empowering organizations spanning every industry to achieve unparalleled levels of productivity, elevate customer experiences, and deliver superior operational efficiencies.
Large language models (LLMs) are the brains behind generative AI. Access to incredibly powerful and knowledgeable foundation models, like Llama and Falcon, has opened the door to amazing opportunities. However, these models lack the domain-specific knowledge required to serve enterprise use cases.
Developers have three choices for powering their generative AI applications:
- Pretrained LLMs: the easiest lift is to use foundation models, which work very well for use cases that rely on general-purpose knowledge.
- Custom LLMs: pretrained models customized with domain-specific knowledge, and task-specific skills, connected to enterprises’ knowledge bases perform tasks and provide responses based on the latest proprietary information.
- Develop LLMs: organizations with specialized data (for example, models catering to regional languages) cannot use pretrained foundation models and must build their models from scratch.
NVIDIA NeMo is an end-to-end, cloud-native framework for building, customizing, and deploying generative AI models. It includes training and inferencing frameworks, guardrails, and data curation tools, for an easy, cost-effective, and fast way to adopt generative AI.
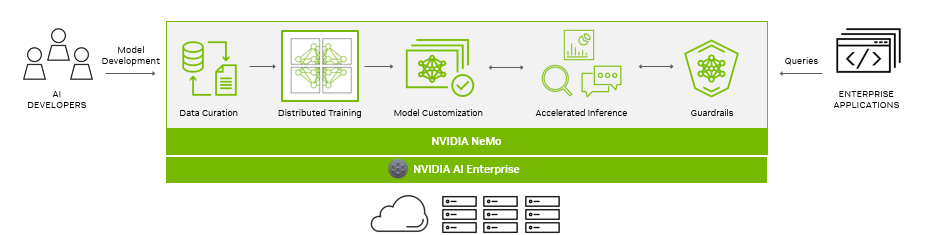
As generative AI models and their development continue to progress, the AI stack and its dependencies become increasingly complex. For enterprises running their business on AI, NVIDIA provides a production-grade, secure, end-to-end software solution with NVIDIA AI Enterprise.
Organizations are running their mission-critical enterprise applications on Google Cloud, a leading provider of GPU-accelerated cloud platforms. NVIDIA AI Enterprise, which includes NeMo and is available on Google Cloud, helps organizations adopt generative AI faster.
Building a generative AI solution requires that the full stack, from compute to networking, systems, management software, training, and inference SDKs work in harmony.
At Google Cloud Next 2023, Google Cloud announced the general availability of their A3 instances powered by NVIDIA H100 Tensor Core GPUs. Engineering teams from both companies are collaborating to bring NeMo to the A3 instances for faster training and inference.
In this post, we cover training and inference optimizations developers can enjoy while building and running their custom generative AI models on NVIDIA H100 GPUs.
Data curation at scale
The potential of a single LLM achieving exceptional outcomes across diverse tasks is due to training on an immense volume of Internet-scale data.
NVIDIA NeMo Data Curator facilitates the handling of trillion-token multilingual training data for LLMs. It consists of a collection of Python modules leveraging MPI, Dask, and a Redis cluster to scale tasks involved in data curation efficiently. These tasks include data downloads, text extractions, text reformatting, quality filtering, and removal of exact or fuzzy duplicate data. This tool can distribute these tasks across thousands of computational cores.
Using these modules aids developers in swiftly sifting through unstructured data sources. This technology accelerates model training, reduces costs through efficient data preparation, and yields more precise results.
Accelerated model training
NeMo employs distributed training using sophisticated parallelism methods to use GPU resources and memory across multiple nodes on a large scale. By breaking down the model and training data, NeMo enables optimal throughput and significantly reduces the time required for training, which also speeds up TTM.
H100 GPUs employ NVIDIA Transformer Engine (TE), a library that enhances AI performance by combining 16-bit and 8-bit floating-point formats with advanced algorithms. It achieves faster LLM training without losing accuracy by reducing math operations to FP8 from the typical FP16 and FP32 formats used in AI workloads. This optimization uses per-layer statistical analysis to increase precision for each model layer, resulting in optimal performance and accuracy.
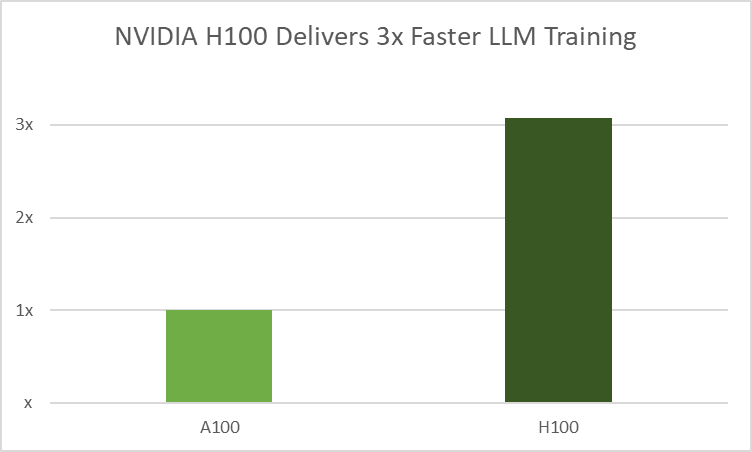
AutoConfigurator delivers developer productivity
Finding model configurations for LLMs across distributed infrastructure is a time-consuming process. NeMo provides AutoConfigurator, a hyperparameter tool to find optimal training configurations automatically, enabling high throughput LLMs to train faster. This saves developers time searching for efficient model configurations.
It applies heuristics and grid search techniques to various parameters, such as tensor parallelism, pipeline parallelism, micro-batch size, and activation checkpointing layers, aimed at determining configurations with the highest throughputs.
AutoConfigurator can also find model configurations that achieve the highest throughput or lowest latency during inference. Latency and throughput constraints can be provided to deploy the model, and the tool will recommend suitable configurations.
Review the recipes for building generative AI models of various sizes for GPT, MT5, T5, and BERT architectures.
Model customization
In the realm of LLMs, one size rarely fits all, especially in enterprise applications. Off-the-shelf LLMs often fall short in catering to the distinct requirements of the organizations, whether it’s the intricacies of specialized domain knowledge, industry jargon, or unique operational scenarios.
This is precisely where the significance of custom LLMs comes into play. Enterprises must fine-tune models that support the capabilities for specific use cases and domain expertise. These customized models provide enterprises with the means to create solutions personalized to match their brand voice and streamline workflows, for more accurate insights, and rich user experiences.
NeMo supports a variety of customization techniques, for developers to use NVIDIA-built models by adding functional skills, focusing on specific domains, and implementing guardrails to prevent inappropriate responses.
Additionally, the framework supports community-built pretrain LLMs including Llama 2, BLOOM, and Bart, and supports GPT, T5, mT5, T5-MoE, and Bert architectures.
- P-Tuning trains a small helper model to set the context for the frozen LLM to generate a relevant and accurate response.
- Adapters/IA3 introduce small, task-specific feedforward layers within the core transformer architecture, adding minimal trainable parameters per task. This makes for easy integration of new tasks without reworking existing ones.
- Low-Rank Adaption uses compact additional modules to enhance model performance on specific tasks without substantial changes to the original model.
- Supervised Fine-tuning calibrates model parameters on labeled data of inputs and outputs, teaching the model domain-specific terms and how to follow user-specified instructions.
- Reinforcement Learning with Human Feedback enables LLMs to achieve better alignment with human values and preferences.
Learn more about various LLM customization techniques.
Accelerated inference
Community LLMs are growing at an explosive rate, with increased demand from companies to deploy these models into production. The size of these LLMs is driving the cost and complexity of deployment higher, requiring optimized inference performance for production applications. Higher performance not only helps decrease costs but also improves user experiences.
LLMs such as LLaMa, BLOOM, ChatGLM, Falcon, MPT, and Starcoder have demonstrated the potential of advanced architectures and operators. This has created a challenge in producing a solution that can efficiently optimize these models for inference, something that is highly desirable in the ecosystem.
NeMo employs MHA and KV cache optimizations, flash attention, quantized KV cache, and paged attention, among other techniques to solve the large set of LLM optimization challenges. It enables developers to try new LLM and customize foundation models for peak performance without requiring deep knowledge of C++ or NVIDIA CUDA optimization.
NeMo also leverages NVIDIA TensorRT deep learning compiler, pre- and post-processing optimizations, and multi-GPU multi-node communication. In an open-source Python API, it defines, optimizes, and executes LLMs for inference in production applications.
NeMo Guardrails
LLMs can be biased, provide inappropriate responses, and hallucinate. NeMo Guardrails is an open-source, programmable toolkit for addressing these challenges. It sits between the user and the LLM, screening and filtering inappropriate user prompts as well as LLM responses.
Building guardrails for various scenarios is straightforward. First, define a guardrail by providing a few examples in natural language. Then, define a response when a question on that topic is generated. Lastly, define a flow, which dictates the set of actions to be taken when the topic or the flow is triggered.
NeMo Guardrails can help the LLM stay focused on topics, prevent toxic responses, and make sure that replies are generated from credible sources before they are presented to users. Read about building trustworthy, safe, and secure LLM conversational systems.
Simplify deployment with ecosystem tools
NeMo works with MLOps ecosystem technologies such as Weights & Biases (W&B) providing powerful capabilities for accelerating the development, tuning, and adoption of LLMs.
Developers can debug, fine-tune, compare, and reproduce models with the W&B MLOps platform. W&B Prompts help organizations understand, tune, and analyze LLM performance. W&B integrates with Google Cloud products commonly used in ML development.
The combination of NeMo, W&B, and Google Cloud is on display at the NVIDIA booth at Google Cloud Next.
Fuel generative AI applications
Writer, a leading generative AI-based content creation service, is harnessing NeMo capabilities and accelerated compute on Google Cloud. They’ve built up to 40B parameter language models that now cater to hundreds of customers, revolutionizing content generation.
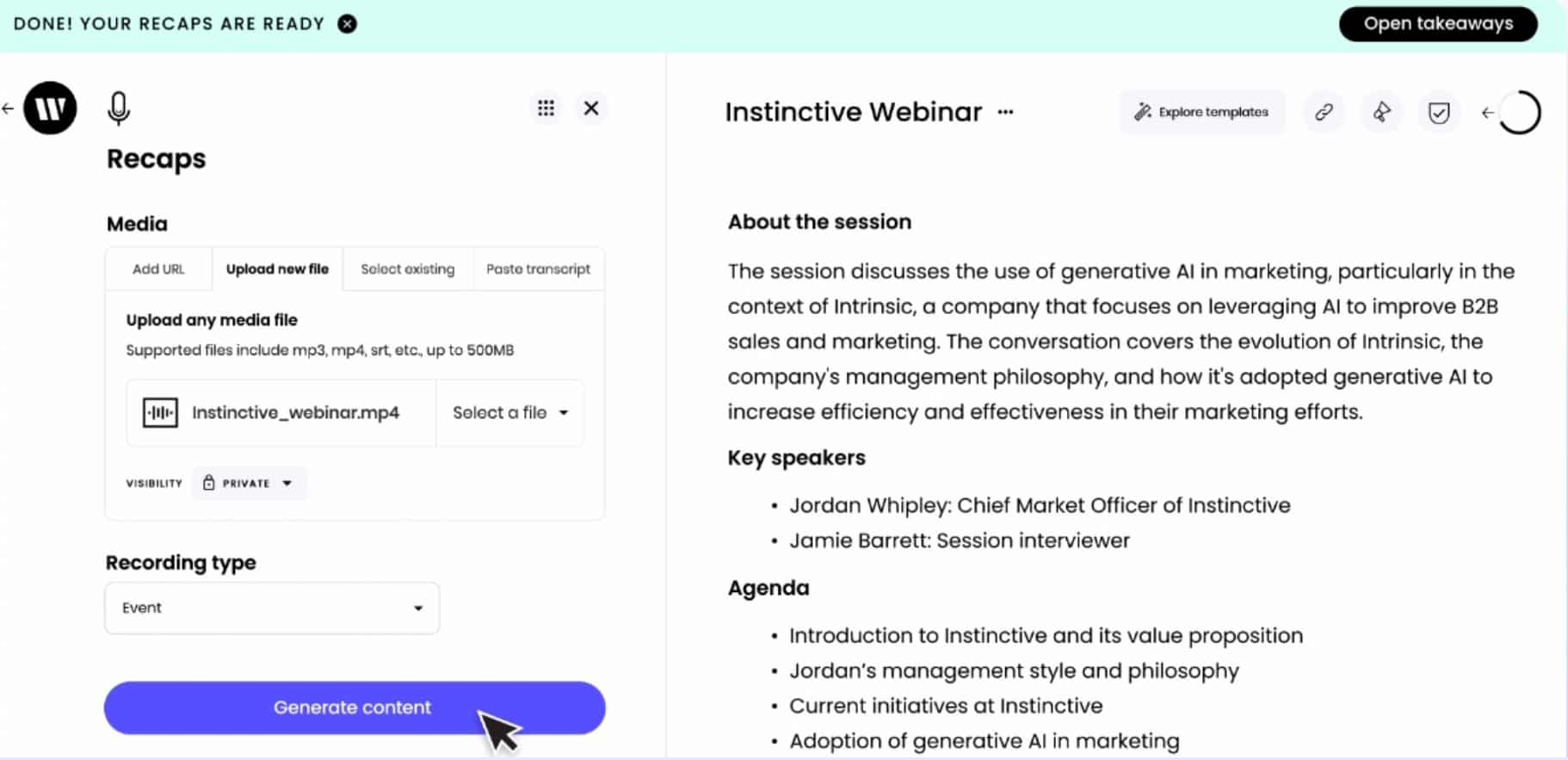
Figure 4. The Writer Recap tool creates written summaries from audio recordings of an interview or event
APMIC is another success story with NeMo at its core. With a dual focus, they leverage NeMo for two distinct use cases. They’ve supercharged their contract verification and verdict summarization processes through entity linking, extracting vital information from documents quickly. They are also using NeMo to customize GPT models, offering customer service and digital human interaction solutions by powering question-answering systems.
Start building your generative AI application
Using AI playground, you can experience the full potential of community and NVIDIA-built generative AI models, optimized for the NVIDIA accelerated stack, directly through your web browser.
Customize GPT, mT5, or BERT-based pretrained LLMs from Hugging Face using NeMo on Google Cloud:
- Access NeMo from GitHub.
- Pull the NeMo container from NGC to run across GPU-accelerated platforms.
- Access NeMo from NVIDIA AI Enterprise available on Google Cloud Marketplace with enterprise-grade support and security.
Get started with NVIDIA NeMo today.
