
生成 AI を導入する動きの高まりには目覚ましいものがあります。2022 年に OpenAI がリリースした ChatGPT をきっかけに、たった数か月の間に 1 億人以上のユーザーがこの新しいテクノロジを使い始め、ほぼすべての業界にわたり開発活動が活発になりました。
2023 年までに、開発者たちは Meta、Mistral、Stability などが提供する API やオープンソースのコミュニティ モデルを使った概念実証を始めました。
2024 年に入り、組織は、AI モデルを既存の企業インフラに接続し、システムのレイテンシとスループットを最適化し、ロギング、モニタリング、セキュリティなどを含む、本格的な本番環境へのデプロイに重点を移行しつつあります。このような本番環境へのデプロイの道のりは、複雑で時間がかかります。専門的なスキル、プラットフォーム、プロセスを必要とし、大規模な環境では特にそれが顕著になります。
NVIDIA AI Enterprise に含まれる NVIDIA NIM は、AI を活用するエンタープライズ アプリケーションの開発と、AI モデルを本番環境にデプロイするための合理化された道のりを提供します。
NIM は、最適化されたクラウドネイティブなマイクロサービスのセットです。クラウド、データ センター、GPU 対応ワークステーションなど、場所を問わず生成 AI モデルのデプロイをシンプルに行えるように設計され、市場投入までの時間を短縮します。業界標準の API を使用し、AI モデルの開発における複雑さを抽象化し、本番環境向けにパッケージ化することで、開発者の裾野を広げます。
最適化された AI 推論のための NVIDIA NIM
NVIDIA NIM は、複雑な AI 開発の世界と、エンタープライズ環境の運用ニーズとのギャップを埋めるように設計されており、10〜100 倍以上のエンタープライズ アプリケーション開発者が、企業の AI 変革に貢献できるようにします。
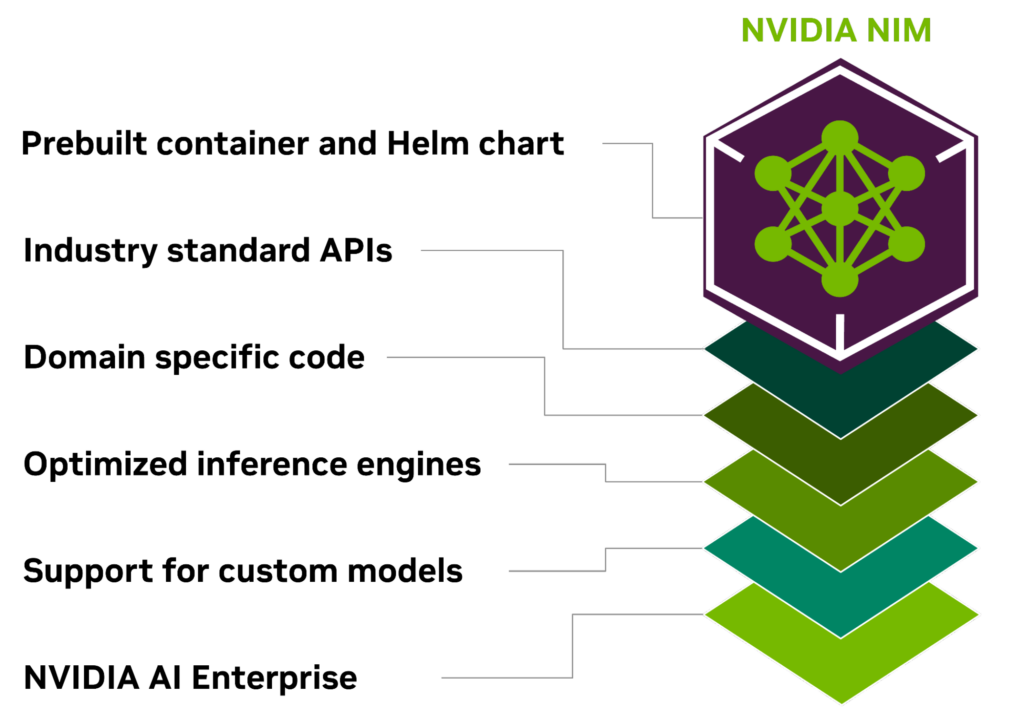
NIM の主要な利点を以下に示します。
どこでもデプロイ可能
NIM は移植性と制御性を重視して設計されており、ローカルのワークステーションからクラウド、オンプレミスのデータ センターまで、さまざまなインフラへのモデルのデプロイに対応しています。デプロイ先には NVIDIA DGX、NVIDIA DGX Cloud、NVIDIA 認定システム、NVIDIA RTX ワークステーションや、PC が含まれます。
最適化されたモデルとともにパッケージ化されるビルド済みコンテナーと Helm チャートは、さまざまな NVIDIA ハードウェア プラットフォーム、クラウド サービス プロバイダー、Kubernetes ディストリビューションでの厳密な検証とベンチマークがされています。そのため、NVIDIA を利用したすべての環境でのサポートが可能になり、組織はどこにでも生成 AI アプリケーションをデプロイすることができ、アプリケーションと処理するデータも完全に制御することができます。
業界標準の API を使用した開発
開発者は各ドメインの業界標準に準拠した API を使って AI モデルにアクセスできるため、AI アプリケーションの開発がシンプルになります。これらの API はエコシステム内の標準的なデプロイ プロセスとの互換性が確保されているため、開発者は AI アプリケーションの更新を迅速に行うことができ、ほとんどの場合、更新に必要なコードはわずか 3 行程度です。このシームレスな統合と使いやすさにより、エンタープライズ環境での AI ソリューションの導入と拡張を迅速に行うことができます。
ドメイン固有のモデルの活用
NIM はいくつかの主要な機能を通じて、ドメイン固有のソリューションやパフォーマンス最適化のニーズにも対応します。NIM のパッケージには、ドメイン固有の NVIDIA CUDA ライブラリや、言語、音声、動画処理、ヘルスケアなどの様々なドメインに合わせたカスタムのコードが含まれます。これらを利用することで、アプリケーションを特定のユース ケースに対応させ、正確に機能させることができます。
最適化された推論エンジンでの実行
NIM はモデルとハードウェア構成ごとに最適化された推論エンジンを活用して、高速なインフラ上で可能な限りの低レイテンシと高いスループットを提供します。これにより、推論ワークロードの実行にかかるコストを抑え、エンドユーザーの体験を高めることができます。最適化されたコミュニティ モデルがサポートされているほか、開発者はデータ センターの境界から決して出せない独自のデータ ソースを使ってモデルのアライメントやファインチューニングを行い、さらに高い精度とパフォーマンスを実現することができます。
エンタープライズ グレードの AI のサポート
NVIDIA AI Enterprise に含まれる NIM は、エンタープライズ グレードのベース コンテナーで構築されており、機能ブランチ、厳格な検証、サービスレベル契約によるエンタープライズ サポート、CVE の定期的なセキュリティ アップデートを通じて、エンタープライズ AI ソフトウェアのための強固な基盤を提供します。包括的なサポート体制と最適化機能は、効率性と拡張性を備えたカスタマイズされた AI アプリケーションを本番環境にデプロイする上で、極めて重要なツールとしての NIM の役割を特徴づけています。
すぐにデプロイ可能な高速化された AI モデル
コミュニティ モデル、NVIDIA AI Foundation モデル、NVIDIA のパートナーが提供するカスタム AI モデルなど、多くの AI モデルをサポートする NIM は、複数のドメインにわたる AI のユース ケースをサポートします。これには大規模言語モデル (LLM) や視覚言語モデル (VLM) のほか、音声、画像、動画、3D、創薬、医用画像処理などに対応する数々のモデルが含まれます。
開発者は、NVIDIA API カタログから NVIDIA のマネージド クラウドの API を使用して、最新の生成 AI モデルを試すことができます。また、NIM をダウンロードしてモデルをセルフホストしたり、Kubernetes を使って主要なクラウド プロバイダーや本番向けのオンプレミスの環境に迅速にデプロイすることもでき、開発時間、複雑さやコストを削減することができます。
NIM のマイクロサービスは、アルゴリズム、システム、ランタイムの最適化をパッケージ化し、業界標準の API を提供することで、AI モデルのデプロイ プロセスをシンプルにします。これにより、大規模なカスタマイズや専門知識がなくても、開発者は NIM を既存のアプリケーションやインフラストラクチャに統合することができます。
NIM を利用することで、企業はAI モデルの開発の複雑さやコンテナー化について心配することなく、AI インフラを最適化し、効率性と費用対効果を最大化することができます。NIMは、AI インフラの高速化に加え、ハードウェアと運用のコストを削減しながら、パフォーマンスとスケーラビリティの強化も支援します。
エンタープライズ アプリケーション向けにモデルのカスタマイズを検討している企業に向けて、NVIDIA では多様なドメインでのモデルのカスタマイズを行うためのマイクロサービスを提供しています。NVIDIA NeMo は、独自のデータを使った LLM、音声 AI、マルチモーダル モデルのファインチューニング機能を提供します。NVIDIA BioNeMo は、生成生物、化学や分子予測のためのモデルのコレクションを拡充し、創薬を加速します。NVIDIA Picasso は、Edify モデルでクリエイティブ ワークフローを高速化します。これらのモデルは、ビジュアル コンテンツのプロバイダーからライセンス供与されたライブラリを使ってトレーニングされており、ビジュアル コンテンツ制作のためにカスタマイズされた生成 AI モデルのデプロイを可能にします。
NVIDIA NIM を使ってみる
NVIDIA NIM を使い始めるのは簡単で、分かり易いです。開発者は NVIDIA API カタログで、独自の AI アプリケーションの構築とデプロイに使用可能な幅広い AI モデルにアクセスすることができます。
プロトタイピングを始めるのには、カタログで直接 GUI を使用する方法と、API と直接やりとりする方法が利用でき、費用はかかりません。お持ちのインフラ上にマイクロサービスをデプロイするには、NVIDIA AI Enterprise の 90 日間の評価ライセンスを申し込み、以下の手順に従ってください。
- デプロイしたいモデルを NVIDIA NGC からダウンロードします。この例では、1 枚の A100 GPU 用にビルドされた Llama-2 7B モデルのバージョンをダウンロードします。
ngc registry model download-version "ohlfw0olaadg/ea-participants/llama-2-7b:LLAMA-2-7B-4K-FP16-1-A100.24.01"お持ちの GPU が異なる場合は、「ngc registry model list “ohlfw0olaadg/ea-participants/llama-2-7b:*”」で利用可能なモデルのバージョンを一覧表示できます。
2. ダウンロードしたアーティファクトをモデル リポジトリに解凍します。
tar -xzf llama-2-7b_vLLAMA-2-7B-4K-FP16-1-A100.24.01/LLAMA-2-7B-4K-FP16-1-A100.24.01.tar.gz3. 目的のモデルを指定して NIM コンテナーを起動します。
docker run --gpus all --shm-size 1G -v $(pwd)/model-store:/model-store --net=host nvcr.io/ohlfw0olaadg/ea-participants/nemollm-inference-ms:24.01 nemollm_inference_ms --model llama-2-7b --num_gpus=14. NIM のデプロイに成功すると、標準の REST API を使ったリクエストが可能になります。
import requests
endpoint = 'http://localhost:9999/v1/completions'
headers = {
'accept': 'application/json',
'Content-Type': 'application/json'
}
data = {
'model': 'llama-2-7b',
'prompt': "The capital of France is called",
'max_tokens': 100,
'temperature': 0.7,
'n': 1,
'stream': False,
'stop': 'string',
'frequency_penalty': 0.0
}
response = requests.post(endpoint, headers=headers, json=data)
print(response.json())NVIDIA NIM は、本番環境への AI の導入を加速する組織を支援する、強力なツールです。AI の導入を、今すぐに始めましょう。
関連情報
- DLI コース: Deploying a Model for Inference at Production Scale
- GTC セッション: Accelerating Enterprise: Tools and Techniques for Next-Generation AI Deployment
- GTC セッション: LLM Inference Sizing: Benchmarking End-to-End Inference Systems
- NGC コンテナー: Parakeet RIVA ASR NIM
- SDK: Triton Management Service
- SDK: Triton Inference Server