本周的 Model Monday 版本包含 NVIDIA 优化的代码 Lama、Kosmos-2 和 SeamlessM4T,您可以直接在浏览器中体验。
通过NVIDIA AI 基础模型和端点,您可以访问由 NVIDIA 构建的一系列精选社区,生成式 AI用于在企业应用程序中体验、自定义和部署的模型。
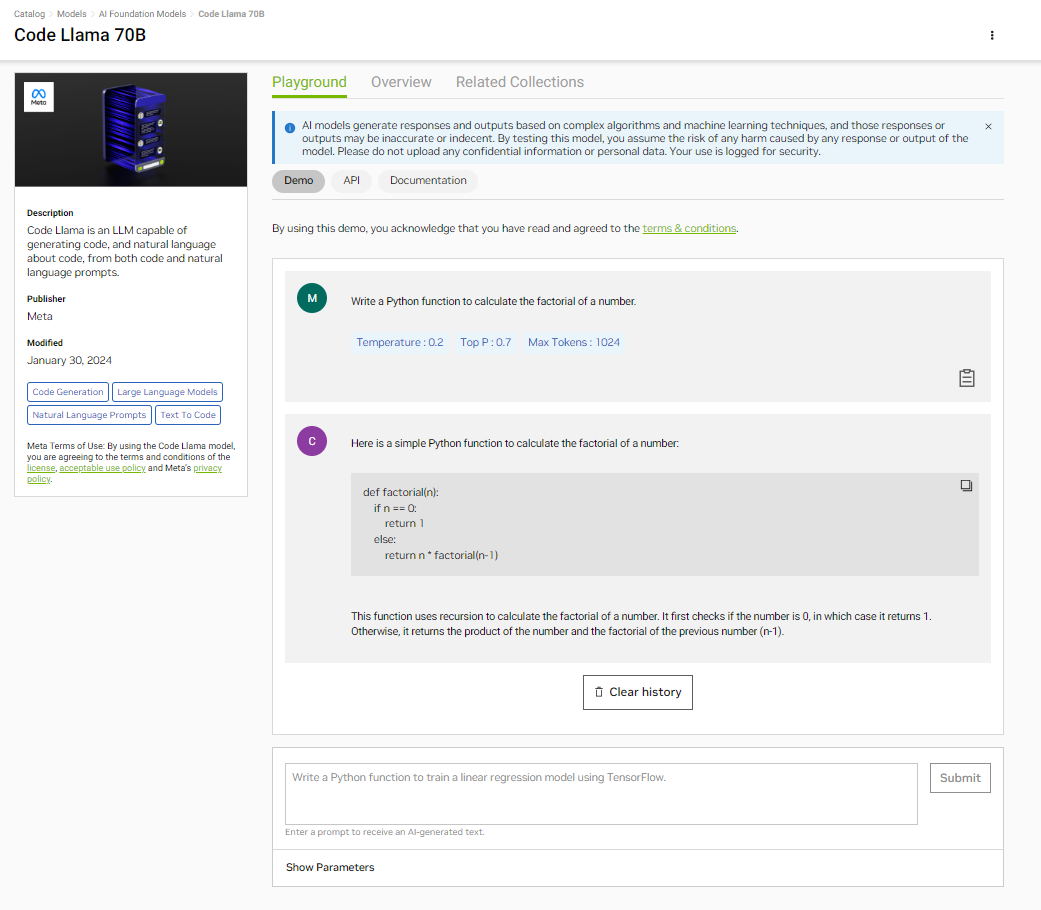
Code Lama 70B
Meta 的 Code Llama 70B 是最新的先进代码 LLM,专用于代码生成。它基于 Llama 2 模型构建,提供更高的性能和适应性。该模型可以从自然语言生成代码,在编程语言之间翻译代码,编写单元测试,并协助调试。
Code Lama 70B 具有 10 万个令牌的大上下文长度,因此能够处理和生成时间更长、更复杂的代码,这对于更全面的代码生成和提高处理复杂编码任务的性能非常重要。这种开源模型可用于代码翻译、汇总、文档、分析和调试等各种应用。
我们的 Code Lama 70B 模型 通过 NVIDIA TensorRT-LLM 提供,您可以通过 NGC 目录 访问。
Kosmos-2
Microsoft Research 的最新多模态大型语言模型 (MLLM) Kosmos-2 使用语言模型实现了视觉感知的显著进步。它通过使用边界框将语言元素(例如输入或输出中的单词或短语)链接到图像中的特定部分,从而实现这一目标。Kosmos-2 最终支持视觉基础、地面问答、多模态参考和图像字幕等任务。
Kosmos-2 基于 Kosmos-1,支持感知多模态输入和上下文中学习。Kosmos-2 使用基于图像文本对的 Web – Scale 数据集(称为 GrIT)进行训练,其中包括文本跨度和边界框,将图像中的特定区域链接到相关文本。图 2 展示了其功能。
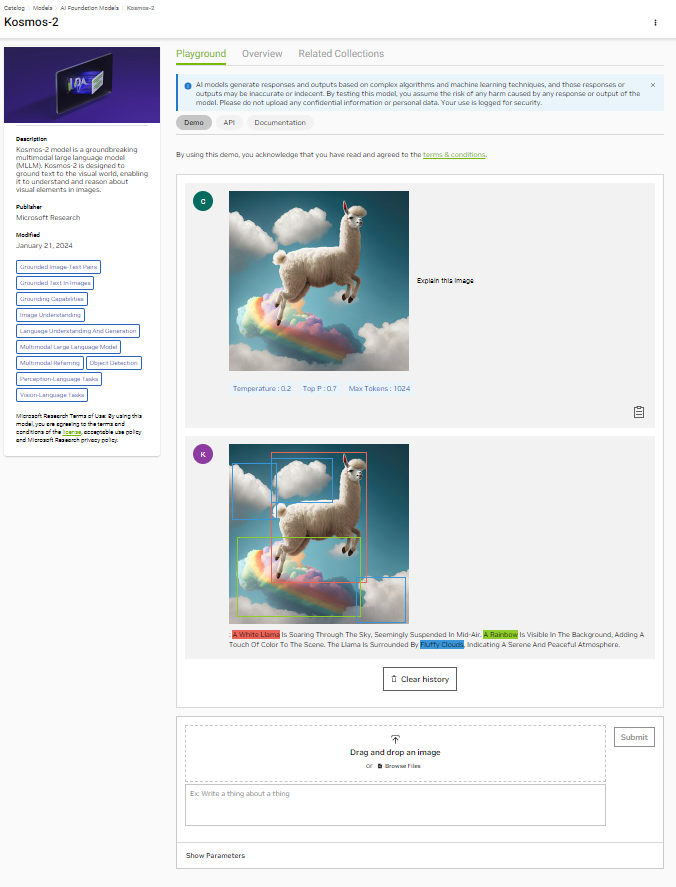
与旨在实现类似目标的前几代 MLLM 相比,KOSMOS-2 在热门学术基准数据集上的零样本短语基础和参考表达理解功能方面表现出色。如果您是一名 AI 开发者,希望利用大型语言模型 (LLM) 突破多模态感知的界限,那么 Kosmos-2 就是您的不二之选。
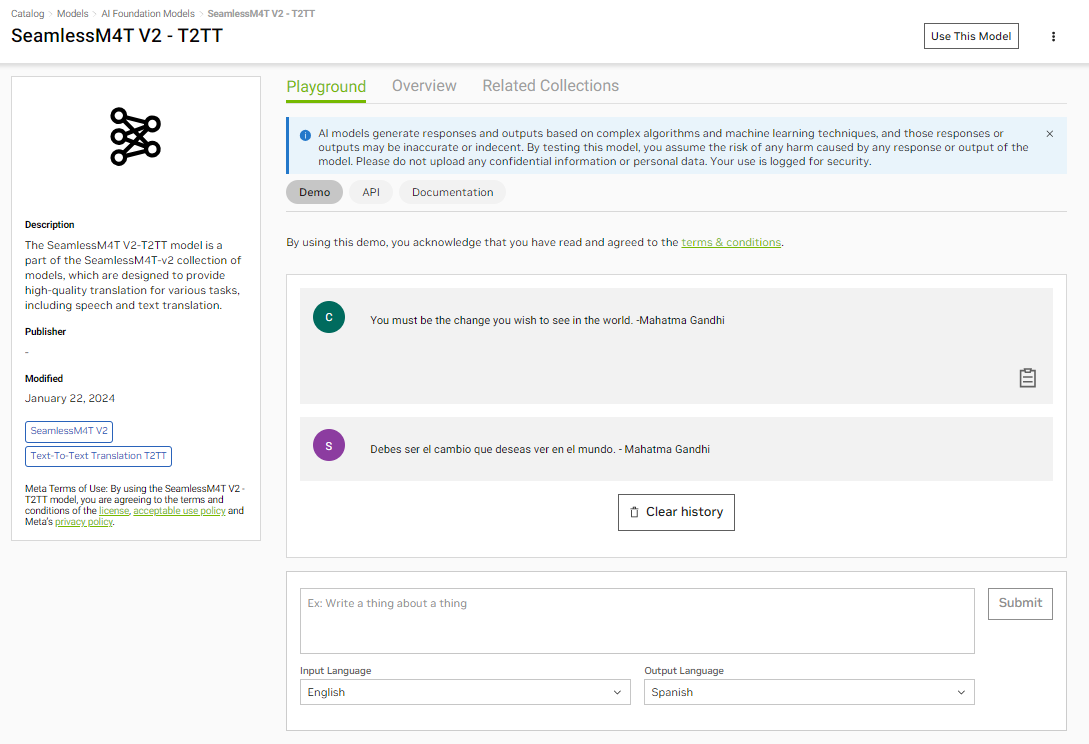
SeamlessM4T
元数据开发的SeamlessM4T是一种多模态基础模型,能够翻译语音和文本,从而简化了企业克服沟通障碍的流程。这促进了知识交流,并有助于在当今全球经济中的国际商业努力。
该模型系列支持近 100 种语言的自动语音识别 (ASR)、语音转文本翻译和文本转文本翻译。这些模型还支持语言切换,支持多语种演讲者无缝沟通,因为他们在对话中自然会更改语言。
NVIDIA 优化了 SeamlessM4T 文本转文本模型。图 2 显示了将演讲者的多语种语音翻译成西班牙语的模型。
该模型的企业用例众多,包括促进与国际客户和合作伙伴的无缝交互。在客户服务领域,客户查询和支持回复的实时翻译可以确保跨语言障碍的有效沟通,以及全球团队在项目中的协作。
Kosmos-2 用户界面
您可以通过访问 NVIDIA NGC 目录上的简单用户界面,直接在浏览器中体验 Kosmos-2。在 NGC 目录中找到“宇宙 2 (Kosmos-2)”游乐场,然后输入您的提示,查看在完全加速堆栈上运行的模型生成的结果。视频 1 展示了 NVIDIA AI Foundation 模型接口的使用,该接口利用在完全加速堆栈上运行的 Kosmos-2 来回答图像中的用户提示。
Kosmos-2 API
您还可以使用 API 测试模型。登录 NGC 目录,然后访问 NVIDIA Cloud Credits,通过将应用程序连接到 API 端点来大规模体验模型。
以下是一个使用 Python 调用 API 并可视化结果的示例。请确保您的环境中安装了虚拟环境,并且已经设置了 Jupyter Notebook。如果需要,您可以使用 pip 安装requests、PIL 和 IPython 模块。
!pip install requests ipython pillow |
第 1 步:获取 NGC 目录 API 密钥
在“NGC catalog API”(NGC 目录 API)选项卡中,选择“Generate Key”(生成密钥)。系统将提示您注册或登录。
接下来,在代码中设置 API 密钥:
# Will be used to issue requests to the endpointAPI_KEY = “nvapi-xxxx“ |
第 2 步:以 Base64 格式对图像进行编码
要在请求中提供图像输入,您必须以 Base64 格式对其进行编码。本示例使用来自 COYO-700M 图像-文本对数据集的图像。
import osimport base64# Fetch an example image from !wget -cO - https://www.boredart.com//wp-content/uploads/2014/06/Beautiful-Pictures-From-the-Shores-of-the-Mythical-Land-421.jpg > scenery.png# Encode the image in base64with open(os.path.join(os.getcwd(), "scenery.png"), "rb") as image_file: encoded_string = base64.b64encode(image_file.read())# Optionally, Visualize the imagefrom IPython import displaydisplay.Image(base64.b64decode(encoded_string)) |

第 3 步:发送推理请求
Kosmos-2 模型可以执行视觉着陆、地面问答、多模态引用和地面图像字幕等任务。要执行的任务由包含特殊令牌决定。下面是特殊令牌<grounding>告知模型将文本中的某些短语链接到图像中的部分。这些短语包含在<phrase>令牌,如输出所示。
import requests invoke_url = "https://api.nvcf.nvidia.com/v2/nvcf/pexec/functions/0bcd1a8c-451f-4b12-b7f0-64b4781190d1" headers = { "Authorization": "Bearer {}".format(API_KEY), "Accept": "application/json",} payload = { "messages": [ { "content": "This scenery<img src="image/png;base64,{}\"" data-mce-src="image/png;base64,{}\"">".format(encoded_string.decode('UTF-8')), "role": "user" } ], "bounding_boxes": True, "temperature": 0.2, "top_p": 0.7, "max_tokens": 1024} # re-use connectionssession = requests.Session() response = session.post(invoke_url, headers=headers, json=payload) while response.status_code == 202: request_id = response.headers.get("NVCF-REQID") fetch_url = fetch_url_format + request_id response = session.get(fetch_url, headers=headers) response.raise_for_status()response_body = response.json() response_body |
例如,在 Kosmos-2 中,表达式以 Markdown 格式表示为链接:(边界框)。边界框表示为坐标序列。此 API 以如下所示的格式返回响应。它包括输出文本、与完成中的短语对应的边界框坐标,以及一些其他元数据。
{'id': 'cfbda798-7567-4409-ba55-6ba9a10294fb','choices': [{'index': 0, 'message': {'role': 'assistant', 'content': 'is a fantasy landscape with a tree and a temple by the lake', 'entities': [{'phrase': 'a tree', 'bboxes': [[0.359375, 0.015625, 0.765625, 0.796875]]}, {'phrase': 'a temple', 'bboxes': [[0.078125, 0.421875, 0.234375, 0.890625]]}, {'phrase': 'the lake', 'bboxes': [[0.203125, 0.765625, 0.828125, 0.953125]]}]}, 'finish_reason': 'stop'}],'usage': {'completion_tokens': 32, 'prompt_tokens': 70, 'total_tokens': 102}} |
根据图像和提示,Kosmos-2 API 生成的标题为“This scene”(此风景),“is a fantasy scape with a tree and a Temple by the lake”(是一个湖边树木和寺庙的奇幻风景)。它还生成了边界框坐标。
第 4 步:可视化输出
如果您将图像视为在 X-Y 平面上布局的 2D 网格,则边界框坐标定义为[Top X,Top Y]和[Bottom X,Bottom Y]。这些坐标分别表示为相对于图像总宽和总高的百分比。为了实现可视化,请在图像上渲染它们:
from PIL import Image, ImageDraw, ImageFontfrom IPython.display import display # Extract the entities from the message body.# This includes a list of phrases and corresponding bounding boxesdata = response_body['choices'][0]['message']['entities'] # Load your imageimage = Image.open(os.path.join(os.getcwd(), "scenery.png"))draw = ImageDraw.Draw(image)width, height = image.size# Set font type and size for phrasesfont = ImageFont.load_default().font_variant(size=10) def get_textbox_dim(text_string, font): ''' Calculate the width and height of a text string with a given font. ''' _, descent = font.getmetrics() text_width = font.getmask(text_string).getbbox()[2] text_height = font.getmask(text_string).getbbox()[3] + descent return (text_width, text_height) # Iterate through all entities, and draw each phrase & boxfor item in data: phrase = item['phrase'] for bbox in item['bboxes']: # Convert percentages to pixel coordinates x1, y1, x2, y2 = bbox x1, x2 = x1 * width, x2 * width y1, y2 = y1 * height, y2 * height # Draw the bounding box for entities draw.rectangle([(x1, y1), (x2, y2)], outline="red", width=2) # Determine size of the text for background text_size = get_textbox_dim(phrase, font) # Draw text background draw.rectangle([x1, y1, x1 + text_size[0], y1 + text_size[1]], fill="black") # Draw the phrase draw.text((x1, y1), phrase, fill="white", font=font) # Display the image in Jupyter Notebookdisplay(image) |
图 6 展示了 Kosmos-2 输出的可视化效果,给定的图像和提示“This scene”。边界框突出显示完成时的实体:“is a fantasy scene with树和寺庙作者湖面“。此示例展示了 Kosmos-2 在视觉方面描述图像和特定于链接的短语的出色能力。

同样,通过在提示中使用 <phrase>和 </phrase>标记来包围特定短语,您可以指示 Kosmos-2 专注于这些短语,并在理解或问答任务中关联这些短语。视觉问答的示例提示可能是 “,<grounding>Question:What color the <phrase>leafs on the tree </phrase>?Answer:” (<grounding>问题:<phrase>在树 </phrase>上留下什么颜色?答案:),模型对其响应为 “red” (红色)。
开始使用
让模型在任何 GPU 或 CPU 上工作,NVIDIA Triton 推理服务器是一款开源软件,可在每个工作负载中标准化 AI 模型部署和执行。Triton 是 NVIDIA AI 平台的一部分,NVIDIA AI Enterprise是一个端到端 AI 运行时软件平台,旨在加速数据科学流程并简化生产级生成式 AI 应用的开发和部署。
NVIDIA AI Enterprise 提供安全性、支持、稳定性和可管理性,以提高 AI 团队的生产力,降低 AI 基础架构的总成本,并确保从 POC 到生产的平稳过渡。当 AI 模型准备好部署以用于业务运营时,安全性、可靠性和企业级支持至关重要。
通过用户界面或 API 试用 Kosmos-2 和 SeamlessM4T 模型。如果这些模型适合您的应用,请使用 NVIDIA TensorRT-LLM 进行优化。
如果您正在构建企业应用程序,请注册 NVIDIA AI Enterprise 试用版,以获得将应用程序投入生产所需的支持。