NVIDIA CUDA Toolkit 12.2 の最新リリースでは、さまざまな重要な新機能、プログラミング モデルの変更、そして CUDA アプリケーションを加速するハードウェア機能のサポート強化が取り入れられています。
現在、NVIDIA から一般提供されている CUDA Toolkit 12.2 には、メジャーなものからマイナーなものまで、多くの新機能が含まれています。
この記事では、以下の主要機能の概要をご紹介します:
- NVIDIA Hopper (H100) GPU サポート。
- Hopper GPU 向け NVIDIA コンフィデンシャル コンピューティング (CC) への早期アクセス。
- ヘテロジニアス メモリ管理 (HMM) のサポート。
- 遅延ロードのデフォルト設定。
- CUDA Multi-Process Service (MPS) 利用時におけるアプリケーションの優先順位付け。
- NVIDIA Nsight Compute と NVIDIA Nsight Systems Developer Tools のアップデート。
NVIDIA は、アクセラレーテッド コンピューティングのパイオニアとして、世界で最も困難なコンピューティング課題の解決を支援するソリューションを創造しています。アクセラレーテッド コンピューティングには、チップ アーキテクチャ、システム、アクセラレーション ライブラリからセキュリティやネットワーク接続に至るまで、フルスタックの最適化が必要です。すべては CUDA Toolkit から始まります。
以下の CUDA Toolkit 12.2 YouTube Premiere ウェビナーをご覧ください。
Hopper GPU サポート
H100 GPU アーキテクチャの新機能は、新しい PTX 命令や、より高いレベルの C および C++ API による公開を含む、すべての GPU のプログラミング モデル強化と共にサポートされるようになりました。その一例が Hopper コンフィデンシャル コンピューティング (詳細は次のセクションを参照) で、Hopper GPU アーキテクチャでのみ利用可能な早期アクセス展開を提供します。
Hopper のコンフィデンシャル コンピューティング
Hopper コンフィデンシャル コンピューティングの早期アクセス ソフトウェア リリースは、パススルー モードで単一の H100 GPU を対象とする完全なソフトウェア スタックを特徴としており、暗号化と認証のための単一のセッション キー、および NVIDIA 開発者ツールの基本的な利用が可能です。ユーザー コードとデータは、AES-GCM 規格で暗号化され、認証されます。
特定の H100 SKU、ドライバー、ツールキットのダウンロードは必要ありません。H100 GPU によるコンフィデンシャル コンピューティングには、AMD SEV-SNP や Intel TDX など、仮想マシン (VM) ベースの TEE テクノロジをサポートする CPU が必要です。
コンフィデンシャル コンピューティング (CC) 互換サーバーを出荷している OEM パートナーを紹介した、コンフィデンシャル コンピューティングによる機密データと AI モデルの保護の記事をお読みください。
下図は、CC が有効の場合と無効の場合の VM 使用時のデータ フローを比較したものです。
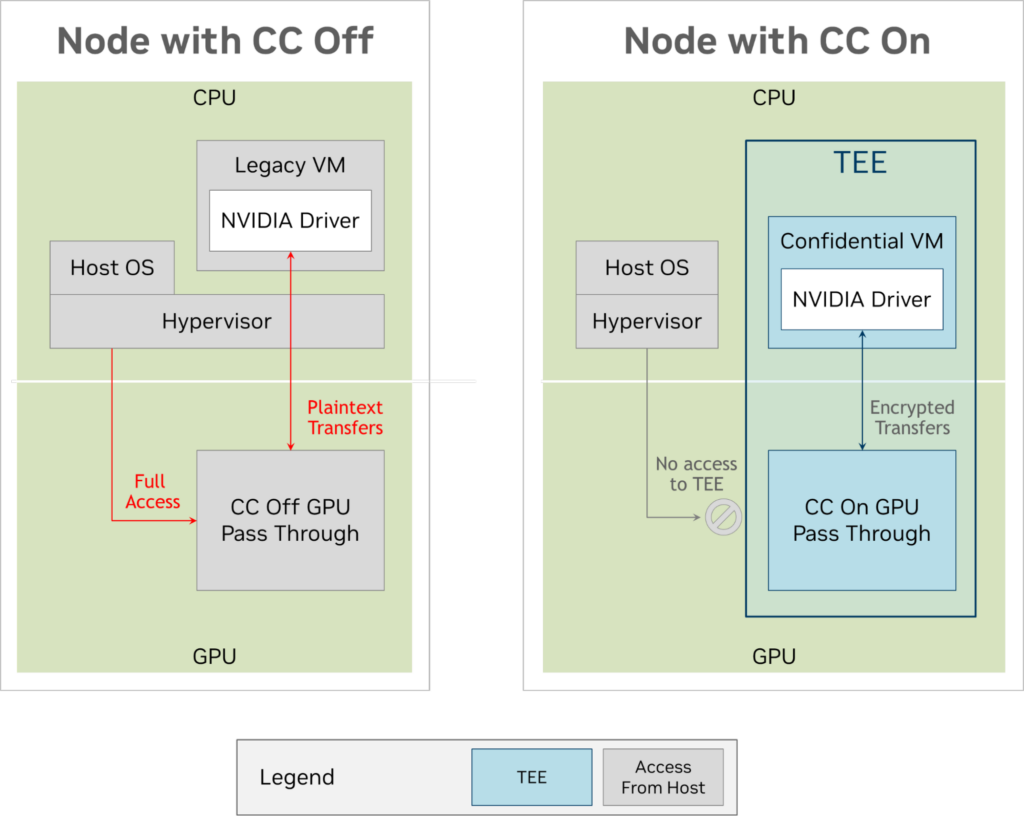
図 1 では、左側に従来の VM がセットアップされています。このモードでは、ハイパーバイザーは H100 GPU を割り当てます (CC モードは有効になっていません)。ハイパーバイザーは悪意のある VM から隔離され保護されていますが、その逆はそうではありません。ハイパーバイザーは VM 空間全体にアクセスできるだけでなく、GPU にも直接アクセスできます。
図 1 の右側は、同じ環境をコンフィデンシャル コンピューティング可能なマシン上で示しています。CPU アーキテクチャは、ハイパーバイザーから機密仮想マシン (CVM) を分離し、CVM がメモリ ページにアクセスできないようにしています。H100 も、CVM との間のパスを除いて、外部からのアクセスがすべて無効になるように設定されています。CVM と H100 は、PCIe バスをまたいで暗号化され署名された転送を行うため、バス アナライザーを持つ攻撃者がデータを利用したり、黙って破損したりすることを防ぐことができます。
早期アクセス リリースを使用している間は、優れた実践を採用し、合成データと非専有な AI モデルのみをテストしてください。セキュリティ レビュー、パフォーマンス強化、監査は最終決定されたものではありません。
Hopper コンフィデンシャル コンピューティングには、現時点では暗号化キーのローテーションは含まれていません。詳細は、コンフィデンシャル コンピューティングとは? をご覧ください。
ヘテロジニアス メモリ管理
このリリースでは、ヘテロジニアス メモリ管理 (HMM) も取り入れられています。この技術は、ユニファイド仮想メモリのサポートを拡大し、CUDA によって割り当てられたメモリや CUDA によって管理されるメモリを必要とすることなく、ホスト メモリとアクセラレータ デバイス間でデータをシームレスに共有します。これにより、CUDA へのアプリケーション移植や、外部フレームワークや API との連携が大幅に容易になります。
現在、HMM は Linux でのみサポートされており、NVIDIA GPU Open Kernel Modules ドライバーの使用とともに、最新のカーネル (6.1.24 以上または 6.2.11 以上) が必要です。
最初のリリースにはいくつかの制限があり、以下の項目はまだサポートされていません:
- file-backed メモリ上での GPU アトミック演算。
- Arm CPU。
- HMM 上 のHugeTLBfs ページ。
- 親プロセスと子プロセスの間で GPU アクセス可能メモリを共有しようとしたときの
fork()システム コール。
また、HMM はまだ完全に最適化されていないため、cudaMalloc()、cudaMallocManaged()、または他の既存の CUDA メモリ管理 API を使用するプログラムよりも実行速度が遅くなる可能性があります。
遅延ロード
NVIDIA が 当初 CUDA 11.7 でオプトインとして取り入れた機能である遅延ロードは、R535 ドライバー以降の Linux でデフォルトで有効になりました。遅延ロードは、必要に応じて CUDA カーネルとライブラリ関数のみをロードすることにより、ホストとデバイスの両方のメモリ フットプリントを大幅に削減することができます。複雑なライブラリには、数千もの異なるカーネルやバリアントが含まれているのが普通ですから、かなりの節約が可能になります。
遅延ロードはユーザーの制御下にあり、デフォルト値のみが変更されます。Linux では、アプリケーションを起動する前に環境変数を設定することで、この機能を無効にすることができます:
CUDA_MODULE_LOADING=EAGER Windows では現在無効にすることはできませんが、起動前に環境変数を設定することで、Windows でも有効にすることができます:
CUDA_MODULE_LOADING=LAZYCUDA MPS 利用時におけるアプリケーションの優先順位付け
CUDA MPS でアプリケーションを実行する場合、各アプリケーションはシステムに存在する唯一のアプリケーションとしてコーディングされることが多々あります。そのため、個々のストリー ムの優先順位は、システムレベルの競合がないものと想定されます。しかし実際には、ユーザーは特定のプロセスを全体的に高い優先度または低い優先度にしたい場合がよくあります。
この要件に対応するため、CUDA MPS の実行時にクライアントごとの優先度マッピングが利用可能になりました。これにより、MPS の下で実行される複数のプロセスが、アプリケーションのコードを変更することなく、複数のプロセス間で優先順位の調整を行えるようになります。
CUDA_MPS_CLIENT_PRIORITY という新しい環境変数は、2 つの値を受け入れます: NORMAL priority, 0 と BELOW_NORMAL priority, 1
例えば、2 つのクライアントがある場合、以下のような設定が考えられます:
| クライアント 1 の環境 | クライアント 2 の環境 |
export CUDA_MPS_CLIENT_PRIORITY=0 // NORMAL | export CUDA_MPS_CLIENT_PRIORITY=1 // BELOW NORMAL |
注目すべき点は、これは GPU スケジューラーに優先順位にもとづいたプリエンプションやハード リアルタイム処理を取り入れるものではないということです。どのカーネルがいつキューに加えるべきかという追加情報をスケジューラーに提供します。
Nsight Developer Tools
Nsight Developer Tools は CUDA Toolkit に含まれており、CUDA アプリケーションのデバッグとパフォーマンス プロファイリングを支援します。GPU 開発用のツールはすでに H100 アーキテクチャと互換性があります。NVIDIA Grace CPU アーキテクチャのサポートが Nsight Systems で利用可能になり、システム全体のパフォーマンス プロファイリングが可能になりました。
Nsight Systems は、CPU と GPU の相互作用のようなプラットフォーム ハードウェアのメトリクス、および CUDA アプリ、API、ライブラリを統一されたタイムライン上でトレースし、分析します。CUDA Toolkit 12.2 で提供されるバージョン 2023.2 では、Python バックトレース サンプリングが取り入れられています。
GPU アクセラレーションによる Python は、AI ワークロードに変革をもたらします。Python コードの定期的なサンプリングにより、Nsight Systems のタイムライン上で、GPU の最大使用率に向けたリファクタリングにどのようなアルゴリズムが関与しているかをより深く理解することができます。Python サンプリングは、データ センター規模でのコンピューティングの最適化を支援するために、マルチノード解析とネットワーク メトリック収集に加わります。詳細は Nsignt Systems によるデータ センターと HPC パフォーマンスの高速化をご覧ください。
Nsight Compute は、GPU 上で動作する CUDA カーネルの詳細なパフォーマンス プロファイリングと解析を提供します。バージョン 2023.2 では、サマリー ページに、検出されたパフォーマンス問題についての分類されたリストが新たに追加され、問題を修正した場合の推測される高速化も含まれています。このリストは、パフォーマンス チューニングの焦点を導き、ユーザーが不要な問題に時間を費やすことを避けるのに役立ちます。
追加されたもうひとつの重要な機能は、ソース ページのソース行レベルでのパフォーマンス ルール マーカーです。以前は、組み込みのパフォーマンス ルールで検出された問題は、詳細ページにのみ表示されていました。現在は、ソース ページに警告アイコンが表示されます。パフォーマンス メトリクスは場所を特定します。
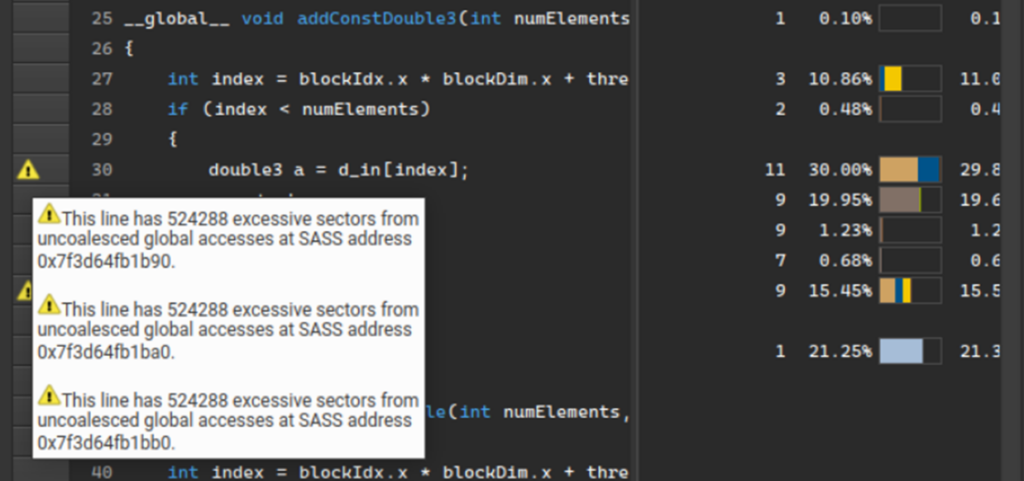
これらの新機能は、高レベルのサマリー ビューと低レベルのソース ビューの両方でガイド付きの解析を拡張し、Nsight Compute のパフォーマンス プロファイリングおよび解析機能をさらに向上します。
CUDA Toolkit 12.2 は、最新のデバッグ ツールも備えており、以下が含まれます:
- 機能的正しさをチェックする NVIDIA Compute Sanitizer。
- コマンドラインで CPU および GPU をデバッグする CUDA-GDB。
- IDE に統合された CUDA をデバッグする NVIDIA Nsight Visual Studio Code Edition。
詳細は、Compute Sanitizer を使用して CUDA コードをデバッグする方法をご覧ください。
まとめ
CUDA Toolkit の最新リリースでは、アクセラレーテッド コンピューティング アプリケーションの基盤を構築する CUDA アプリケーションの強化に不可欠な新機能が取り入れられています。チップ アーキテクチャ、NVIDIA DGX Cloud および NVIDIA DGX SuperPOD プラットフォーム、AI Enterprise ソフトウェア、ライブラリから、セキュリティやネットワーク接続の高速化まで、CUDA Toolkit は比類のないフルスタックな最適化を提供します。
関連情報:
- NVIDIA CUDA Toolkit
- CUDA Toolkit 12.2 Release Notes
- NVIDIA Hopper アーキテクチャ
- CUDA Compatibility
- NVIDIA Releases Open-Source GPU Kernel Modules
- GPU-Accelerated Libraries
- NVIDIA Nsight Compute および NVIDIA Nsight Systems
翻訳に関する免責事項
この記事は、「NVIDIA CUDA Toolkit 12.2 Unleashes Powerful Features for Boosting Applications」の抄訳で、お客様の利便性のために機械翻訳によって翻訳されたものです。NVIDIA では、翻訳の正確さを期すために注意を払っておりますが、翻訳の正確性については保証いたしません。翻訳された記事の内容の正確性に関して疑問が生じた場合は、原典である英語の記事を参照してください。