NVIDIA TensorRT
NVIDIA® TensorRT™ is an ecosystem of tools for developers to achieve high-performance deep learning inference. TensorRT includes inference compilers, runtimes, and model optimizations that deliver low latency and high throughput for production applications. The TensorRT ecosystem includes the TensorRT compiler, TensorRT-LLM, TensorRT Model Optimizer, TensorRT for RTX, and TensorRT Cloud.
How TensorRT Works
Speed up inference by 36X compared to CPU-only platforms.
Built on the NVIDIA® CUDA® parallel programming model, TensorRT includes libraries that optimize neural network models trained on all major frameworks, calibrate them for lower precision with high accuracy, and deploy them to hyperscale data centers, workstations, laptops, and edge devices. TensorRT optimizes inference using quantization, layer and tensor fusion, and kernel tuning techniques.
NVIDIA TensorRT Model Optimizer provides easy-to-use quantization techniques, including post-training quantization and quantization-aware training to compress your models. FP8, FP4, INT8, INT4, and advanced techniques such as AWQ are supported for your deep learning inference optimization needs. Quantized inference significantly minimizes latency and memory bandwidth, which is required for many real-time services, autonomous and embedded applications.

Read the Introductory TensorRT Blog
Learn how to apply TensorRT optimizations and deploy a PyTorch model to GPUs.
Watch On-Demand TensorRT Sessions From GTC
Learn more about TensorRT and its features from a curated list of webinars at GTC.
Get the Complete Developer Guide
See how to get started with TensorRT in this step-by-step developer and API reference guide.
Navigate AI infrastructure and Performance
Learn how to lower your cost per token and get the most out of your AI models with our ebook.
Key Features
Large Language Model Inference
NVIDIA TensorRT-LLM is an open-source library that accelerates and optimizes inference performance of large language models (LLMs) on the NVIDIA AI platform with a simplified Python API.
Developers accelerate LLM performance on NVIDIA GPUs in the data center or on workstation GPUs.
Compile in the Cloud
NVIDIA TensorRT Cloud is a developer-focused service for generating hyper-optimized engines for given constraints and KPIs. Given an LLM and inference throughput/latency requirements, a developer can invoke TensorRT Cloud service using a command-line interface to hyper-optimize a TensorRT-LLM engine for a target GPU. The cloud service will automatically determine the best engine configuration that meets the requirements. Developers can also use the service to build optimized TensorRT engines from ONNX models on a variety of NVIDIA RTX, GeForce, Quadro®, or Tesla®-class GPUs.
TensorRT Cloud is available with limited access to select partners. Apply for access, subject to approval.
Optimize Neural Networks
TensorRT Model Optimizer is a unified library of state-of-the-art model optimization techniques, including quantization, pruning, speculation, sparsity, and distillation. It compresses deep learning models for downstream deployment frameworks like TensorRT-LLM, TensorRT, vLLM, and SGLang to efficiently optimize inference on NVIDIA GPUs. TensorRT Model Optimizer also supports training for inference techniques such as Speculative Decoding Module Training, Pruning/Distillation, and Quantization Aware Training through NeMo and Hugging Face frameworks.
Major Framework Integrations
TensorRT integrates directly into PyTorch and Hugging Face to achieve 6X faster inference with a single line of code. TensorRT provides an ONNX parser to import ONNX models from popular frameworks into TensorRT. MATLAB is integrated with TensorRT through GPU Coder to automatically generate high-performance inference engines for NVIDIA Jetson™, NVIDIA DRIVE®, and data center platforms.
Deploy, Run, and Scale With Dynamo-Triton
TensorRT-optimized models are deployed, run, and scaled with NVIDIA Dynamo Triton inference-serving software that includes TensorRT as a backend. The advantages of using Triton include high throughput with dynamic batching, concurrent model execution, model ensembling, and streaming audio and video inputs.
Simplify AI deployment on RTX
TensorRT for RTX offers an optimized inference deployment solution for NVIDIA RTX GPUs. It facilitates faster engine build times within 15 to 30s, facilitating apps to build inference engines directly on target RTX PCs during app installation or on first run, and does so within a total library footprint of under 200 MB, minimizing memory footprint. Engines built with TensorRT for RTX are cross-OS, cross-GPU portable, ensuring a build once, deploy anywhere workflow.
Accelerate Every Inference Platform
TensorRT can optimize models for applications across the edge, laptops, desktops, and data centers. It powers key NVIDIA solutions—such as NVIDIA TAO, NVIDIA DRIVE, NVIDIA Clara™, and NVIDIA JetPack™—and is integrated with application-specific SDKs, such as NVIDIA NIM™, NVIDIA DeepStream, NVIDIA Riva, NVIDIA Merlin™, NVIDIA Maxine™, NVIDIA Morpheus, and NVIDIA Broadcast Engine.
TensorRT provides developers a unified path to deploy intelligent video analytics, speech AI, recommender systems, video conferencing, AI-based cybersecurity, and streaming apps in production.
Get Started With TensorRT
TensorRT is an ecosystem of APIs for building and deploying high-performance deep learning inference. It offers a variety of inference solutions for different developer requirements.
Use-case |
Deployment Platform |
Solution |
|---|---|---|
Inference for LLMs |
Data center GPUs like GB100, H100, A100, etc. |
Download TRT-LLM |
Inference for non-LLMs like CNNs, Diffusions, Transformers, etc. Safety-compliant and high-performance inference for Automotive Embedded Inference for non-LLMs in robotics and edge applications |
Data center GPUs, Embedded, and Edge platforms Automotive platform: NVIDIA DRIVE AGX Edge Platform: Jetson, NVIDIA IGX, etc. |
Download TensorRT The TensorRT inference library provides a general-purpose AI compiler and an inference runtime that delivers low latency and high throughput for production applications.
|
AI Model Inferencing on RTX PCs |
NVIDIA GeForce RTX and RTX Pro GPUs in laptops and desktops |
Download TensorRT for RTX TensorRT for RTX is a dedicated inference deployment solution for RTX GPUs.
|
Model optimizations like Quantization, Distillation, Sparsity, etc. |
Data center GPUs like GB100, H100, etc.
|
Download TensorRT Model Optimizer |
Get Started With TensorRT Frameworks
TensorRT Frameworks add TensorRT compiler functionality to frameworks like PyTorch.
Download ONNX and Torch-TensorRT
The TensorRT inference library provides a general-purpose AI compiler and an inference runtime that delivers low latency and high throughput for production applications.
ONYX:
Torch-TensorRT:
Experience Tripy: Pythonic Inference With TensorRT
Experience high-performance inference and excellent usability with Tripy. Expect intuitive APIs, easy debugging with eager mode, clear error messages, and top-notch documentation to streamline your deep learning deployment.
Deploy
Get a free license to try NVIDIA AI Enterprise in production for 90 days using your existing infrastructure.
World-Leading Inference Performance
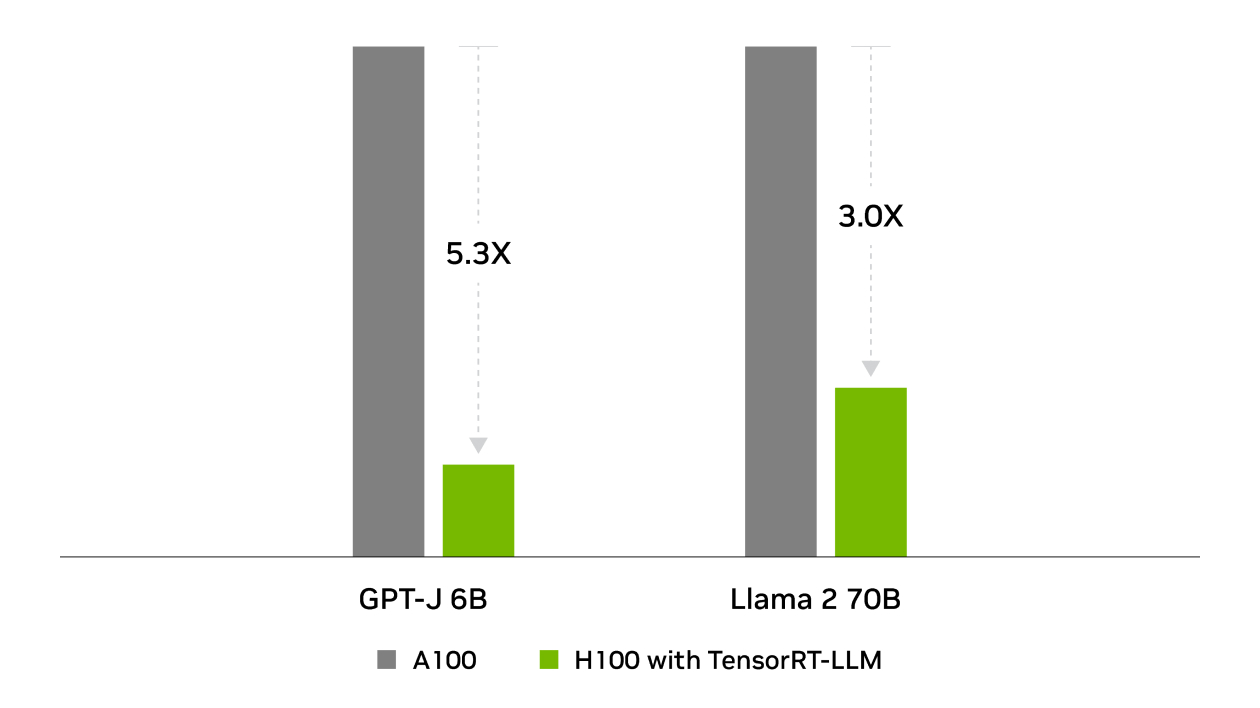
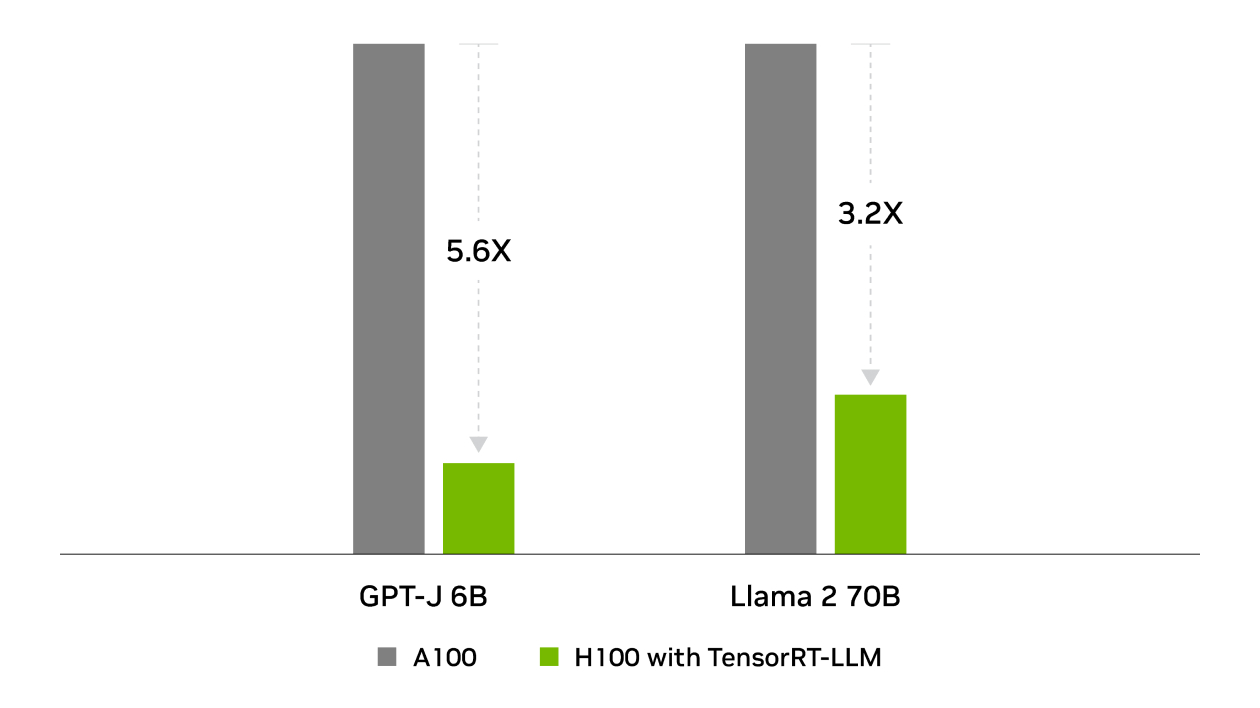
TensorRT was behind NVIDIA’s wins across all inference performance tests in the industry-standard benchmark for MLPerf Inference. TensorRT-LLM accelerates the latest large language models for generative AI, delivering up to 8X more performance, 5.3X better TCO, and nearly 6X lower energy consumption.
See All Benchmarks8X Increase in GPT-J 6B Inference Performance
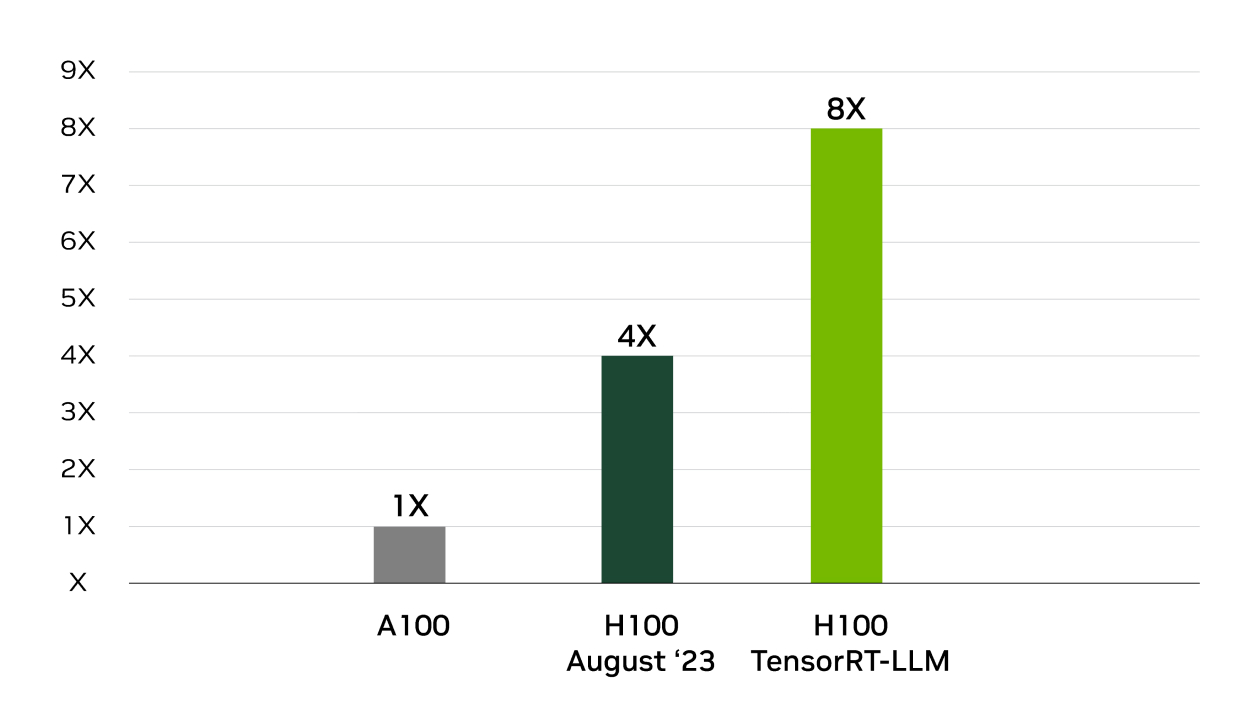
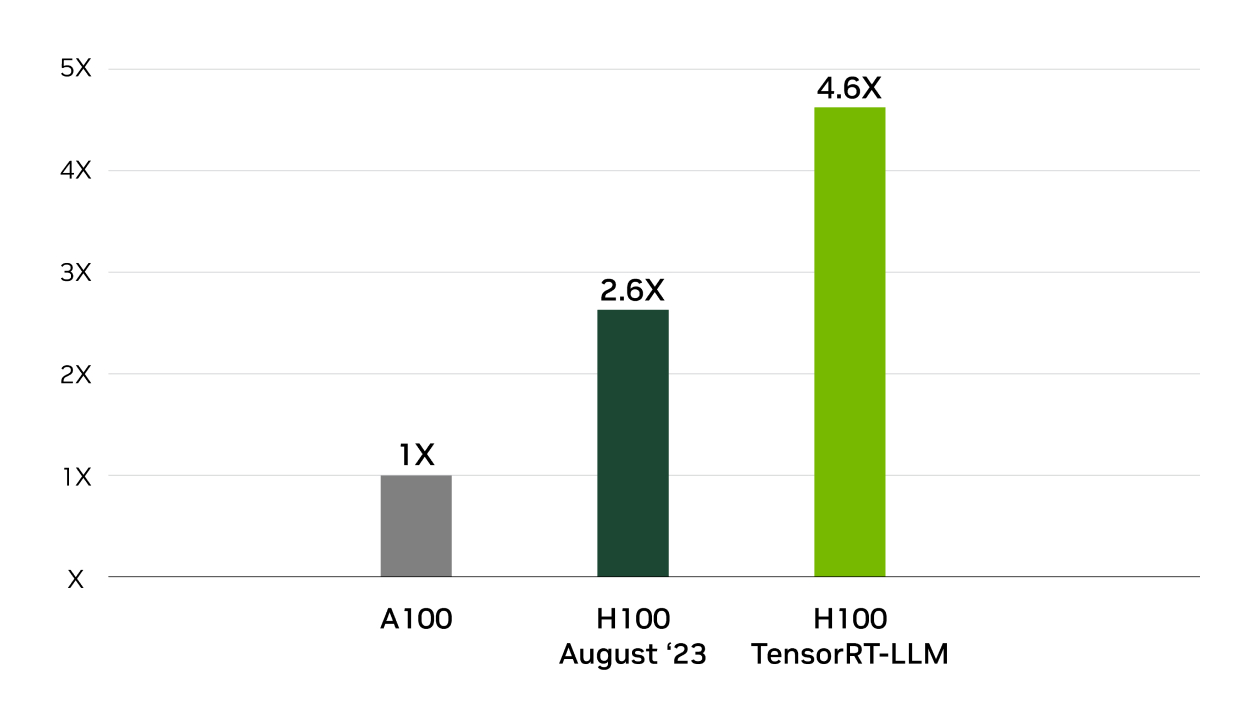
4X Higher Llama2 Inference Performance
Total Cost of Ownership
Energy Use
NVIDIA Blackwell Ultra Delivers up to 50x Better Performance and 35x Lower Cost for Agentic AI
Built to accelerate the next generation of agentic AI, NVIDIA Blackwell Ultra delivers breakthrough inference performance with dramatically lower cost. Cloud providers such as Microsoft, CoreWeave, and Oracle Cloud Infrastructure are deploying NVIDIA GB300 NVL72 systems at scale for low-latency and long-context use cases, such as agentic coding and coding assistants.
This is enabled by deep co-design across NVIDIA Blackwell, NVLink™, and NVLink Switch for scale-out; NVFP4 for low-precision accuracy; and NVIDIA Dynamo and TensorRT™ LLM for speed and flexibility—as well as development with community frameworks SGLang, vLLM, and more.

Starter Kits
Beginner Guide to TensorRT
Watch Video: Getting Started With NVIDIA TensorRT
Beginner Guide to TensorRT-LLM
Watch Video: Getting Started With NVIDIA TensorRT
Beginner Guide to TensorRT Model Optimizer
Beginner Guide to Torch-TensorRT
Watch Video: Getting Started With NVIDIA Torch-TensorRT
Read Blog: Accelerate Inference up to 6X in PyTorch
Download Notebook: Object Detection With SSD (Jupyter Notebook)
Beginner Guide to TensorRT Pythonic Frontend: Tripy
TensorRT Learning Library
Quantization Quickstart
NVIDIA TensorRT-LLM
The PyTorch backend supports FP8 and NVFP4 quantization. Explore GitHub to pass quantized models in the Hugging Face model hub, which are generated by TensorRT Model Optimizer.
Link to GitHub
Link to PyTorch Documentation
Adding a New Model in PyTorch Backend
This guide provides a step-by-step process for adding a new model in PyTorch Backend.
Link to GitHub
Using TensoRT-Model Optimizer for Speculative Decoding
ModelOpt’s Speculative Decoding module enables your model to generate multiple tokens in each generation step. This can be useful for reducing the latency of your model and speeding up inference.
Link to GitHub
TensorRT Ecosystem Ecosystem
Widely Adopted Across Industries
More Resources
{kind=link}
Ethical AI
NVIDIA believes Trustworthy AI is a shared responsibility and we have established policies and practices to enable development for a wide array of AI applications. When downloaded or used in accordance with our terms of service, developers should work with their supporting model team to ensure this model meets requirements for the relevant industry and use case and addresses unforeseen product misuse.
For more detailed information on ethical considerations for this model, please see the Model Card++ Explainability, Bias, Safety & Security, and Privacy Subcards. Please report security vulnerabilities or NVIDIA AI Concerns here.
Get started with TensorRT today, and use the right inference tools to develop AI for any application on any platform.