
Inference is where we interact with AI. Chat bots, digital assistants, recommendation engines, fraud protection services, and other applications that you use every day—all are powered by AI. Those deployed applications use inference to get you the information that you need.
Given the wide array of usages for AI inference, evaluating performance poses numerous challenges for developers and infrastructure managers. Industry-standard benchmarks have long played a critical role in that evaluation process. For AI inference on data center, edge, and mobile platforms, MLPerf Inference 1.0 measures performance across computer vision, medical imaging, natural language, and recommender systems. These benchmarks were developed by a consortium of AI industry leaders. They provide the most comprehensive set of performance data available today, both for AI training and inference.
Version 1.0 of MLPerf Inference introduces some incremental but important new features. These include tests to measure power and energy efficiency and increasing test runtimes from 1 minute to 10 to better exercise the unit under test.
To perform well on the wide test array in this benchmark, it takes a full-stack platform with great ecosystem support, both for frameworks and networks. NVIDIA was the only company to make submissions for all data center and edge tests and deliver the best performance on all. One of the great byproducts of this work is that many of these optimizations found their way into inference developer tools like TensorRT and Triton.
In this post, we step through some of these optimizations, including the use of Triton Inference Server and the A100 Multi-Instance GPU (MIG) feature.
MLPerf 1.0 results
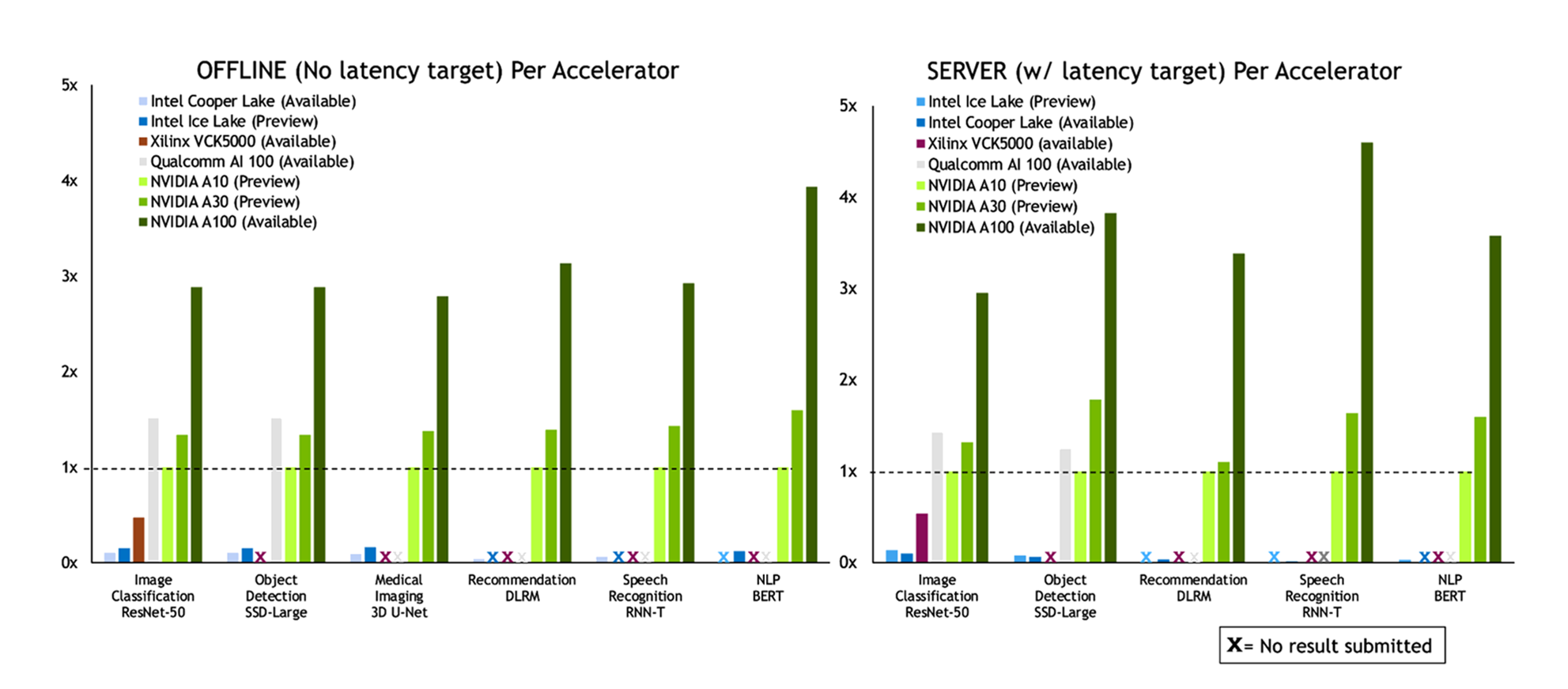
This round of MLPerf Inference saw the debut of two new GPUs from NVIDIA: A10 and A30. These mainstream GPUs join the flagship NVIDIA A100 GPU, and each has a particular role to play in the portfolio. A10 is designed for AI and visual computing and A30 is designed for AI and compute workloads. The following chart shows the Data Center scenario submissions:
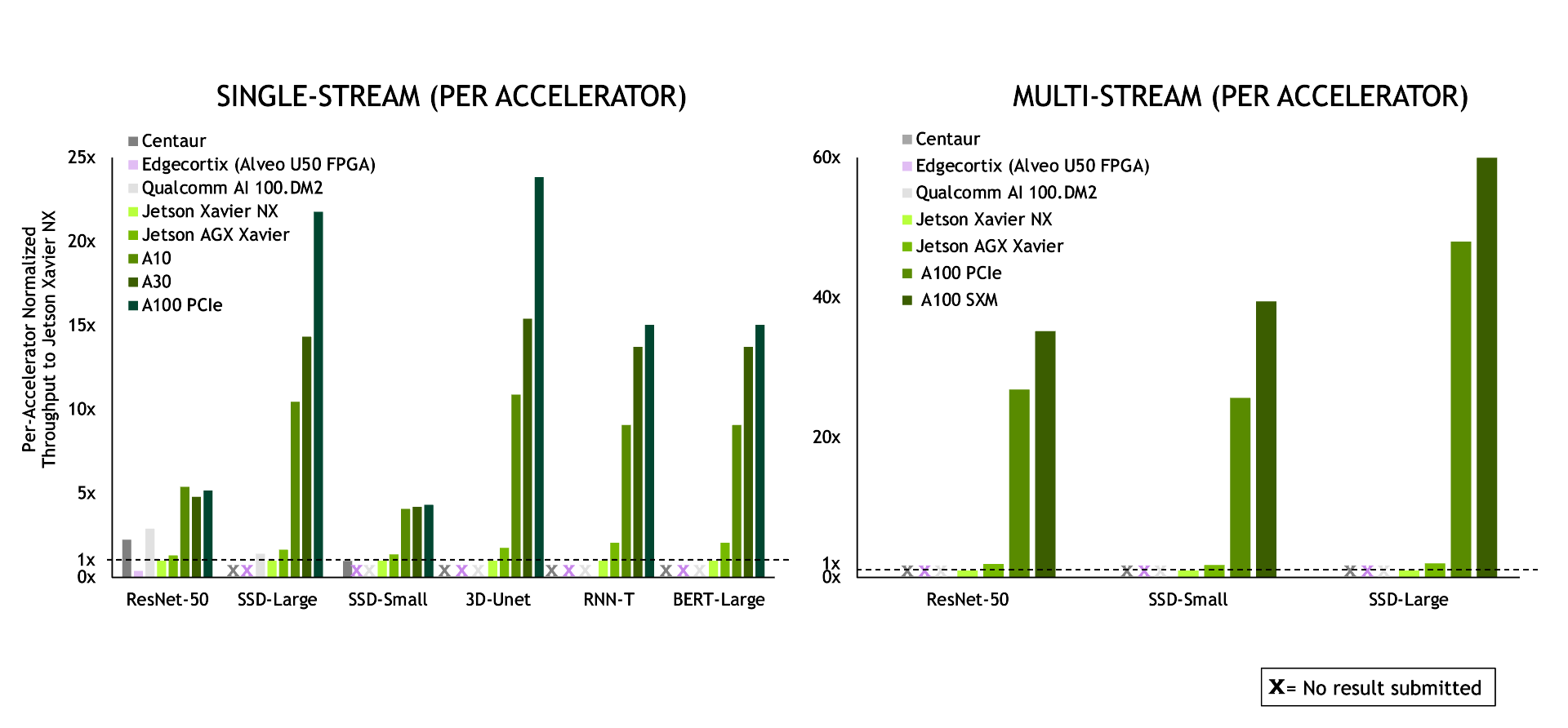
In the Edge scenario, NVIDIA again delivered leadership performance across the board.
Optimizations behind the results
AI training generally requires precisions like FP32, TF32, or mixed precision (FP16/FP32). However, inference can often use reduced precision to achieve better performance and lower latency while preserving required accuracy. Nearly all NVIDIA submissions used INT8 accuracy. In the case of the RNN-T speech-to-text model, we converted the encoder LSTM cell to INT8. Previously, in v0.7, we used FP16. We also made several other optimizations to make best use of the IMMA (INT8 using Tensor Cores) instructions across different workloads.
Layer fusion is another optimization technique where the math operations from multiple network layers are combined to reduce computational load to achieve the same or better result. We used layer fusion to improve performance on the 3D-UNet medical imaging workload, combining deconvolution and concatenation operations into a single kernel.
Triton
As with the previous round, we made many submissions using Triton Inference Server, which simplifies deployment of AI models at scale in production. This open-source inference serving software lets you deploy trained AI models from any framework on any GPU– or CPU-based infrastructure: cloud, data center, or edge. You can use a variety of possible inference backends, including TensorRT for NVIDIA GPU and OpenVINO for Intel CPU.
In this round, the team made several optimizations that are available from the triton-inference-server GitHub repo. These include a multithreaded gather kernel to prepare the input for inference as well as using pinned CPU memory for I/O buffers to speed data movement to the GPU. Using the Triton integrated auto-batching support, the Triton-based GPU submissions achieved an average of 95% of the performance of the server scenario submissions, using custom auto-batching code.
Another great Triton feature is that it can run CPU-based inference. To demonstrate those capabilities, we made several CPU-only submissions using Triton. On data center submissions in the offline and server scenarios, Triton’s CPU submissions achieved an average of 99% of the performance of the comparable CPU submission. You can use the same inference serving software to host both GPU– and CPU-based applications. When you transition applications from CPU to GPU, you can stay on the same software platform, with only a few changes to a config file to complete the change.
MIG goes big
For this round, the team made two novel submissions to demonstrate MIG performance and versatility. A key metric for infrastructure management is overall server utilization, which includes its accelerators. A typical target value is around 80%, which gets the most out of every server while allowing some headroom to handle compute demand spikes. A100 GPUs often have much more compute capacity than a single inference workload requires. Having the MIG feature to partition the GPU into right-sized instances allows you to host multiple networks on a single GPU.
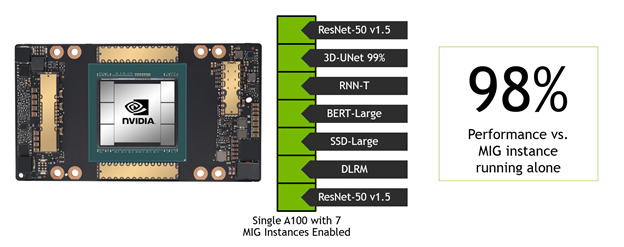
The team built a MIG submission where one network’s performance was measured in a single MIG instance. Simultaneously, the other MLPerf Data Center workloads were running in the other six MIG instances. In other words, a single A100 was running the entire Data Center benchmark suite at the same time. The team repeated this for all six Data Center networks. For the network being measured, the submission showed that, on average, the network under test achieved 98% of the performance of that single MIG instance if the other six instances were idle.
MLPerf Inference drives innovation
Many of the optimizations used to achieve the winning results are available today in TensorRT, Triton Inference Server, and the MLPerf Inference GitHub repo. This round of testing debuted two new GPUs: the NVIDIA A10 and A30. It further demonstrated the great capabilities of Triton and the MIG feature. These allow you to deploy trained networks on GPUs and CPUs easily. At the same time, you’re provisioning the right-sized amount of AI acceleration for a given application and maximizing the utility of every data center processor.
In addition to the direct submissions by NVIDIA, seven partners—including Alibaba, Dell EMC, Fujitsu, Gigabyte, HPE, Lenovo, Supermicro—also submitted using NVIDIA GPU-accelerated platforms, for over half of the total submissions. All software used for NVIDIA submissions is available from the MLPerf repo, NVIDIA GitHub repo, and NGC, the NVIDIA hub for GPU-optimized software for deep learning, machine learning, and high-performance computing.
These MLPerf Inference 1.0 results bring up to 46% more performance than the previous MLPerf 0.7 submission six months ago. They further reinforce the NVIDIA AI platform as not only the clear performance leader, but also the most versatile platform for running every kind of network: on-premises, in the cloud, or at the edge. As networks and data sets continue to grow rapidly and as real-time services continue to use AI, inference acceleration has become a must-have for applications to realize their full potential.
