DEVELOPER
ホーム
ブログ
フォーラム
ドキュメント
ダウンロード
トレーニング
検索する
Join
Deep dive
2026 年 4 月 8 日
NVIDIA Omniverse ライブラリを活用した、フィジカル AI 機能の既存アプリへの統合
NVIDIA Omniverse は、既存アプリにフィジカル AI 機能を統合しやすくするため、レンダリング (ovrtx)、物理シミュレーション (ovphysx)、データ パイプライン (ovstorage) を C API として公開しています。
4 MIN READ
NVIDIA Omniverse ライブラリを活用した、フィジカル AI 機能の既存アプリへの統合
2026 年 3 月 13 日
NVIDIA Cosmos 世界基盤モデルによる、合成データのスケールアップとフィジカル AI リーズニングの実現
トレーニング データ不足の問題を解決する、最新の Cosmos WFM (世界基盤モデル)、フィジカル AI を進化させる主な機能、そしてそれらの使用方法について解説します。
3 MIN READ
NVIDIA Cosmos 世界基盤モデルによる、合成データのスケールアップとフィジカル AI リーズニングの実現
2026 年 1 月 6 日
NVIDIA Spectrum-X イーサネット フォトニクス による電力効率に優れた AI ファクトリーの拡張
AI ファクトリーのために開発された、電力効率に優れ、信頼性、回復力に優れたコパッケージド オプティカル ネットワークを実現する Spectrum-X イーサネット フォトニクスのプロトコルとハードウェアにおける主要な最適化と革新について探ります。
2 MIN READ
NVIDIA Spectrum-X イーサネット フォトニクス による電力効率に優れた AI ファクトリーの拡張
2026 年 1 月 5 日
NVIDIA Rubin プラットフォームの内部: 6 つの新チップと AI スーパーコンピューター
AI は産業化段階に移行しています。 個別の AI モデルのトレーニングや人と直接対話する推論を実行するシステムとして始まった AI は、
13 MIN READ
NVIDIA Rubin プラットフォームの内部: 6 つの新チップと AI スーパーコンピューター
2025 年 10 月 28 日
NVIDIA Nemotron の新しいモデル (Vision、RAG、ガードレール) で特化型 AI エージェントを開発
新しい Nemotron モデルを活用して、マルチモーダル エージェント、RAG パイプライン、コンテンツ安全性を備えた AI を構築する方法や、各モデルの特長、性能、チュートリアルを紹介します。
3 MIN READ
NVIDIA Nemotron の新しいモデル (Vision、RAG、ガードレール) で特化型 AI エージェントを開発
2025 年 9 月 29 日
NVIDIA Isaac Lab と Newton で四足歩行の移動ポリシーをトレーニングし、布の操作をシミュレートする
物理演算はロボティクス シミュレーションで重要な役割を果たし、
3 MIN READ
NVIDIA Isaac Lab と Newton で四足歩行の移動ポリシーをトレーニングし、布の操作をシミュレートする
2025 年 5 月 18 日
NVIDIA ARC-Compact を活用して、セル サイトに AI-RAN を展開
NVIDIA ARC-Compact があれば、高性能で電力効率に優れ、柔軟な AI-RAN ソリューションをあらゆるセル サイトで展開できます。
4 MIN READ
NVIDIA ARC-Compact を活用して、セル サイトに AI-RAN を展開
2025 年 2 月 6 日
NeMo Framework と Megatron-Core の特徴や最新機能を紹介した動画コンテンツを NVOD で公開
NVIDIA は 2024 年 11 月 12 日に、大規模言語モデル (LLM)…
2 MIN READ
NeMo Framework と Megatron-Core の特徴や最新機能を紹介した動画コンテンツを NVOD で公開
2024 年 12 月 17 日
NVIDIA Jetson Orin Nano 開発者キットを「Super」に強化
Jetson Orin Nano 開発者キットが、最大 1.7 倍の驚異的なパフォーマンス向上と新たな価格として $249 を実現しつつ、NVIDIA Jetson Orin Nano Super 開発者キットへと名称が変更されました。
4 MIN READ
NVIDIA Jetson Orin Nano 開発者キットを「Super」に強化
2024 年 11 月 22 日
Hymba ハイブリッド ヘッド アーキテクチャが小規模言語モデルのパフォーマンスを向上
Hymba 1.5B は、同様の規模である最先端のオープンソース モデルと比べ、良好なパフォーマンスを発揮し、同等のサイズの Transformer モデルで比較すると、Hymba はより高いスループットを発揮し、キャッシュを保存するために必要なメモリが 10 分の 1 で済みます。
4 MIN READ
Hymba ハイブリッド ヘッド アーキテクチャが小規模言語モデルのパフォーマンスを向上
2024 年 11 月 13 日
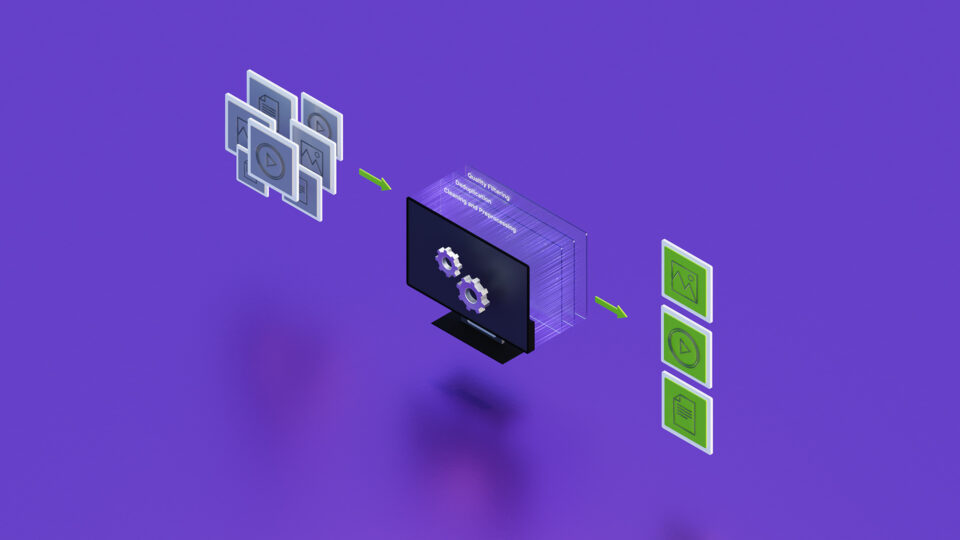
LLM テクニックの習得: データの前処理
LLM の精度向上におけるデータ品質は重要であり、さまざまなデータ処理手法があります。NeMo Curator を利用して今すぐ課題に対処してみましょう。
2 MIN READ
LLM テクニックの習得: データの前処理
2024 年 11 月 11 日
Megatron-LM を用いた日本語に強い 172B 大規模言語モデルの開発
日本のモデル開発を促進するためのプロジェクトである GENIAC に採択された LLM-jp が、NVIDIA Megatron-LM を使用して、日本語に強い 172B オープンモデルの学習を高速化しました。
2 MIN READ
Megatron-LM を用いた日本語に強い 172B 大規模言語モデルの開発
2024 年 10 月 31 日
NVIDIA NIM によるマルチモーダル ビジュアル AI エージェントの構築
NVIDIA NIM マイクロサービスを使用すれば、高度なビジュアル AI エージェントの構築がこれまで以上に簡単で効率的になります。
3 MIN READ
NVIDIA NIM によるマルチモーダル ビジュアル AI エージェントの構築
2024 年 10 月 8 日
通信会社に AI-RAN を提供
NVIDIA は、同じコンピューティング インフラストラクチャを使用して AI サービスと無線アクセス ネットワーク (RAN) サービスの処理が可能な AI-RAN の展開プラットフォームである Aerial RAN Computer-1 を導入しています。
5 MIN READ
通信会社に AI-RAN を提供
2024 年 10 月 8 日
NVIDIA cuOpt で大規模な線形計画問題を加速する
NVIDIA cuOpt は現在、GPU アクセラレーションで PDLP を実装しています。最先端のアルゴリズム、NVIDIA ハードウェア、専用の CUDA 機能、NVIDIA GPU ライブラリを使用して、cuOpt LP ソルバーは、CPU ベースのソルバーと比較して 5,000 倍以上の高速パフォーマンスを実現しています。
3 MIN READ
NVIDIA cuOpt で大規模な線形計画問題を加速する
2024 年 9 月 30 日
NVIDIA NIM Operator で Kubernetes の AI 推論パイプラインを管理
NIM Operator を使用すれば、わずか数回のクリックまたはコマンドで、NVIDIA NIM マイクロサービスのデプロイ、オートスケーリング、ライフサイクルを管理することができます。
2 MIN READ
NVIDIA NIM Operator で Kubernetes の AI 推論パイプラインを管理
詳細を見る