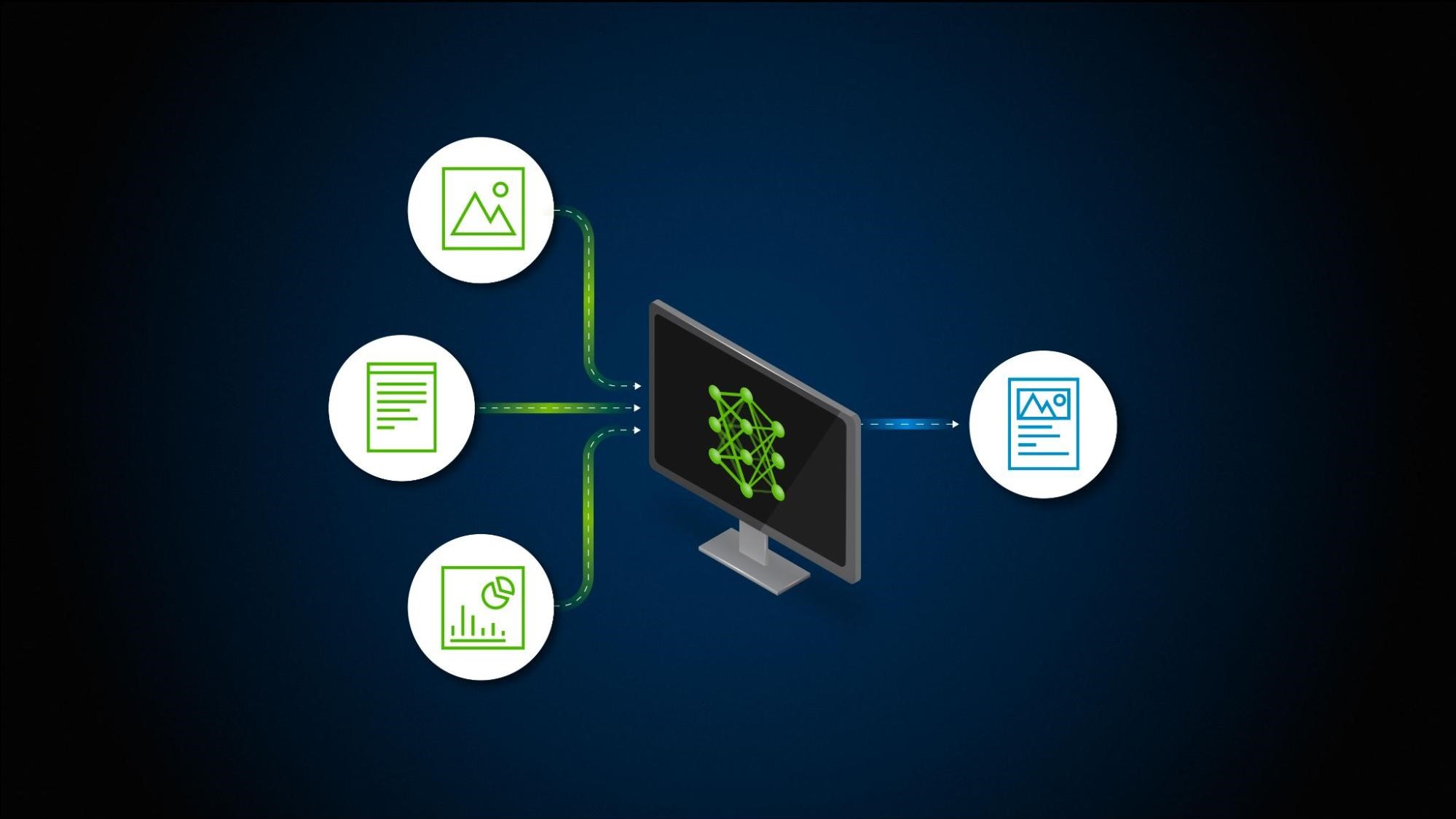
検索拡張生成 (RAG) アプリケーションで、テキストだけでなく、表、グラフ、チャート、図など、さまざまな種類のデータを処理できれば、その有用性が飛躍的に高まります。そのためには、テキストや画像などの形式の情報を一貫して理解し、応答を生成することができるフレームワークが必要です。
この記事では、マルチモダリティ (複数の種類のデータ) を扱う上での課題と、マルチモーダル RAG パイプラインを構築するためのアプローチについて説明します。説明を簡潔にするために、画像とテキストの 2 つのモダリティのみに焦点を当てます。
マルチモダリティはなぜ難しいのでしょうか?
企業が扱う非構造化データは、フォルダーをいっぱいにしている高解像度の画像や、テキストが含まれる表、グラフ、図などが混在した PDF のように、複数のモダリティにまたがって散らばっていることが多くあります。
このように広がりのあるモダリティを扱う際には、考慮するべき重要な点が 2 つあります。まず、モダリティごとに特有の課題があること、そしてモダリティ間でどのように情報を取り扱うかです。
モダリティごとの特有の課題
たとえば、画像について考えてみましょう (図 1)。左の画像の場合、細部というよりは全体的なイメージに焦点が置かれています。注目は、池、海、木、砂など、いくつかの主要なポイントにのみ向けられます。

レポートや資料には、グラフや図表など、情報密度の高い画像が含まれていることがあります。そのような画像には、多数の注目するべきポイントや、画像から導き出せる補足の文脈が含まれます。どのようなパイプラインを構築するにせよ、こうしたニュアンスを捉え、処理し、情報を効果的に埋め込む必要があります。
モダリティ間でどのように情報を扱うか
もう 1 つの重要な側面は、異なるモダリティ間にまたがる情報の表現方法です。たとえば、文書を扱う場合、図表の意味表現が、同じ図表について説明しているテキストの意味表現と一致していることを確認する必要があります。
マルチモーダル検索のアプローチ
重要な課題について理解したところで、これらの課題に取り組むための RAG パイプラインの構築について詳しくご紹介します。
マルチモーダル RAG パイプラインを構築するにあたっては、以下のような、いくつかの主要なアプローチがあります。
- すべてのモダリティを同じベクトル空間に埋め込む
- すべてのモダリティを 1 つの主要なモダリティにまとめる
- モダリティごとに異なるストアを用意する
議論を簡潔にするために、画像とテキストの入力についてのみ説明します。
すべてのモダリティを同じベクトル空間に埋め込む
画像とテキストの場合、CLIP のようなモデルを使用すると、テキストと画像の両方を同じベクトル空間でエンコードすることができます。これにより、多くの場合、テキストのみに対応する RAG のインフラを使用しながら、埋め込みモデルを入れ替えて他のモダリティに対応させることができます。生成パスでは、大規模言語モデル (LLM) を、すべての質問と回答に対応するマルチモーダル LLM (MLLM) に置き換えます。
一般的な検索パイプラインで必要な変更は、埋め込みモデルを置き換えるだけなので、このアプローチではパイプラインを簡素化できます。
この場合のトレードオフは、さまざまな種類の画像やテキストを効果的に埋め込むことができるモデルにアクセスできるかどうかと、画像内のテキストや複雑な表などの入り組んだ情報もすべて取り込めるかどうか、ということです。
すべてのモダリティを 1 つの主要なモダリティにまとめる
もう 1 つの選択肢は、アプリケーションが注目するものに基づいて主要なモダリティを選択し、他のすべてのモダリティを主要なモダリティにまとめることです。
たとえば、アプリケーションが PDF を使ったテキストベースの Q&A を中心にしているとします。この場合、通常はテキストを扱いますが、画像については前処理のステップでテキストによる説明とメタデータを作成しておきます。加えて、後で参照するために画像を保存しておきます。
推論パスでは、主にテキストによる説明と、画像のメタデータに基づいて検索を行い、得られた画像の種類に応じて LLM と MLLM を組み合わせて回答を生成します。
この場合の主な利点は、情報豊富な画像から生成されたメタデータが、客観的な質問に答えるのに非常に役に立つということです。これは、画像の埋め込みに使用するためのモデルのチューニングや、異なるモダリティ間の結果をランク付けするための Reranker の構築の必要性を回避します。主な欠点は、前処理コストがかかることと、画像のニュアンスの一部が失われることです。
モダリティごとに異なるストアを用意する
別のアプローチとして、Rank-Rerank があります。異なるモダリティごとに別々のストアを用意し、それらすべてにクエリを実行して上位 N 個のチャンクを取得し、専用のマルチモーダルの Reranker を使って最も関連性の高いチャンクを得ます。
このアプローチでは、モデリング プロセスがシンプルになり、複数のモダリティを扱うために 1 つのモデルを調整する必要がなくなります。ただし、上位 M*N 個のチャンク (M 種類それぞれのモダリティから N 個ずつ) を並び替える Reranker という複雑さが加わります。
生成のためのマルチモーダル モデル
LLM は、テキストベースの情報を理解し、解釈し、生成するように作られています。LLM は膨大な量のテキスト データを使ってトレーニングされ、テキスト生成、要約、質問応答など、さまざまな自然言語処理タスクを実行できます。
テキスト以外のデータも認識できるのが、MLLM です。MLLM は画像、音声、動画などのモダリティを扱うことができます。多くの場合、実世界のデータはこのような構成です。MLLM は種類の異なるこれらのデータを組み合わせることで、より包括的に情報を解釈し、予測の精度と堅牢性を向上させます。
これらのモデルは、以下のようなさまざまなタスクを実行できます。
- 視覚言語の理解と生成
- マルチモーダル対話
- 画像のキャプションの生成
- 視覚質問応答 (VQA: Visual Question Answering)
これらはすべて、RAG システムで複数のモダリティを扱う際に恩恵が得られるタスクです。MLLM が画像やテキストをどのように処理するのかをより深く理解するには、これらのモデルがどのように構築されているかを見ていく必要があります。
MLLM で人気のあるサブタイプの 1 つが、Pix2Struct です。これは、斬新な事前トレーニング戦略によって視覚入力の意味的理解を可能にする、事前学習済みの image-to-text モデルです。これらのモデルは、その名のとおり、画像から抽出された構造化情報を生成します。たとえば、Pix2Struct モデルでは、グラフから主要な情報を抽出してテキストで表現することができます。これを理解したうえで、RAG パイプラインの構築方法の説明に進みます。
マルチモーダル RAG パイプラインの構築
モダリティの異なるデータを扱う方法を紹介するため、Breaking MLPerf Training Records with NVIDIA H100 GPUs のような複数の技術的な記事のインデックスを作成するアプリケーションに沿って説明します。この記事には、リッチテキストを含むグラフやチャートといった複雑な画像や、表データ、そしてもちろんパラグラフが含まれます。
データの処理と RAG パイプラインの構築を始めるにあたって必要となるモデルや手法は、以下のとおりです。
- MLLM: 画像のキャプション生成と VQA に使用します。
- LLM: 一般的な論理推論と質疑応答に使用します。
- 埋め込みモデル: データをベクトルにエンコードします。
- ベクトル データベース: エンコードしたベクトルを検索用に保存します。
マルチモーダル データの解釈とベクトル データベースの作成
RAG アプリケーションを構築するための最初のステップは、データを前処理し、ベクトル ストアにベクトルとして保存することです。そうすることで、クエリに基づいて関連するベクトルを取得することができます。
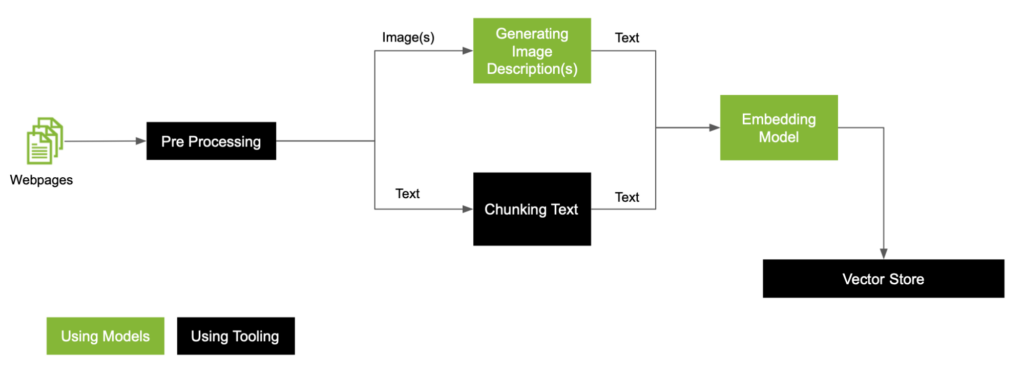
データに画像が含まれる場合に行う必要のある一般的な RAG の前処理ワークフローを示します (図 2)。
記事には、図 3 に示すような棒グラフがいくつか含まれます。このような棒グラフを解釈するために、Google の DePlot を使用します。これは、LLM と組み合わせてグラフやプロットを理解できる、視覚言語モデルです。このモデルは NGC で利用できます。
RAG アプリケーションで DePlot API を使用する方法の詳細については、Query Graphs with Optimized DePlot Model を参照してください。
この例では、グラフとプロットに焦点を当てます。他の文書には、医用画像や回路図などのような処理するためにモデルのカスタマイズが必要な特殊な画像が含まれている場合があります。用途によって異なりますが、このような画像の差異に対処するにはいくつかの方法があります。単一の MLLM をチューニングすることであらゆる種類の画像を扱えるようにするか、さまざまな種類の画像に対応するモデルのアンサンブルを構築します。
説明を簡潔にするために、ここでは以下の 2 つのカテゴリを扱う、単純なアンサンブルのケースについて考えます。
この記事では、ベクトル データベースを作成するために、カスタムのテキスト スプリッター、カスタマイズした MLLM、および LLM を活用して前処理パイプラインを拡張することで、パイプライン内での各モダリティの処理について詳しく説明します (図 4)。
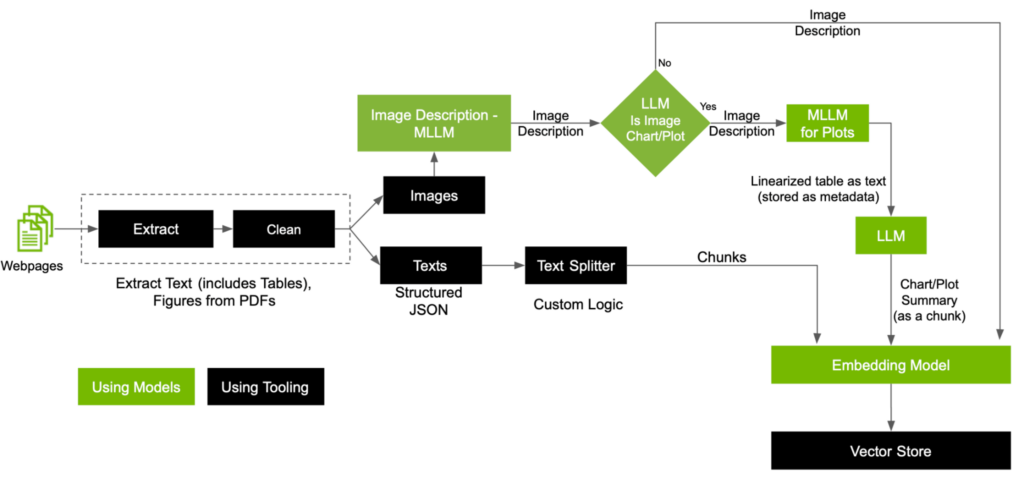
前処理ワークフローの主な手順は以下のとおりです。
- 画像とテキストを分ける
- MLLM を使って画像の種類により画像を分類する
- PDF 内のテキストを埋め込む
画像とテキストを分ける
ここでの目標は、画像をテキストのモダリティにまとめることです。データを抽出してクリーニングすることから始め、画像とテキストを分離します。その後、これら 2 つのモダリティを処理し、最終的にベクトル ストアに格納します。
MLLM を使って画像の種類により画像を分類する
MLLM によって生成された画像の説明を使用すると、画像がグラフであるかどうかなど、画像をカテゴリに分類できます。この分類に基づいて、グラフが含まれる画像では、DePlot を使って線形化された表形式のテキストを生成します。このテキストは通常のテキストと意味的に異なるため、推論中に実行する検索において、適切な情報を取得するのが課題になります。
推奨するのは、線形化されたテキストの要約をチャンクとして使用し、ベクトル ストアに保存することです。そこにはカスタマイズされた MLLM からの出力をメタデータとして含め、推論で利用できるようにします。
PDF 内のテキストを埋め込む
最高の RAG パフォーマンスを発揮するために、扱うデータによってさまざまなテキスト分割の手法を模索する余地があります。ここでは説明を簡潔にするために、パラグラフごとにチャンクとして保存することにします。
ベクトル データベースとのやり取り
このパイプラインをたどると、PDF に含まれるマルチモーダルのあらゆる情報を上手に取り込むことができます。ユーザーが質問したときの RAG パイプラインの動作を説明します。
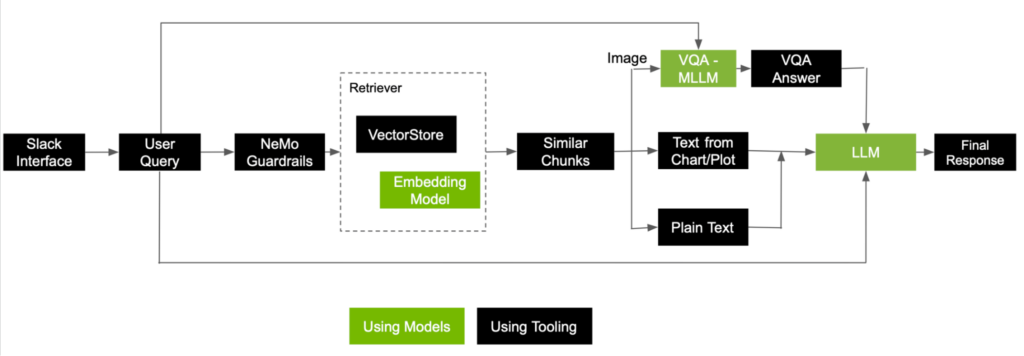
ユーザーがシステムに質問を提示すると、シンプルな RAG パイプラインが質問を埋め込み表現に変換し、意味的検索を実行して、関連する情報のチャンクを取得します。画像からもチャンクが取得されることを考慮して、いくつかの追加の手順を実行してから、すべてのチャンクを LLM に渡して最終的な応答を生成します。
図 5 は、画像とテキストの両方からチャンクとして得られた情報を使って回答する、ユーザーからの問い合わせの処理方法を示した参照フローです。
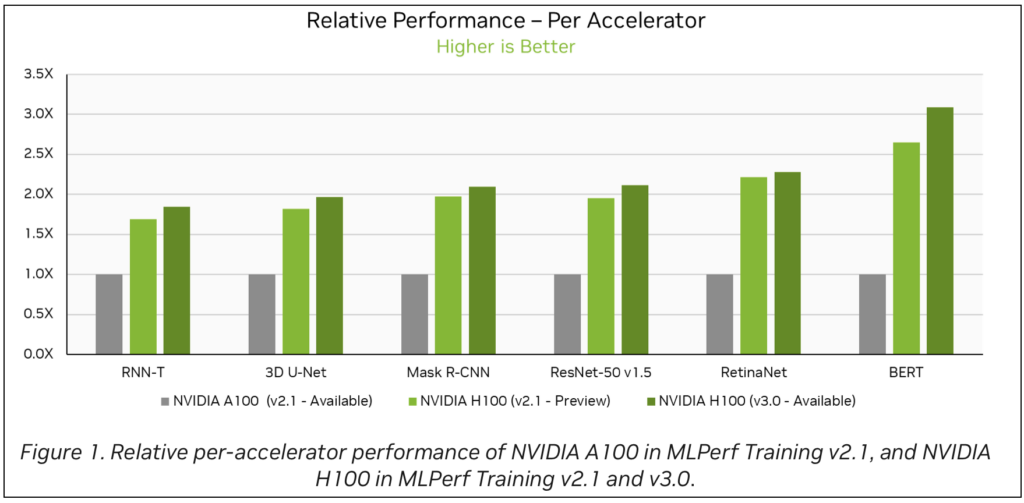
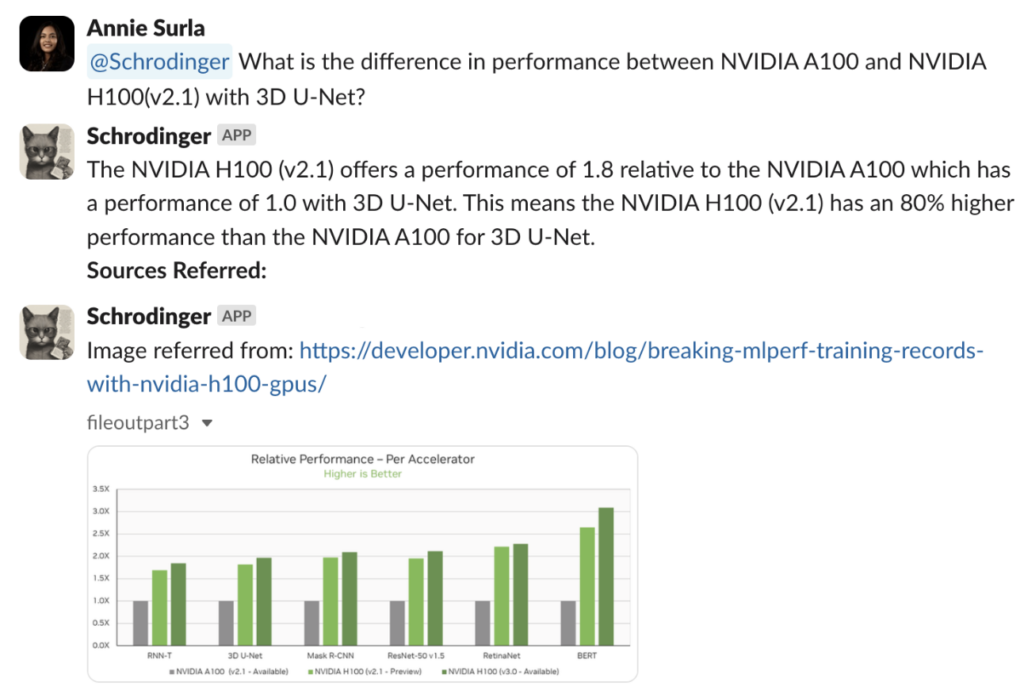
対象の PDF にアクセス可能なマルチモーダルの RAG 対応ボットに、例として “What is the difference in performance between NVIDIA A100 and NVIDIA H100(v2.1) with 3D U-Net?” (3D U-Net のパフォーマンスは、NVIDIA A100 と NVIDIA H100 (v2.1) でどのように違いますか?) という質問を提示します。
このパイプラインは、適切なグラフィック イメージを取得して解釈し、3D U-Net のベンチマークで NVIDIA H100 (v2.1) は NVIDIA A100 よりもアクセラレータあたりの相対パフォーマンスが 80% 高いことを正確に言及することに成功しました。
検索が実行され、関連する上位 5 つのチャンクが取得された後の質問への回答に関わる、いくつかの重要なステップを以下に示します。
- チャンクが画像から抽出された場合、MLLM は画像とユーザーの質問を入力として受け取り、回答を生成します。これは VQA タスクそのものです。ここで生成された回答は、LLM が応答を生成するための最終的なコンテキストとして使用します。
- チャンクがチャートまたはプロットから抽出された場合、メタデータとして保存しておいた線形化した表を呼び出し、このテキストを LLM にコンテキストとして追加します。
- 最後に、プレーン テキストから抽出されたチャンクは、そのまま使用します。
ユーザーからの質問とともにこれらすべてのチャンクを LLM に渡すと、最終的な回答を生成する準備が整います。ボットは、図 6 に示されたソースから、さまざまなベンチマークにおける相対的パフォーマンスを示すグラフを参照し、最終的に正しい応答を生成することができました。
RAG パイプラインの拡張
この記事では、複数のモダリティにまたがるデータを用いてテキストベースの簡単な質問に回答するシナリオについて触れています。マルチモーダル RAG テクノロジの開発をさらに進め、その機能を広げるために、次のような研究分野をお勧めします。
さまざまなモダリティを含むユーザーの質問への対処
ユーザーからの質問が、グラフを含む画像と、質問の一覧で構成されている場合について考えます。このようなマルチモーダルのリクエストに対応するには、パイプラインをどのように変える必要があるでしょうか?
マルチモーダル応答
図 6 に示すように、テキストベースの回答は、他のモダリティの該当データの引用とともに提供されます。ただし、文字による説明は、必ずしもユーザーからの問い合わせに対する最善の結果とは限りません。たとえば、マルチモーダル応答は、リクエストに応じて積み上げ棒グラフなどの画像を生成するところまで、さらに拡張できます。
マルチモーダル エージェント
複雑な質問やタスクの解決は、単純な検索を超えたところにあります。それには、計画、専門的なツール、取り込みエンジンが必要です。詳細については、Introduction to LLM Agents をご覧ください。
まとめ
マルチモーダル モデルの進歩と RAG を活用したツールやサービスに対する需要の増加の高まりにより、生成 AI アプリケーションには、今後のマルチモーダル機能を改善および探求する余地が大いにあります。
マルチモーダルの能力を中核のオペレーションやテクノロジ ツールに統合できる企業は、まだ知られていないユース ケースに向けて AI サービスや製品を拡張していくための準備が整っています。GitHub にあるマルチモーダル RAG ワークフローの実装を実際に体験してみてください。
関連情報
- GTC セッション: Retrieval Augmented Generation: Overview of Design Systems, Data, and Customization
- GTC セッション: Generative AI Theater: Addressing Challenges of Unstructured Enterprise Data With Multimodal Retrieval-Augmented Generation
- GTC セッション: Techniques for Improving the Effectiveness of RAG Systems
- ウェビナー: Building Intelligent AI Chatbots Using RAG
- ウェビナー: Bringing Generative AI to Life with NVIDIA Jetson
- ウェビナー: Fast-Track to Generative AI With NVIDIA