当涉及到智能视频分析(IVA)应用程序(如交通监控、仓库安全和零售购物者分析)的感知时,最大的挑战之一是闭塞。例如,人们可能会移动到结构障碍物后面,零售购物者可能由于货架单元而无法完全看到,汽车可能会隐藏在大型卡车后面。
本文将解释如何利用 NVIDIA DeepStream SDK 解决现实生活中 IVA 部署中常见的视觉感知遮挡问题。
视觉感知中的视角和投影
在我们的物理世界中,通过相机镜头观察到的一些物体的运动可能看起来不稳定。这是由于相机对 3D 世界的 2D 表示。
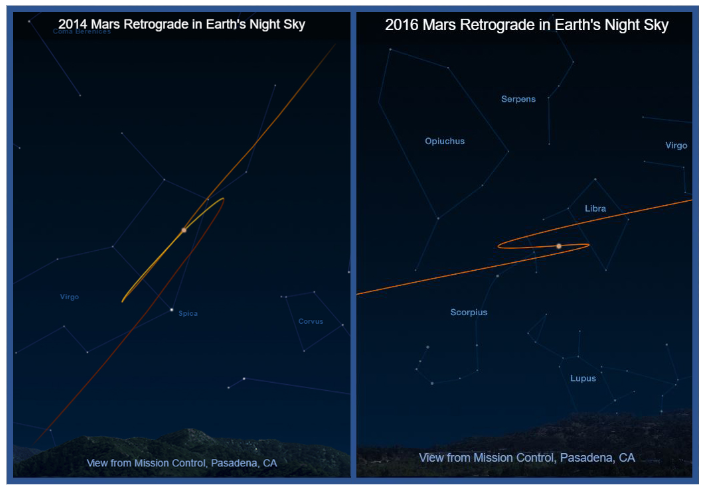
水星和火星等行星的逆行就是一个例子,这让古希腊天文学家感到困惑。他们无法解释为什么行星有时会向后移动(图 1)。
所感知到的明显退行是由于恒星和行星在夜空中的轨迹造成的。这些是宇宙三维空间中轨道运动在夜空二维画布上的投影。如果古代天文学家知道三维空间的运动模式,他们就可以预测这些行星在二维夜空中的出现。
交通监控摄像头提供了类似的例子。这些摄像头通常用于监测大面积区域,其中车辆在近场和远场的运动动力学可能截然不同。
在视频 1 中,远处的车辆显得又小又慢。当车辆靠近摄像头并转弯时,可以观察到物体运动的突然变化。这些变化使得难以在 2D 摄像机视图中找到常见模式,因此难以预测车辆未来可能移动的位置。
物体跟踪本质上是对物体物理状态的连续估计,同时随着时间的推移识别其独特身份。该过程通常包括对物体运动动力学建模,并进行预测以抑制测量(检测)中的固有噪声。给定所提供的示例,很明显,直接在原生 3D 空间中执行对象的状态估计和预测将产生比在投影的 2D 相机图像平面中执行更好的结果。这是因为对象存在于三维空间中。
使用 NVIDIA DeepStream 进行单视图 3D 跟踪
NVIDIA DeepStream SDK 是一个基于 GStreamer 的完整流媒体分析工具包,旨在实现基于人工智能的多传感器处理、视频、音频和图像理解。最近,DeepStream 6.4 版本 引入了一种名为单视图 3D 跟踪(SV3DT)的新功能,该功能能够在单相机视图内估计 3D 物理世界中的对象状态。
该过程包括使用每个相机的 3×4 投影矩阵或相机矩阵将 2D 相机图像平面上的观测测量转换为 3D 世界坐标系。对象在三维世界地平面中的位置表示为对象底部的中心。因此,行人被建模为一个圆柱体(具有高度和半径),站在世界地平面上,圆柱体模型底部的中心作为行人的脚部位置(图 2)。

使用 3×4 投影矩阵和圆柱形人体模型,估计检测到的物体的 3D 人体模型在 3D 世界地平面上的位置,从而使 2D 相机图像平面上的投影 3D 人体模型与检测到的对象的边界框最佳匹配。
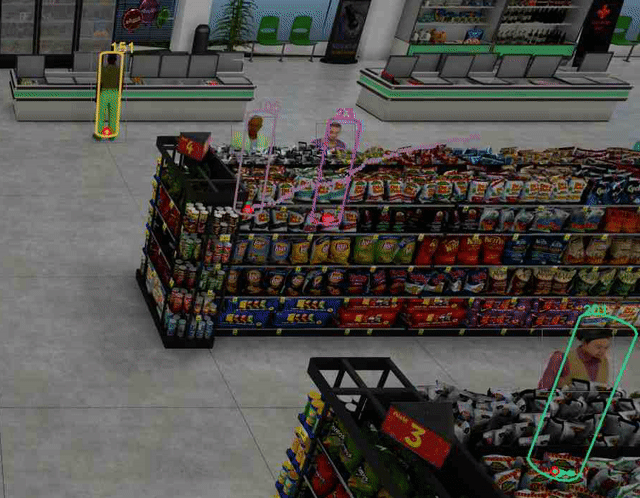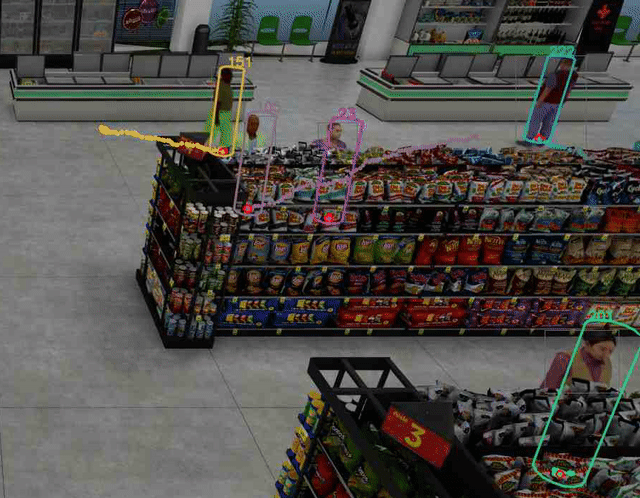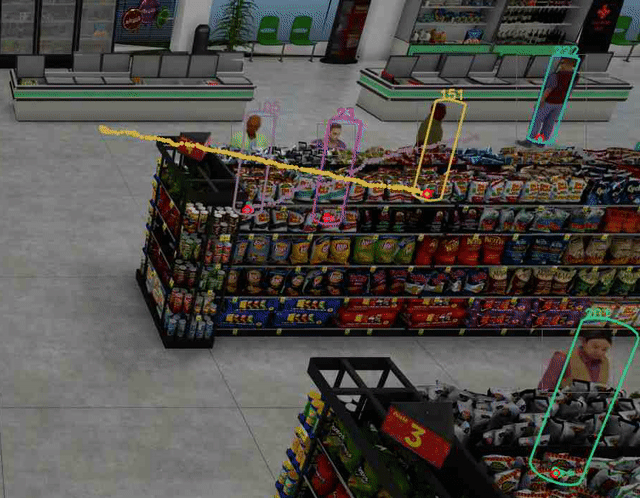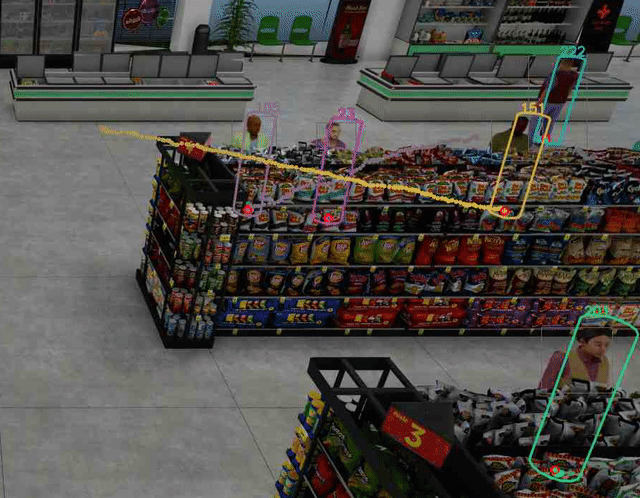
例如,在图 3(左)中,灰色边界框表示对象检测器使用 NVIDIA TAO PeopleNet 模型检测到的对象。紫色和黄色圆柱体指示从 3D 世界地平面上的估计位置投影到 2D 相机图像平面的对应 3D 人体模型。投影的 3D 人体模型底部的绿点指示估计的脚部位置。尽管摄影机视图具有透视和旋转,但这些位置与实际脚部位置非常匹配。

新引入的 DeepStream SV3DT 功能的一个重要优点是,即使存在显著的差异,也可以准确地找到物体的 2D 和 3D 脚部位置,即使在部分闭塞的情况下。这是现实世界 IVA 应用中最具挑战性的问题之一。欲了解更多详细信息,请参阅我们之前的帖子:采用 NVIDIA DeepStream SDK 6.2 的最先进实时多对象跟踪器。
例如,图 3(右)显示了一个人在狭窄的过道里购物,相机只能看到上半身的一小部分。这将导致更小的对象边界框,仅捕获头部和肩部区域。对于这种情况,在全球商店地图上定位此人极具挑战性,因为至少可以说,估计脚部位置是一项不平凡的任务。
使用边界框的底部中心作为对象位置的代理将在轨迹估计中引入很大程度的误差。即使使用相机校准信息将 2D 点转换为 3D 点,尤其是当相机视角和旋转较大时,也是如此。
DeepStream SDK 中的多对象跟踪器模块中的 SV3DT 算法通过在假设相机安装在头部上方的情况下利用 3D 人体建模信息来解决这个问题。这通常是部署在智能空间中的大多数大型相机网络系统的情况。有了这个假设,在估计相应的 3D 人体模型位置时,可以使用头部作为锚点。图 3 显示,即使在人被严重遮挡的情况下,SV3DT 算法也可以成功地找到匹配的三维人体模型位置。
视频 2 显示人们在便利店被跟踪。请注意,使用的 3×4 投影矩阵没有考虑镜头失真,尽管特定相机有一定程度的镜头失真,因为你可以看到水平线有点弯曲而不直。这导致 3D 人体模型位置估计更加不准确,尤其是当人位于视频帧的边缘时。
尽管如此,人们在便利店的 2D 和 3D 脚部位置(用绿点表示)被准确而稳健地跟踪。这增强了额外分析的准确性,如队列长度监控和占用图等。
图 4 显示了如何在合成数据集中稳健地跟踪每个行人的脚部位置,即使下半身的大部分被货架等大型物体遮挡。
我们相信,解决部分遮挡问题将在现实应用中开辟许多可能性。SV3DT 目前处于阿尔法模式,因为其对象类型支持有限(仅限站立的人)。其他情况,如人们坐着和躺着,或其他对象类型可能在未来的版本中得到支持。您可以针对您的特定用例进行尝试,并在 DeepStream 论坛 中提供反馈。我们计划在未来版本中进行进一步改进。
DeepStream SV3DT 用例
一个示例 DeepStream SV3DT 用例演示了如何在本文中介绍的零售商商店视频上启用单视图 3D 跟踪,并从管道中保存 3D 元数据。用户可以从图 4 和视频 2 所示的数据中可视化凸起的船体和脚部位置。该自述还描述了如何在自定义视频上运行此算法。欲了解更多详细信息,请访问 NVIDIA-AI-IOT/deepstream_reference_apps,或参阅 DeepStream 文档。
总结
NVIDIA DeepStream SDK 中的单视图 3D 跟踪有助于缓解现实生活中 IVA 应用程序和部署中的部分遮挡问题。该功能在 6.4 版本中首次引入,并在 7.0 版本中进行了增强。具体而言,SV3DT 能够在局部遮挡的情况下估计脚部位置,并且能够进行更稳健和准确的对象跟踪,这将随后导致在 3D 地平面中的准确定位。依赖或利用地理空间分析的企业预计将从这项技术中受益最大。
要开始,请先查看 DeepStream SDK 发布 的最新消息,然后在充满挑战的环境中尝试。