
兆単位パラメーター モデルに対する関心とはどのようなものでしょう? 現在、多くの用途が知られており、また、以下のような能力の拡大が期待されているため、関心が高まっています。
- 翻訳、質疑応答、抽象化、流暢さなどの自然言語処理タスク。
- 長期的なコンテキストと会話能力の保持。
- 言語、視覚、音声を組み合わせたマルチモーダル アプリケーション。
- ストーリーテリング、詩の生成、コードの生成などのクリエイティブ アプリケーション。
- タンパク質の折り畳み構造予測や創薬などの科学的アプリケーション。
- 一貫性のある個性を育み、ユーザー コンテキストを記憶することができるパーソナライゼーション。
メリットは大きいですが、大規模なモデルのトレーニングとデプロイは計算負荷が高く、リソースを大量に消費することがあります。計算効率、費用対効果、エネルギー効率に優れたシステムをリアルタイム推論用に設計することは、広範囲にわたるデプロイには不可欠です。新しい NVIDIA GB200 NVL72 はそのようなタスクに対応するシステムの 1 つです。
説明のために、Mixture of Experts (MoE) モデルを考えてみましょう。このモデルは、モデル並列処理とパイプライン並列処理を使用して、複数のエキスパートに計算負荷を分散し、数千もの GPU をトレーニングするのに役立ち、システムの効率性を上げます。
ただし、新しいレベルの並列計算、高速メモリ、高性能通信により、技術的な課題が GPU クラスターで扱えるようになる可能性があります。NVIDIA GB200 NVL72 ラックスケール アーキテクチャはこの目標を達成します。詳細は以下でご説明します。
エクサスケール AI スーパーコンピューターのラック スケール設計
GB200 NVL72 の心臓部となるのが NVIDIA GB200 Grace Blackwell Superchip です。2 つの高性能 NVIDIA Blackwell Tensor コア GPU と NVIDIA Grace CPU を、毎秒 900 GB の双方向帯域幅を提供する NVLink-Chip-to-Chip (C2C) インターフェイスで接続します。NVLink-C2C を利用することで、アプリケーションは統一されたメモリ空間に一貫してアクセスできます。これにより、プログラミングが簡単になり、兆単位パラメーターの LLM、マルチモーダル タスクの Transformer モデル、大規模シミュレーションのモデル、3D データの生成モデルなど、大量メモリのニーズに対応します。
GB200 コンピューティング トレイは、新しい NVIDIA MGX デザインに基づいています。2 つの Grace CPU と 4 つの Blackwell GPU が含まれています。GB200 には、水冷用のコールド プレートと接続部、高速ネットワーク用の PCIe gen 6 サポート、NVLink ケーブル カートリッジ用の NVLink コネクタがあります。GB200 コンピューティング トレイは、80 ペタフロップスの AI パフォーマンスと 1.7 TB の高速メモリを実現します。

最大規模の問題を解くには、多数の Blackwell GPU が効率的に並列動作する必要があります。そのために高帯域幅・低遅延な GPU 間通信によって、GPU を演算に専念させなければなりません。
GB200 NVL72 ラックスケール システムは、9 つの NVLink スイッチ トレイと、GPU とスイッチを相互接続するケーブル カートリッジを備えた NVIDIA NVLink Switch System を使用し、18 個のコンピューティング ノードの並列モデル効率を上げます。
NVIDIA GB200 NVL36 および NVL72
GB200 の NVLink ドメインは 36 または 72 GPU の構成をサポートします。各ラックは、MGX リファレンス デザインと NVLink Switch System に基づき、18 台のコンピューティング ノードをホストします。GB200 NVL36 は、1 ラックに 18 台のシングル GB200 コンピューティング ノードを搭載する 36 GPU 構成で提供されます。GB200 NVL72 は、18 台のデュアル GB200 コンピューティング ノードを 1 ラックに搭載、あるいは 36 台のシングル GB200 コンピューティング ノードを 2 ラックに分けて搭載する 2 パターンをサポートし、いずれも 72 基の GPU で NVLink ドメインを構成します。
GB200 NVL72 は、銅ケーブル カートリッジを使用して GPU を密にまとめ、相互接続するため、運用がシンプルになります。また、水冷システム設計を採用し、コストとエネルギー消費を 25 分の 1 に抑えます。

第 5 世代 NVLink および NVLink Switch System
NVIDIA GB200 NVL72 には、第 5 世代の NVLink が導入されています。これは 1 つの NVLink ドメインで最大 576 基の GPU を接続し、合計帯域幅は毎秒 1 PB、高速メモリは 240 TB になります。各 NVLink スイッチ トレイは毎秒 100 GB の NVLink ポートを 144 個提供し、9 つのスイッチで 72 基の Blackwell GPU それぞれにある 18 個の NVLink ポートがすべて接続されます。
GPU あたり毎秒 1.8 TB という画期的な双方向スループットは、PCIe Gen5 の 14 倍を超える帯域幅であり、今日の最も複雑な大規模モデルにシームレスな高速通信を提供します。

NVLink の歴史
NVIDIA の業界をリードする革新的な高速低電力 SerDes は、マルチ GPU 通信を大幅に加速する NVLink の導入に始まり、GPU 間通信の進歩を促進しています。NVLink の GPU 間の帯域幅は毎秒 1.8 TB であり、PCIe の帯域幅の 14 倍です。第 5 世代の NVLink は、2014 年に導入された第 1 世代の毎秒 160 GB に比べて 12 倍の速さです。NVLink の GPU 間通信は、AI と HPC でマルチ GPU パフォーマンスを拡大するのに役立ってきました。
GPU 帯域幅の増加と NVLink ドメインの爆発的な拡張により、NVLink ドメインの合計帯域幅が 2014 年以降、900 倍になり、576 基の Blackwell GPU NVLink ドメインでは毎秒 1 PB になりました。
ユース ケースとパフォーマンス結果
GB200 NVL72 のコンピューティング機能と通信機能はかつてないほど優秀になり、AI と HPC における難題も解決可能なところまで来ています。
AI トレーニング
GB200 には、FP8 精度を特長とする高速の第 2 世代 Transformer Engine が搭載されています。32,000 基の GB200 NVL72 で GPT-MoE-1.8T などの大規模言語モデルをトレーニングすると、同数の NVIDIA H100 GPU と比較してスピードが 4 倍になります。
AI 推論
GB200 には、LLM 推論ワークロードを高速化する最新式の機能と第 2 世代 Transformer Engine が導入されています。前世代の H100 世代と比較して、1.8T パラメーターの GPT-MoE など、リソースを大量に消費するアプリケーションでスピードが 30 倍になります。この進歩は、FP4 精度が導入された新世代の Tensor コアと、第 5 世代 NVLink に付随するさまざまな利点によって可能になりました。
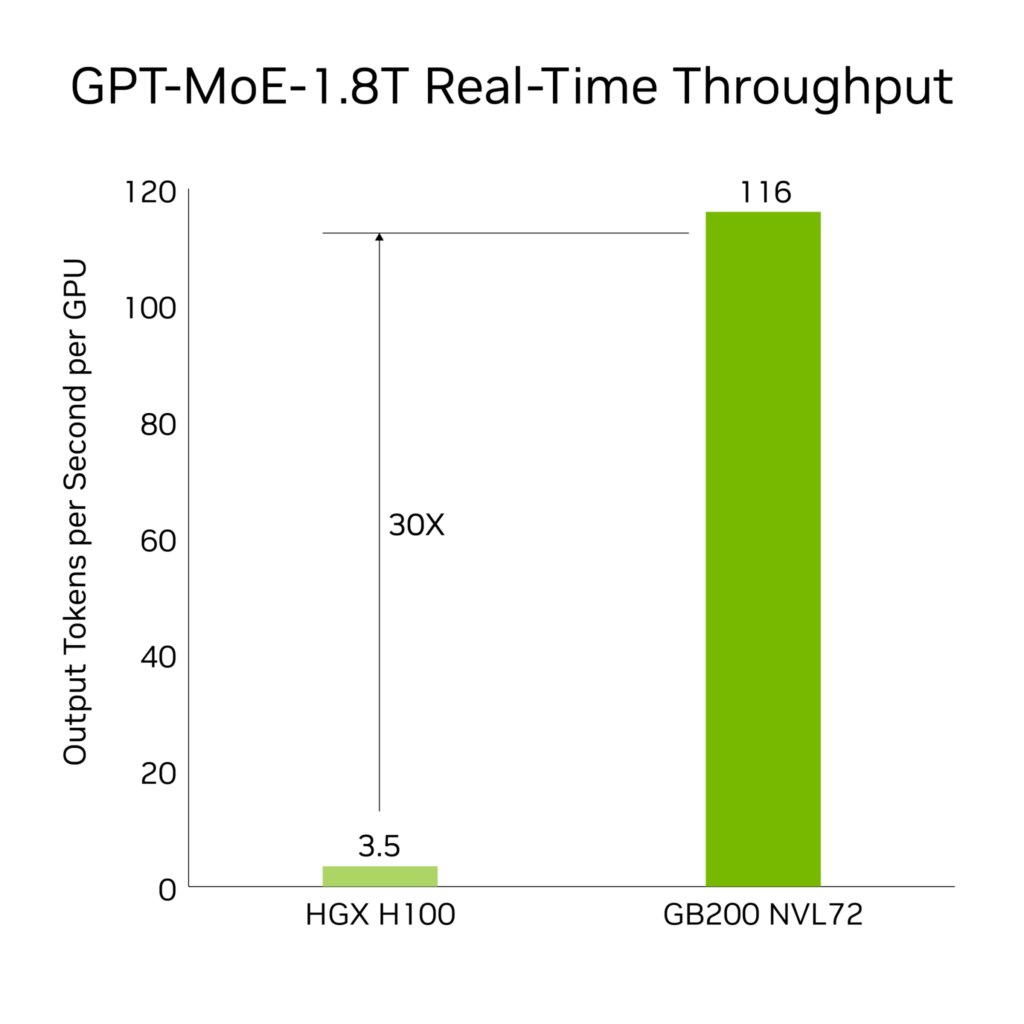
結果は次をベースとする: トークン間のレイテンシ (TTL) = 50ms、リアルタイム、最初のトークンのレイテンシ (FTL) = 5,000ms、入力シーケンス長 = 32,768、出力シーケンス長 = 1,024 出力、8x 8ウェイ HGX H100 空冷: 400 GB IB ネットワークと 18 GB200 Superchip 水冷: NVL36 の比較、GPU ごとのパフォーマンス比較。予想されるパフォーマンスは変更される可能性があります。
データ処理
ビッグ データ分析は、組織が洞察や知見を引き出し、情報に基づいて意思決定するのを支援します。組織は大規模なデータを継続的に生成し、さまざまな圧縮技術を利用してボトルネックを緩和し、ストレージ コストを節約しています。こうしたデータセットを GPU 上で効率的に処理するために、Blackwell アーキテクチャでは、圧縮された大量のデータをネイティブに伸張し、分析パイプラインをエンドツーエンドで高速化できる、ハードウェアの Decompression Engine を導入しています。この Decompression Engine は、LZ4、Deflate、Snappy で圧縮されたデータに対応しています。
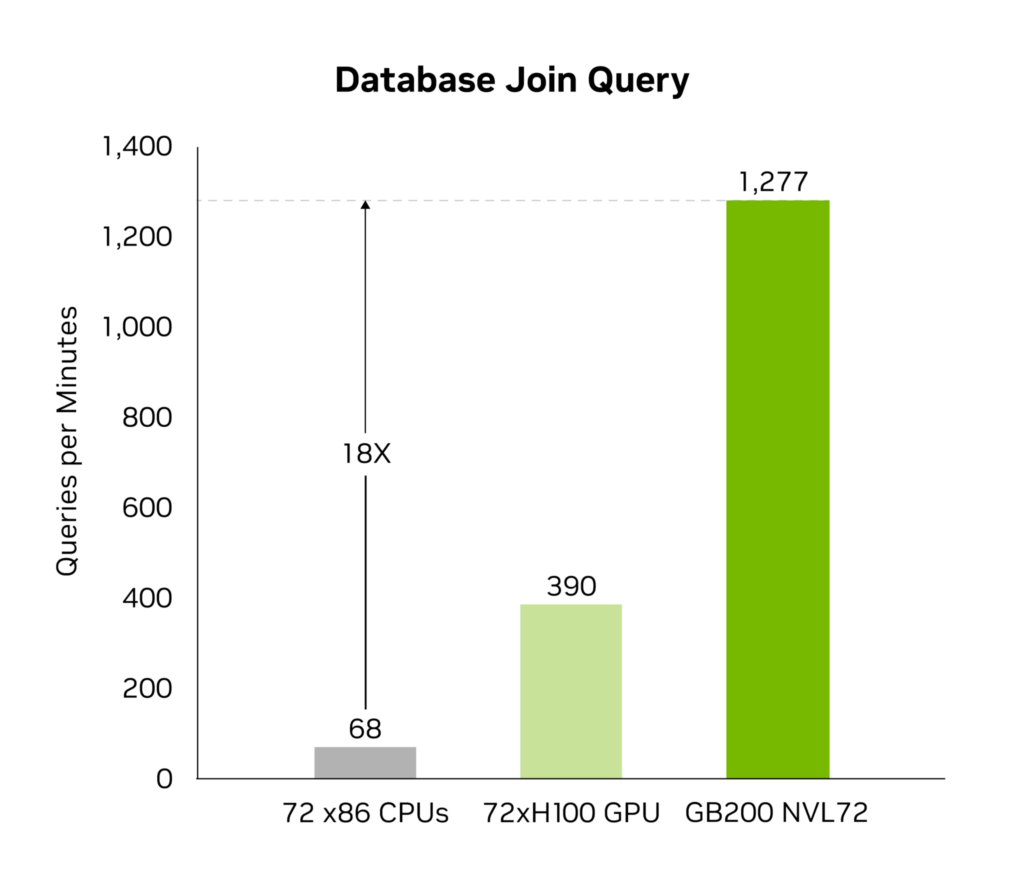
Decompression Engine は、メモリにバインドされたカーネル操作を高速化します。パフォーマンスが毎秒最大 800 GB になり、Grace Blackwell はクエリ ベンチマークで CPU (Sapphire Rapids) の 18 倍、NVIDIA H100 Tensor コア GPU の 6 倍の速さになります。
毎秒 8 TB という強烈な高メモリ帯域幅と Grace CPU との高速 NVlink-Chip-to-Chip (C2C) を備えたこのエンジンは、データベース クエリ プロセス全体を高速化します。その結果、データ分析やデータ サイエンスのユース ケースで最高のパフォーマンスを発揮します。これにより、組織はコストを削減しながら、迅速に知見や洞察を得ることができます。
物理学ベースのシミュレーション
物理学ベースのシミュレーションは依然として製品設計と開発の中心です。飛行機や列車から橋梁、シリコン チップ、さらには医薬品に至るまで、シミュレーションによる製品のテストと改善により数十億ドルのコストが削減されています。
特定用途向け集積回路は、電圧と電流を特定するためのアナログ解析を含む長く複雑なワークフローにおいて、ほぼ CPU 上のみで設計されています。Cadence SpectreX シミュレーターはソルバーの一例です。以下の図は、SpectreX が GB200 で x86 CPU より 13 倍速く動作することを示しています。
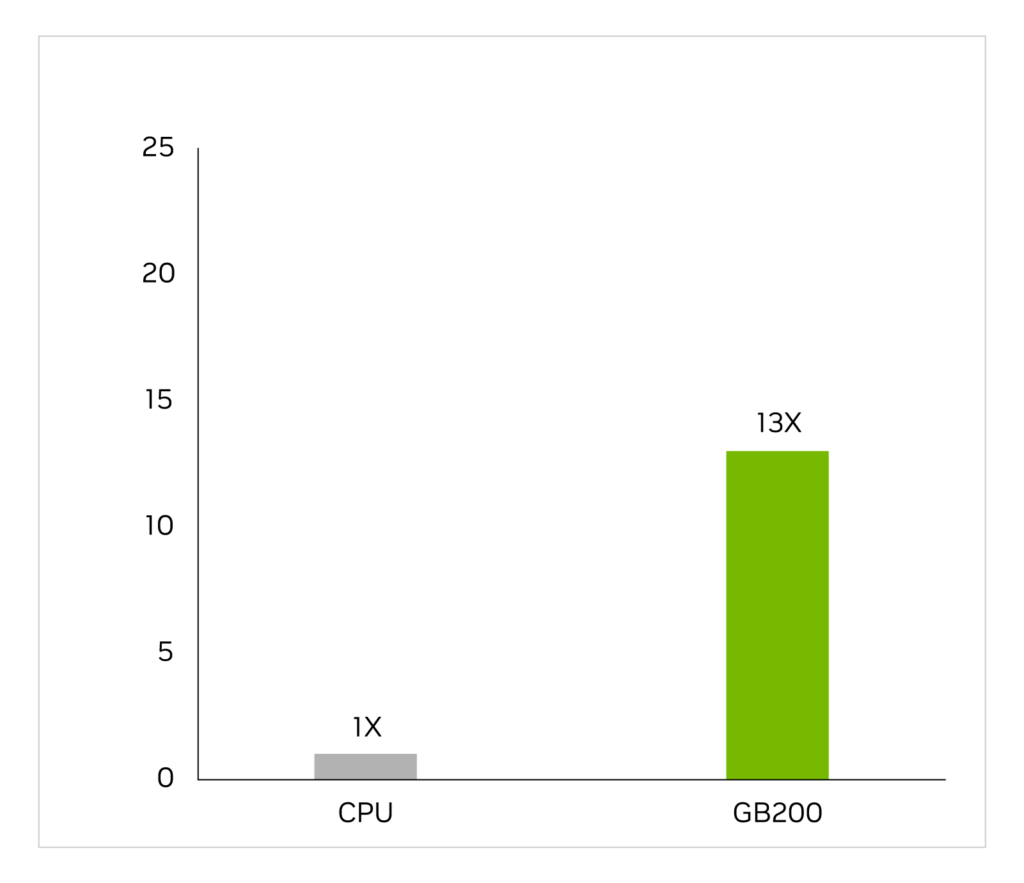
Cadence SpectreX (Spice シミュレーター) | CPU: 16 コア AMD Milan 75F3 データセット: KeithC Design TSMC N5 | GB200 のパフォーマンス予測は変更されることがあります
この 2 年間でこの業界では、GPU を活用した数値流体力学 (CFD) を重要なツールとして使用する機会が増えました。エンジニアや機器の設計者はこれを使用して設計の動作を研究し、予測しています。大渦シミュレーター (LES) である Cadence Fidelity は、GB200 で x86 CPU より最大 22 倍の速度でシミュレーションを実行します。
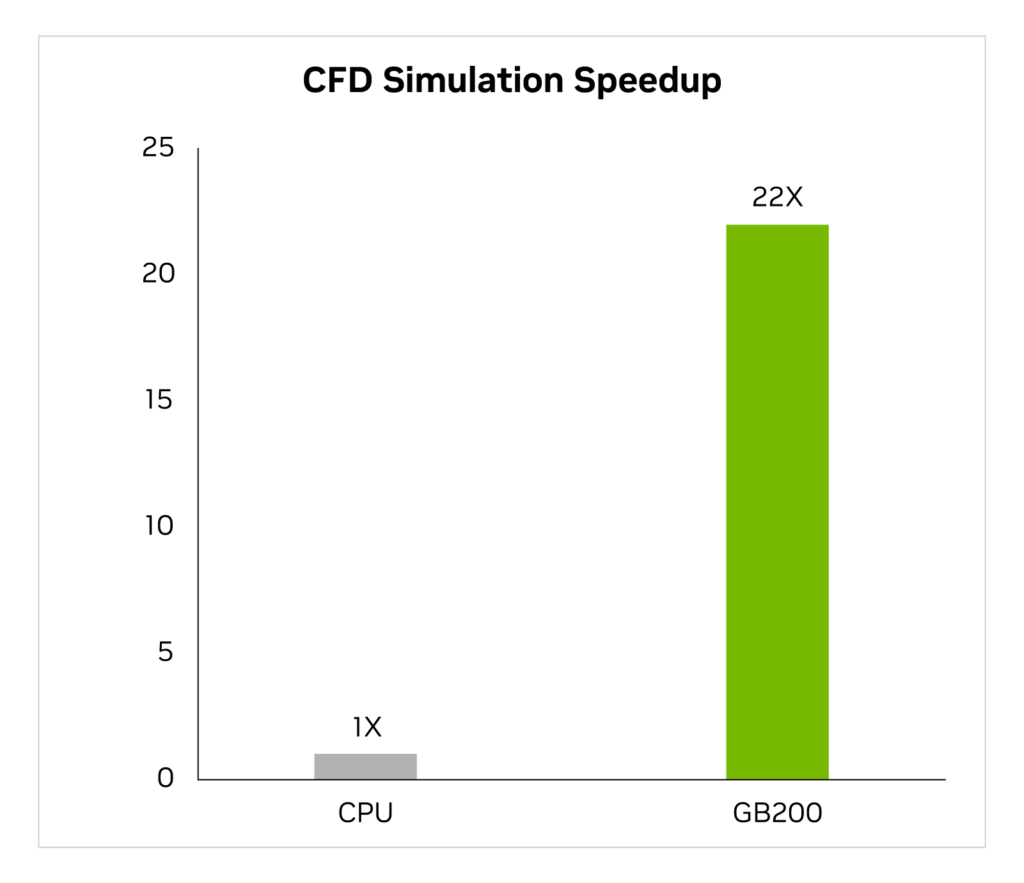
Cadence Fidelity (LES CFD ソルバー)| CPU: 16 コア AMD Milan 75F3 データセット: GearPump 2M セル | GB200 のパフォーマンス予測は変更されることがあります
NVIDIA は、GB200 NVL72 で Cadence Fidelity の可能性を探求することを楽しみにしています。並列スケーラビリティとラックあたり 30 TB のメモリにより、これまで捉えられたことがない細部までフローを捉えることを目指しています。
まとめ
要約すると、GB200 NVL72 ラックスケール設計をレビューし、特に、シングル NVIDIA NVLink ドメインで 72 基の Blackwell GPU を接続する独自の機能について学んできました。この機能により、従来のネットワークによるスケーリングで発生する通信オーバーヘッドが軽減されます。結果、1.8T パラメーターの MoE LLM のリアルタイム推論が可能になり、そのモデルのトレーニングが 4 倍速くなります。
NVLink で接続された 72 基の Blackwell GPUにより、毎秒 130 TB のコンピューティング ファブリックで合計 30 TB のユニファイド メモリを利用可能な、シングル ラックの exaFLOP AI スーパーコンピューターができます。それが NVIDIA GB200 NVL72 です。
関連情報
- GTC セッション: LLM Inference Sizing: Benchmarking End-to-End Inference Systems
- GTC セッション: Enable Hybrid Training and Inference With DGX Cloud and OCI GPU Infrastructure (Presented by Oracle)
- GTC セッション: Optimizing and Scaling LLMs With TensorRT-LLM for Text Generation
- NGC コンテナー: NVIDIA NIM for LLMs
- NGC コンテナー: NVIDIA K8s Developer LLM Operator
- NGC コンテナー: NVIDIA MLPerf Inference