
Today’s AI-powered applications are enabling richer experiences, fueled by both larger and more complex AI models as well as the application of many models in a pipeline. To meet the increasing demands of AI-infused applications, an AI platform must not only deliver high performance but also be versatile enough to deliver that performance across a diverse range of AI models. To maximize infrastructure utilization and optimize CapEx, the ability to run the entire AI workflow on the same infrastructure is critical: from data prep and model training to deployed inference.
MLPerf benchmarks have emerged as industry-standard, peer-reviewed measures of deep learning performance, covering AI training, AI inference, and high-performance computing (HPC). MLPerf Inference 2.1, the latest iteration of the MLPerf Inference benchmark suite, covers a breadth of common AI use cases including recommenders, natural language processing, speech recognition, medical imaging, image classification, and object detection.
In this round, NVIDIA made its first MLPerf submissions on the latest NVIDIA H100 Tensor Core GPU based on the breakthrough NVIDIA Hopper Architecture.
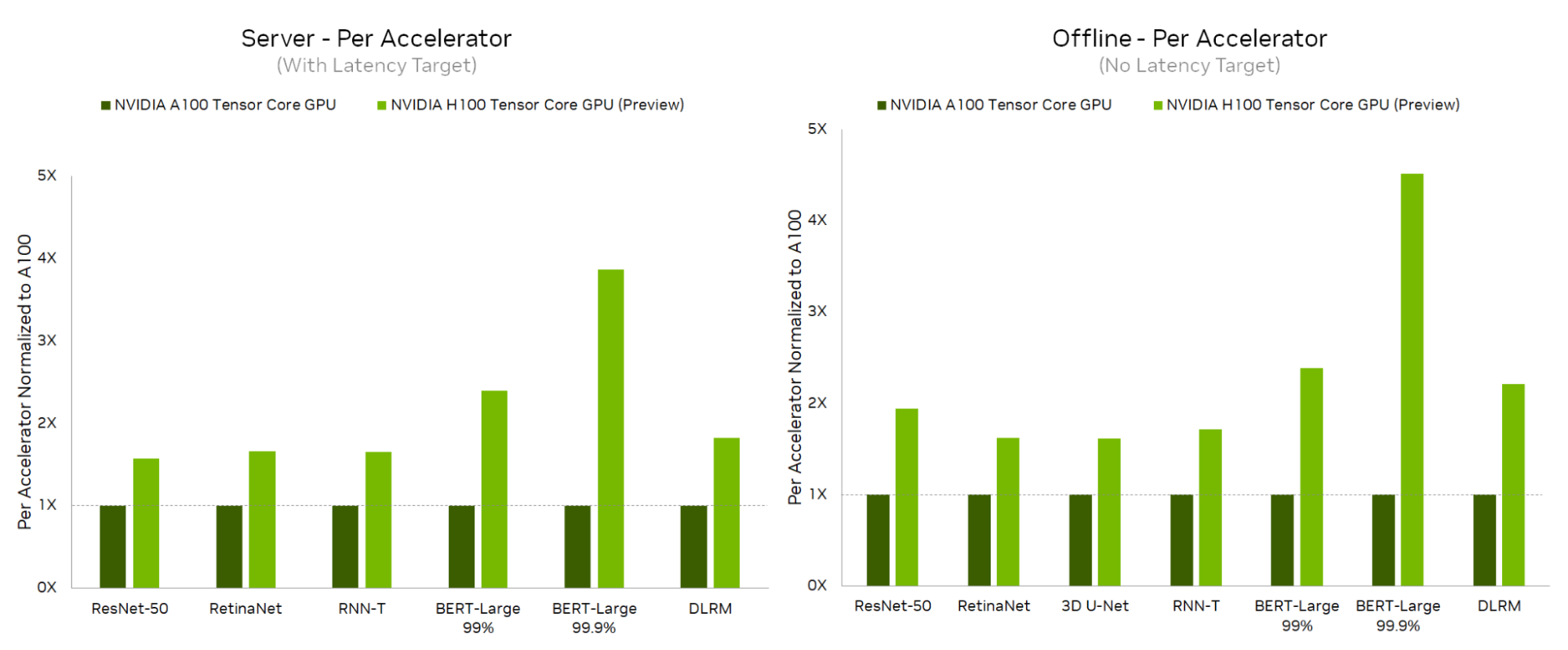
- H100 set new per-accelerator records on all data center tests, demonstrating up to 4.5x higher inference performance compared to the NVIDIA A100 Tensor Core GPU.
- A100 continued to demonstrate excellent performance across the full suite of MLPerf Inference 2.1 tests for both the data center and edge inference scenarios.
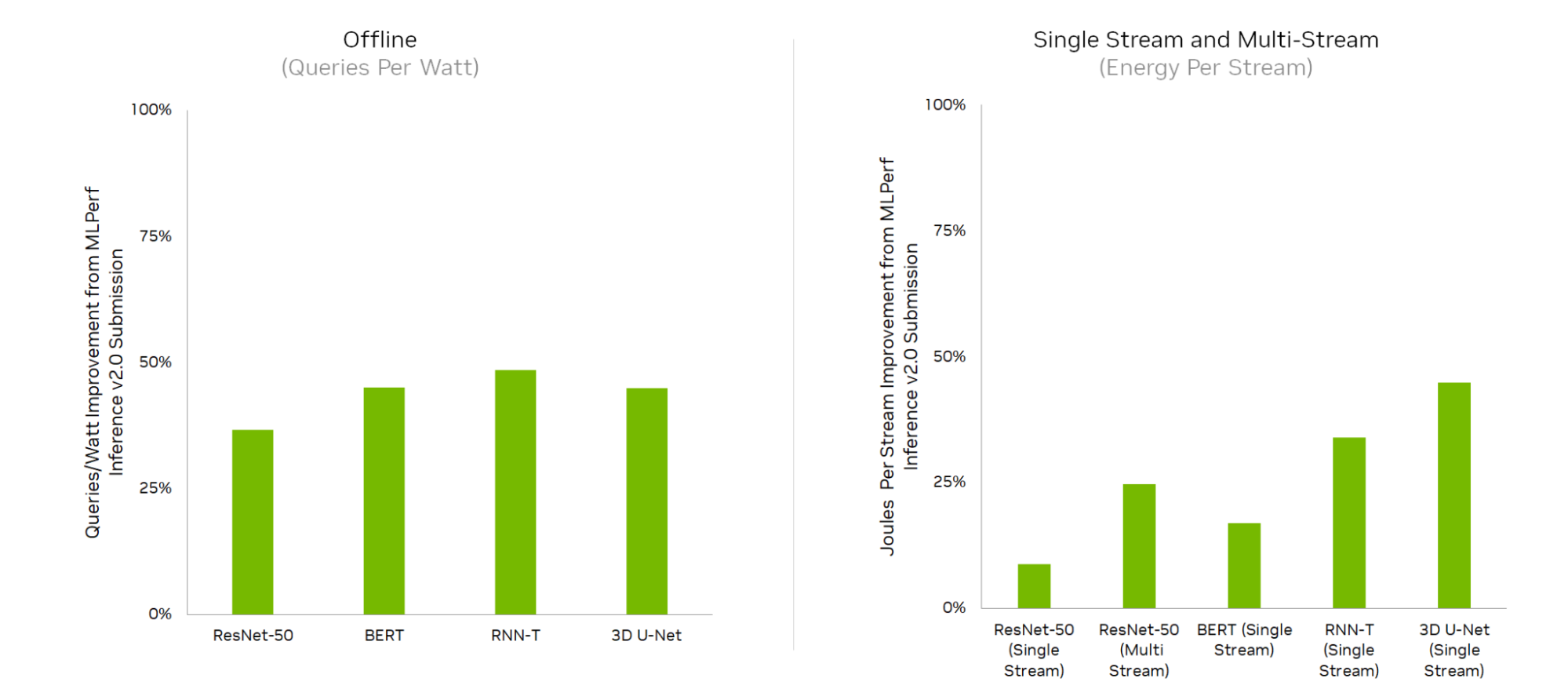
NVIDIA Jetson AGX Orin, built for edge AI and robotics applications, also delivered up to a 50% improvement in performance-per-watt following its debut in the prior round of MLPerf Inference, and ran all edge workloads and scenarios.
Delivering these performance results required deep software and hardware co-optimization. In this post, we discuss the results and then dive into some of the key software optimizations.
NVIDIA H100 Tensor Core technology
On a per-streaming multiprocessor (SM) basis, the H100 Tensor Cores provide twice the matrix multiply-accumulate (MMA) throughput clock-for-clock of the A100 SMs when using the same data types and four times the throughput when comparing FP16 on an A100 SM to FP8 on an H100 SM. New kernels had to be developed in order to leverage several of the H100’s new capabilities and to take advantage of these dramatically faster Tensor Cores.
The H100 Tensor Cores process data so rapidly that it can be challenging to keep them both fed with enough input data and to post-process their output data. Kernels must create an efficient pipeline such that data loading, Tensor Core processing, post-processing, and storage all happen simultaneously and efficiently.
The new H100 asynchronous transaction barriers are instrumental to the efficiency of these pipelines. The asynchronous barriers allow producer threads to run ahead after signaling data availability. In the case of data loading threads, this provides significant improvement in kernels’ ability to hide memory system latencies and ensure a steady stream of input data is available for the Tensor Cores. The asynchronous transaction barriers also provide an efficient mechanism for consumer threads to wait on resource availability so that they don’t waste SM resources in spin loops.
The Tensor Memory Accelerator (TMA) further turbocharges these kernels. The TMA was designed to natively integrate into asynchronous pipelines, and provides for the asynchronous transfer of multi-dimensional tensors from global memory into the SM’s shared memory.
The Tensor Cores are so fast that operations like address calculation can become a performance bottleneck; the TMA offloads this work so that the kernels can focus on running the math and post-processing as quickly as possible.
Finally, the new kernels employ H100 thread block clusters to exploit locality at the GPU processing cluster (GPC). The thread blocks within each thread block cluster collaborate to load data more efficiently and provide higher input bandwidth to the Tensor Cores.
NVIDIA H100 Tensor Core GPU performance results
Starting with the Data Center category, the NVIDIA H100 Tensor Core GPU delivered the highest per-accelerator performance on every workload across both the Server and Offline scenarios, delivering up to 4.5x more performance in the Offline scenario and up to 3.9x more performance in the Server scenario than the A100 Tensor Core GPU.
Thanks to full-stack improvements, NVIDIA Jetson AGX Orin turned in large improvements in energy efficiency compared to the last round, delivering up to a 50% efficiency improvement.
Here’s a closer look at the software optimizations that made these results possible.
High-performance BERT inference using FP8
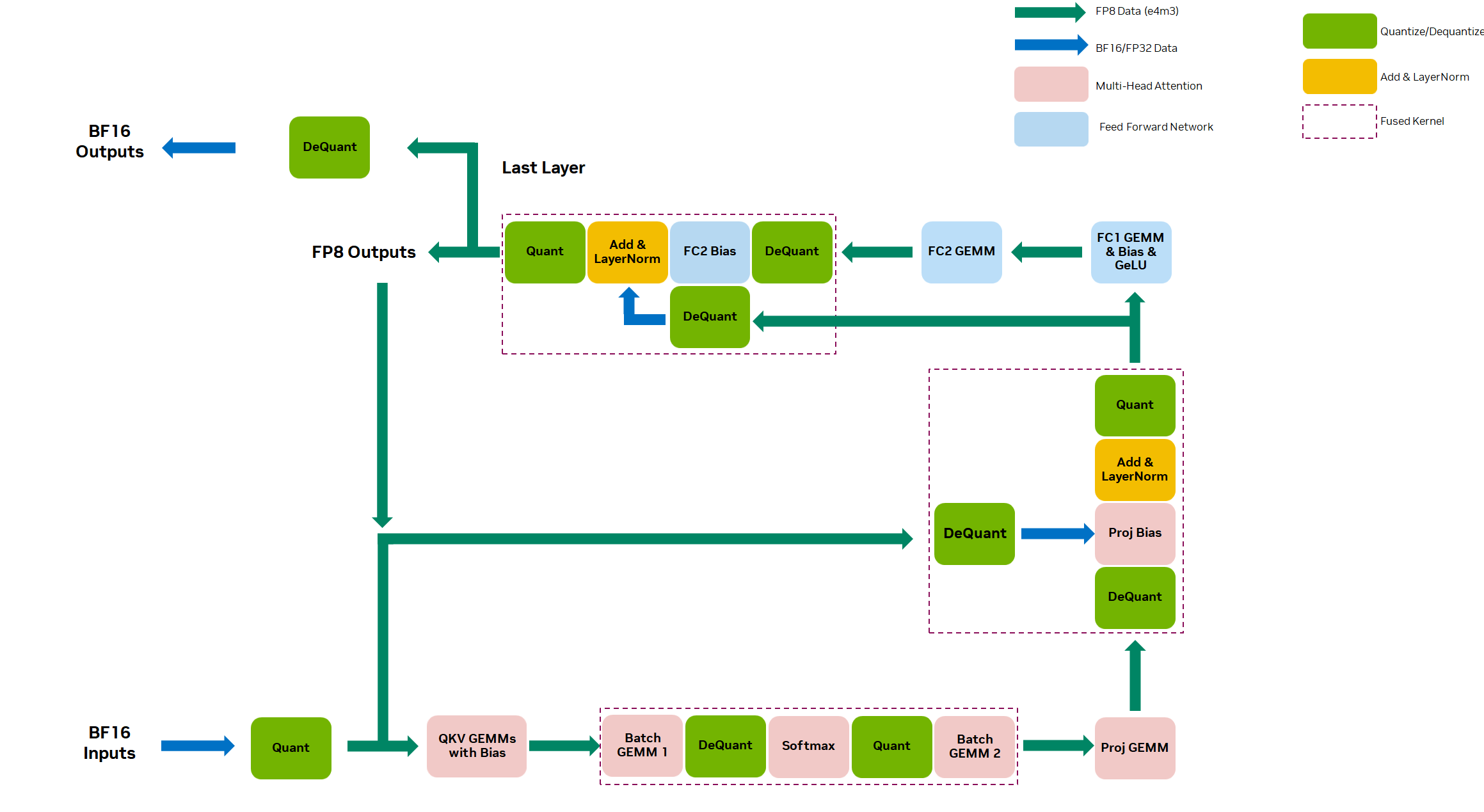
The NVIDIA Hopper Architecture incorporates new fourth-generation Tensor Cores with support for two new FP8 data types: E4M3 and E5M2. These new data types increase Tensor Core throughput by 2x and reduce memory requirements by 2x compared to 16-bit floating-point.
The E4M3 offers an additional mantissa bit, which leads to increased stability in the first step of the calculation process, known as the forward pass. The additional exponent bit of E5M2 is more helpful for preventing overflow/underflow during the backward pass. For our BERT FP8 submission, we used E4M3.
Our experiments on NLP models like BERT showed that when quantizing the model from a higher precision (FP32) to a lower precision (such as FP8 or INT8), the drop in accuracy observed with FP8 is lower than that of INT8.
Although we can use quantization aware training (QAT) to recover some of the model accuracy with INT8, the accuracy of INT8 under post training quantization (PTQ) remains a challenge. This is where FP8 is beneficial: It can provide 99.9% accuracy of the FP32 model under PTQ without the additional cost and effort required to run QAT. As a result, FP8 can be used for the 99.9% high accuracy category of MLPerf where previously FP16 was required. In essence, FP8 delivered the performance of INT8 with the accuracy of FP16 for this workload.
In the NVIDIA BERT submission, all fully connected and matrix multiply layers in the encoder used FP8 precision. The implementation of these layers used cuBLASLt to perform the FP8 GEMMs on the H100 Tensor Cores.
Key BERT optimizations were extended to support FP8, including the following:
- Removing padding: Inputs to BERT have variable sequence lengths, and are padded to a maximum sequence length. We strip the padding to avoid wasting compute on padding, and then reconstruct the padded sequences for the final output to match the input shape.
- Fused multi-head attention: This is a fusion of four operations: transpose Q/K, Q*K, softmax, and QK*V to compute the attention. Fused multi-head attention enhances memory efficiency, skipping the padding to prevent useless computing. Fused multi-head attention provides roughly a 2x end-to-end speedup.
- Activation fusion: We fuse the GEMM with more operations, including bias and activation functions (GeLU). This fusion also helps enhance memory efficiency by removing extra memory transfers.
RetinaNet for object detection
In MLPerf Inference 2.1, a new one-stage object detection model named RetinaNet was added. This replaced the ssd-resnet34 and ssd-mobilenet workloads of MLPerf Inference 2.0. This updated model architecture and its new inference dataset bring new challenges in delivering fast, accurate, and power-efficient inference.
NVIDIA submitted results for RetinaNet across all the platforms demonstrating the width of our software support.
RetinaNet is trained and inferred using the Open Images dataset, which contains an order of magnitude more object categories and object notations than the COCO dataset used earlier. For RetinaNet, 264 unique classes are selected for training and inference tasks. This is significantly more than the 81 classes used for ssd-resnet34.

Although RetinaNet is also a single-shot object detection model, it has several key differences compared to ssd-resnet34:
- RetinaNet uses Feature Pyramid Network (FPN) as its backbone on top of a feedforward ResNeXt architecture. ResNeXt uses group convolution in its computation blocks, and has different math characteristics from that of ResNet34.
- For every image, 120,087 boxes and 264 unique class scores per box are fed into the non-maximum suppression (NMS) layer, and the top 1,000 scoring boxes are selected for outputs. In ssd-resnet34, these numbers were 25x lesser: 15,130 boxes, 81 classes per box, and 200 topK.
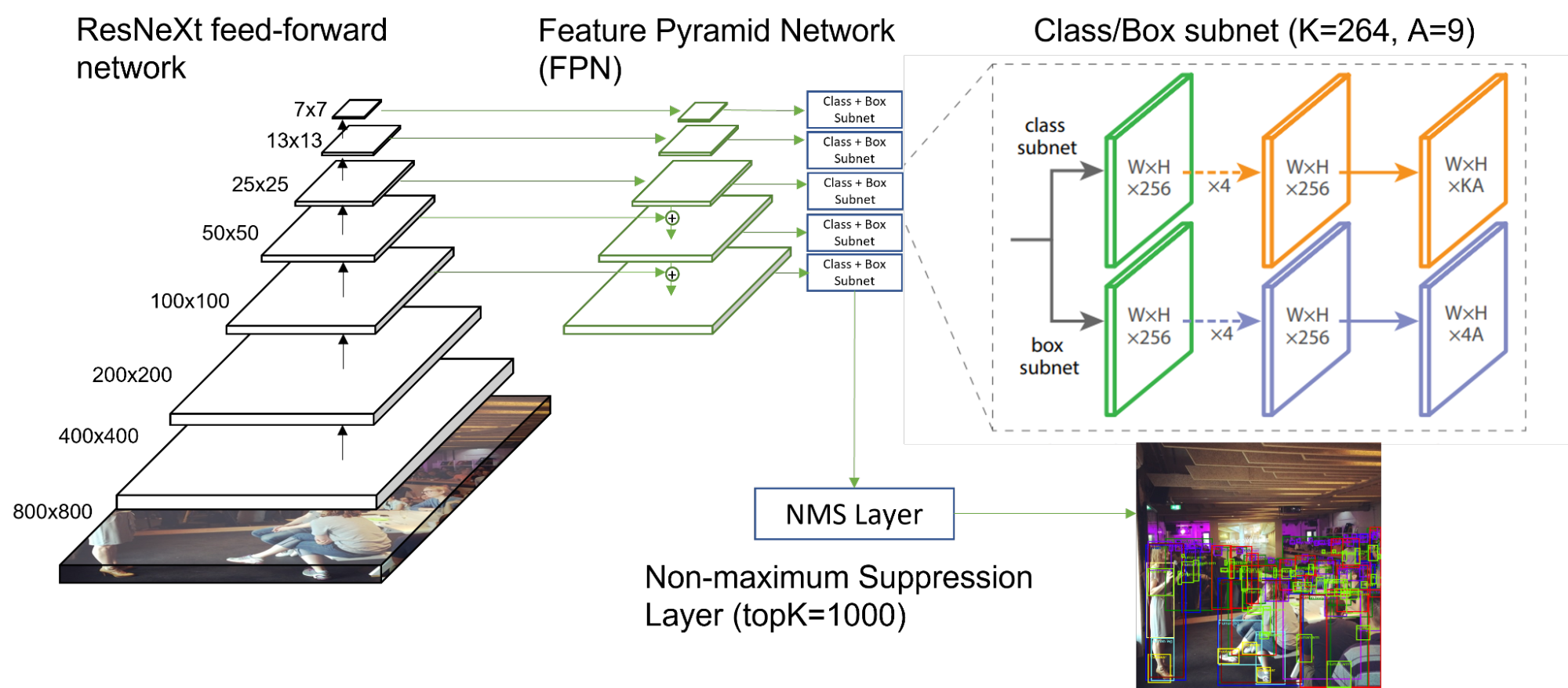
NVIDIA used TensorRT as the backend for RetinaNet. TensorRT significantly accelerates inference throughput by automatically optimizing both the graph execution and layer execution:
- TensorRT provides full support to execute the model inference in mixed FP32/INT8 precision, with minimal accuracy loss compared to FP16 and FP32 precision.
- TensorRT automatically selects optimized kernels for group convolutions across all 16 ResNeXt blocks.
- TensorRT provides fusion patterns for convolution, activation, and (optional) pooling layers, which optimize the memory movement for faster inference by merging the layer weights and reducing the number of operations.
- For the post-processing NMS layer, NVIDIA leverages EfficientNMS, which is an open-sourced high-performance CUDA kernel specialized for NMS tasks, provided as a TensorRT plugin.
NVIDIA Jetson AGX Orin optimizations
NVIDIA Jetson AGX Orin is the latest NVIDIA platform for edge AI and robotics applications. In this round of MLPerf Inference, Jetson AGX Orin demonstrated excellent performance and energy efficiency improvements across the breadth of MLPerf Inference 2.1 edge workloads. Improvements included a 45% reduction in ResNet-50 multi-stream latency and a 17% boost in BERT offline throughput over the previous round (v2.0). In the power submission, Orin achieved up to 52% power reduction and 48% perf-per-watt improvement on selected benchmarks. The submissions used the 22.08 Jetson CUDA-X AI Developer Preview software, which includes an optimized NVIDIA Jetson Linux (L4T) image, TensorRT 8.5.0, CUDA 11.4.14, and cuDNN 8.5.0, allowing customers to easily benefit from these same improvements. RetinaNet is fully supported and performant on Jetson AGX Orin with this software stack. This demonstrates the ability of the NVIDIA platform and software to support performant DL inference out-of-the-box.
NVIDIA Orin performance improvements
The significant improvement in MLPerf-Inference v2.1 came from both the general performance boost enabled by the system image and TensorRT 8.5 in 22.08 Jetson CUDA-X AI Developer Preview. The optimized Jetson L4T image provides users access to MaxN power mode, which boosts the frequencies of both the GPU and the DLA units. Meanwhile, this image has the option to use an enlarged page size of 64K that can reduce TLB cache misses when running certain inference workloads. Furthermore, the 3.10.1 DLA compiler natively included in the image incorporates a series of optimization features, which increases the performance of workloads running on the Orin DLA by up to 53%.
TensorRT 8.5 includes two new optimizations that improve inference performance. The first is native support for cuDLA which removes the imposition of inserting copy nodes between DLA nodes and GPU nodes. We observed approximately 1.8% DLA engine end-to-end improvements switching from NVMedia to cuDLA. The second is the addition of optimized kernels for small channel * filter size convolutions fused with a beta=1 residual connection. This improved BERT performance by 17% and ResNet50 by 5% on the GPU in Orin.
NVIDIA Orin energy efficiency improvements
The NVIDIA Orin power submission benefited from all the above performance improvements and also focused on further power reduction. Using the updated L4T image for Orin the power consumption is reduced by fine tuning the CPU, GPU, and DLA frequencies per benchmark to achieve the optimum perf-per-watt. This image also enables new platform power saving features like regulator auto phase shedding and low-power states in low-load conditions. The flexibility of USB-C support in Orin was leveraged to consolidate all I/O through Ethernet-over-USB communication. System power was further reduced by disabling I/O subsystems like Ethernet, WiFi, and DP that are not essential for inference and also by using off-the-shelf higher efficiency GaN power adapters.
These platform and software optimizations reduced system power consumption by up to 52% and improved perf-per-watt by up to 48% over our previous submission in 2.0.
3D U-Net performance improvement
In MLPerf Inference v2.0, the 3D U-Net medical imaging workload switched to the KITS19 dataset, which increased image sizes by up to 8x and raised the amount of compute processing required for a given sample up to 18x due to the sliding window inference. For more information about the NVIDIA MLPerf Inference v2.0 submission, see Getting the Best Performance on MLPerf Inference 2.0.
For MLPerf Inference 2.1, we further improved the performance of the first convolution layer with the TensorRT IPluginV2DDynamicExt plugin.
KiTS19 images are single-channel tensors, and this challenges the performance of the very first 3D convolution in 3D U-Net. In 3D convolution, this channel dimension typically contributes to GEMM’s K dimension. This is specially relevant because the overall performance on 3D U-Net is dominated by the first two and last two 3D-Convolutions. In MLPerf Inference v2.0, these four convolutions contributed to roughly 38% of the entire network run-time; the very first layer responsible for 8%. A non-trivial factor that explains that is the need to use zero-padding to accommodate for the NC/32DHW32 vectorized format layout in where the tensor cores can be utilized most efficiently.
With our updated plugin, we use a INT8 Linear format to leverage efficient computation on this single-channel limited 3D shape input. The advantages of this are twofold:
- Higher effective use of flops: by not performing unneeded computations
- PCIe transfer B/W savings: avoids the overhead of either moving zero padded input tensor between host and GPU memory or zero-padding on GPU before sending the input tensor to TensorRT
This optimization improved the first layer performance by 2.7x. Additionally, the slicing kernel no longer needs to deal with zero-padding, and therefore its performance also improved by 2x. As a net result, 3D-UNet’s end-to-end performance improved by 5% in MLPerf Inference 2.1.
Breaking performance records across workloads
In MLPerf Inference 2.1, the first NVIDIA H100 submission set new per-accelerator performance records on all workloads in the data center scenario, and delivered up to 4.5x higher performance than the A100. This generational performance uplift was possible due to both the many breakthroughs of the NVIDIA Hopper Architecture as well as immense software optimizations that take advantage of those capabilities.
NVIDIA Jetson AGX Orin saw an up to 50% boost in energy efficiency in just one round and it continues to deliver overall inference performance leadership for edge AI and robotics applications.
This latest round of MLPerf Inference showcases the leading performance and versatility of the NVIDIA AI platform for the full breadth of AI workloads and scenarios. With the H100 Tensor Core GPU, we are supercharging the NVIDIA AI platform for the most advanced models and providing users with new levels of performance and capabilities for the most demanding workloads.
For more information, see NVIDIA Hopper Architecture In-Depth.
