在快速发展的环境中,生成人工智能的发展对加速推理速度的需求仍然是一个紧迫的问题。随着模型规模和复杂性的指数级增长,对快速生成结果以同时服务于众多用户的需求也在持续增长。NVIDIA 平台站在这一努力的前沿,通过芯片、系统、软件和算法等全技术堆栈的创新,实现永久的性能飞跃。
NVIDIA 正在扩展其推理产品 NVIDIA TensorRT 模型优化器,一个集成了最先进的后期训练和环中训练模型优化技术的综合库。这些技术包括量化和稀疏性,旨在降低模型复杂性,以实现更高效的下游推理库,如 NVIDIA TensorRT LLM,从而更有效地优化深度学习模型的推理速度。
作为 NVIDIA TensorRT 生态系统的一部分,NVIDIA TensorRT 模型优化器(简称模型优化器)可用于多种流行的体系结构,包括 NVIDIA Hopper、NVIDIA Ampere 和 NVIDIA Ada Lovelace 等。
模型优化器为 PyTorch 和 ONNX 模型生成模拟量化检查点。这些量化检查点已准备好无缝部署到 TensorRTLLM 或 TensorRT,并即将支持其他流行的部署框架。模型优化器 Python API 使开发人员能够堆叠不同的模型优化技术,以在 TensorRT 中现有的运行时和编译器优化的基础上加速推理。
量化技术
训练后量化(PTQ)是减少内存占用和加速推理的最流行的模型压缩方法之一。虽然其他一些量化工具包仅支持仅限权重的量化或基本技术,但 Model Optimizer 提供高级校准算法,包括 INT8 SmoothQuant 和 INT4 AWQ(激活感知权重量化)。如果您正在使用 FP8 或更低的精度,例如 TensorRT LLM 中的 INT8 或 INT4,您已经在幕后利用 Model Optimizer 的 PTQ 了。
在过去的一年里,Model Optimizer 的 PTQ 已经让无数 TensorRT LLM 用户能够 在保持模型准确性的同时,为 LLM 实现显著的推理加速。此外,通过 INT4 AWQ,Falcon 180B 可以安装在单个 NVIDIA H200 GPU 上。图 1 展示了用户可以在 Llama 3 模型上使用 Model Optimizer PTQ 实现的推理加速结果。
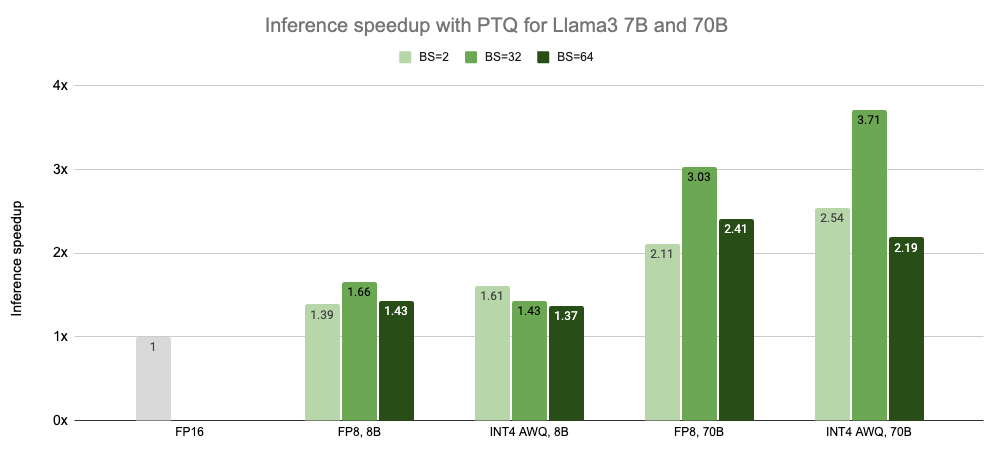
在不使用批处理的情况下测量的延迟,速度标准化为每个 GPU 的计数。
在没有量化的情况下,即使在 NVIDIA A100 Tensor Core GPU 上,模型的计算速度仍然会影响最终用户的体验。幸运的是,来自 Model Optimizer 的领先的 8 位(INT8 和 FP8)后训练量化技术已经在 TensorRT 的框架下使用扩散部署管道 和 Stable Diffusion XL NIM,以加快图像生成。
在最新的 MLPerf 推理 v4.0 中,模型优化器进一步增强了 TensorRT,使 Stable Diffusion XL 的性能高于所有替代方法。通过这项 8 位量化功能,许多生成型人工智能公司能够在保持模型质量的情况下,以更快的推理速度提供用户体验。
要查看 FP8 和 INT8 的端到端示例,请访问 NVIDIA/TensorRT-Model-Optimizer 和NVIDIA/TensorRT 在 GitHub 上。根据校准数据集的大小,扩散模型的校准过程通常只需几分钟。对于 FP8,我们在 RTX 6000 Ada 上观察到 1.45 倍的加速,而在没有 FP8 MHA 的 L40S 上观察到 1.35 倍的速度提升。表 1 显示了 INT8 和 FP8 量化的补充基准结果。
| GPU | INT8 延迟(ms) | FP8 延迟(ms) | 加速(INT8 与 FP16) | 加速(FP8 与 FP16) |
| RTX 6000 Ada | 2, 479 | 2, 441 | 1.43 倍 | 1.45 倍 |
| RTX 4090 | 2, 058 | 2, 161 | 1.20 倍 | 1.14 倍 |
| L40S | 2, 339 | 2, 168 | 1.25 倍 | 1.35 倍 |
| H100 80GB HBM3 | 1, 209 | 1, 216 | 1.08 倍 | 1.07 倍 |
配置:稳定扩散 XL 1.0 基本型号。图像分辨率为 1024×1024 像素;30 步。TensorRT v9.3。批量大小为 1

为下一代平台实现超低精度推理
最近宣布的 NVIDIA Blackwell 平台 凭借其 4 位浮点人工智能推理能力,为计算新时代提供动力。模型优化器在保证模型质量的同时,在实现 4 位推理方面发挥着关键作用。当模型转向 4 位推理时,训练后量化通常会导致模型精度的显著下降。
为了解决这一问题,模型优化器为开发人员提供量化感知训练(QAT),以在不影响准确性的情况下以 4 位的速度完全解锁推理。通过在训练过程中计算缩放因子,并将模拟的量化损失纳入微调过程,QAT 使神经网络对量化更有弹性。
Model Optimizer QAT 工作流程旨在与领先的培训框架集成,包括 NVIDIA NeMo、Megatron-LM 和 Hugging Face transformers API。这为开发人员提供了在各种框架中利用 NVIDIA 平台功能的选项。如果您想在 NVIDIA Blackwell 平台可用之前开始使用 QAT,请 遵循 INT4 QAT 示例,并与 Hugging Face transformers API 进行集成。
我们的研究表明,即使 QAT 仅应用于监督微调(SFT)阶段而不是预训练阶段,QAT 也可以在低精度下获得比 PTQ 更好的性能。这意味着 QAT 可以以低训练成本应用,使对精度下降敏感的生成人工智能应用程序能够在不久的将来保持精度,即使在超低精度下,其中权重和激活都是 4 位。
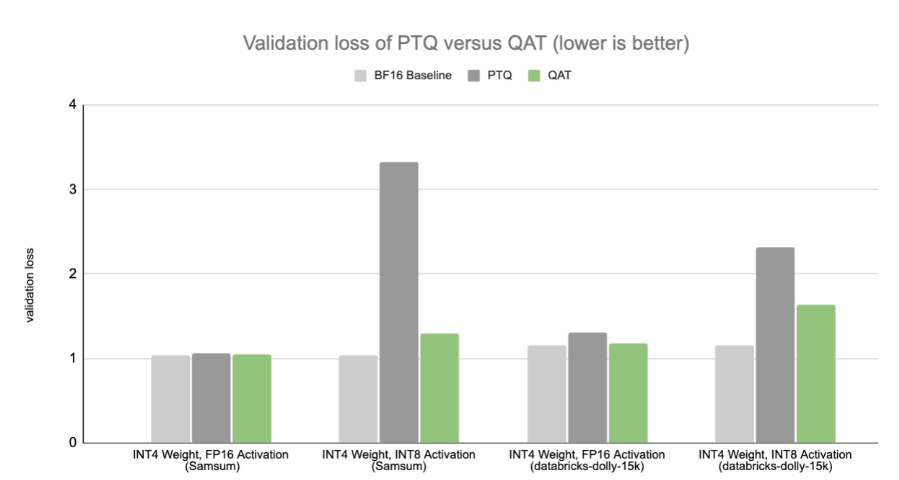
基线模型在目标数据集上进行了微调。请注意,我们在此基准测试中使用 INT4 来演示量化感知训练(QAT)。随着 NVIDIA Blackwell 平台的全面发布,4 位结果将变得可用。
具有稀疏性的模型压缩
传统上,深度学习模型过于密集和参数化。这推动了对另一类模型优化技术的需求。稀疏性通过选择性地鼓励模型参数中的零值来进一步减小模型的大小,这些零值然后可以从存储或计算中丢弃。
基于 Llama 2 70B 的 FP8 量化,模型优化器训练后的稀疏性在批量大小为 32 的情况下提供了额外的 1.62x 加速。这是通过使用 NVIDIA H100 GPU 实现的,该 GPU 采用 NVIDIA Ampere 架构中引入的专有 NVIDIA 2:4 稀疏性。要了解更多信息,请参阅 使用 NVIDIA Ampere 架构和 NVIDIA TensorRT 加速稀疏推理。
在 MLPerf 推理 v4.0 中,TensorRT LLM 利用模型优化器训练后的稀疏性将 Llama 2 70B 模型压缩了 37%。这使得模型和 KV 缓存能够适应单个 H100 GPU 的 GPU 内存,从而将张量并行度从 2 降低到 1。在 MLPerf 中的这一特定摘要任务中,模型优化器成功地保留了稀疏模型的质量,满足了 MLPerf 闭除法设置的 Rouge 分数 99.9% 的准确率目标。
| 模型 | 批量大小 | 推理加速 (与相同批量的 FP8 密集型相比) |
稀疏 Llama 2 70B |
32 | 1.62 倍 |
| 64 | 1.52 倍 | |
| 128 | 1.35 倍 | |
| 896 | 1.30 倍 |
FP8:TP=1,PP=1 适用于所有稀疏化模型。由于权重尺寸较大,密集模型需要 TP=2
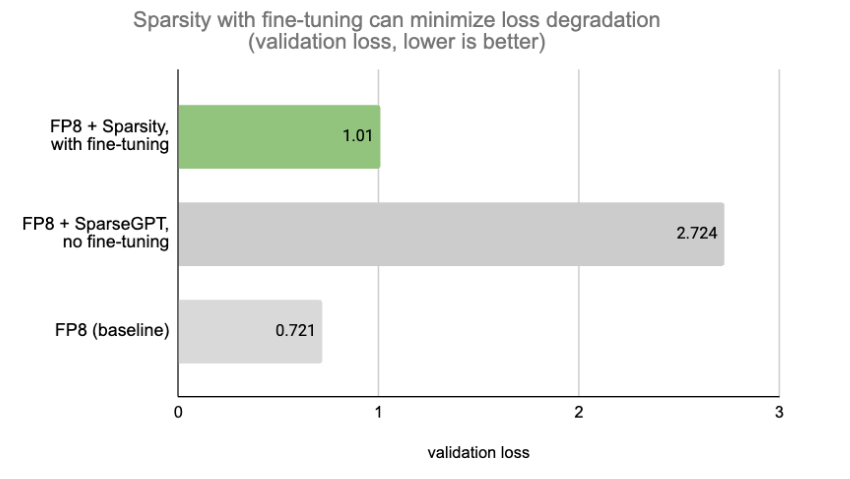
虽然 MLPerf 设置几乎没有精度下降,但在大多数情况下,将稀疏性与微调相结合以保持模型质量是一种常见的做法。Model Optimizer 提供了用于稀疏性感知微调的 API,这些 API 与包括 FSDP 在内的流行并行技术兼容。图 4 显示,使用带有微调的 SparseGPT 可以最大限度地减少损耗退化。
可组合模型优化 API
在模型上应用不同的优化技术,如量化和稀疏性,传统上需要一种非平凡的多级方法。为了解决这一痛点,Model Optimizer 为开发人员提供了可组合的 API,以堆叠多个优化步骤。图 5 中的代码片段演示了如何将稀疏性和量化与 Model Optimizer 可组合 API 相结合。
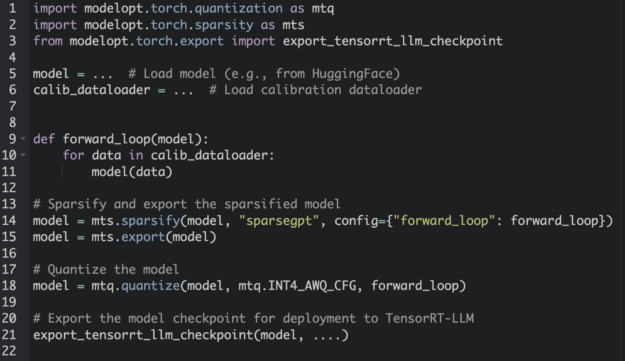
此外,Model Optimizer 还提供了各种有用的功能,如单行 API,用于检索模型状态信息,并为任何需要完全再现性的实验完全恢复模型修改。
开始
现在,您可以在 NVIDIA PyPI 上安装 NVIDIA TensorRT Model Optimizer 作为 nvidia-modelopt。要访问推理优化的示例脚本和配方,请访问 NVIDIA/TensorRT-Model-Optimizer 在 GitHub 上。有关更多详细信息,请参阅 TensorRT 模型优化器文档,以获取更深入的了解。
鸣谢
特别感谢 TensorRT 模型优化器开发背后的敬业工程师,包括 Asma Kuriparambil Thekkumpate、Kai Xu、Lucas Liebenwein、Zhiyu Cheng、Riyad Islam、Ajinkya Rasane、Jingyu Xin、Wei Ming Chen、Shengliang Xu、Meng Xin、Ye Yu、Chen Han Yu、Keval Morabia、Asha Anoosheh 和 James Shen。(名单顺序不反映贡献水平。)




