
This post was originally published in August 2019 and has been updated for NVIDIA TensorRT 8.0.

Large-scale language models (LSLMs) such as BERT, GPT-2, and XL-Net have brought exciting leaps in accuracy for many natural language processing (NLP) tasks. Since its release in October 2018, BERT (Bidirectional Encoder Representations from Transformers), with all its many variants, remains one of the most popular language models and still delivers state-of-the-art accuracy.
BERT provided a leap in accuracy for NLP tasks that brought high-quality, language-based services within the reach of companies across many industries. To use the model in production, you must consider factors such as latency and accuracy, which influences end-user satisfaction with a service. BERT requires significant compute during inference due to its 12/24-layer stacked, multihead attention network. This has posed a challenge for companies to deploy BERT as part of real-time applications.
Today, NVIDIA is releasing version 8 of TensorRT, which brings the inference latency of BERT-Large down to 1.2 ms on NVIDIA A100 GPUs with new optimizations on transformer-based networks. New generalized optimizations in TensorRT can accelerate all such models, reducing inference time to half the time compared to TensorRT 7.
TensorRT
TensorRT is a platform for high-performance, deep learning inference, which includes an optimizer and runtime that minimizes latency and maximizes throughput in production. With TensorRT, you can optimize models trained in all major frameworks, calibrate for lower precision with high accuracy, and finally deploy in production.
All the code for achieving this performance with BERT is being released as open source in this NVIDIA/TensorRT GitHub repo. We have optimized the Transformer layer, which is a fundamental building block of the BERT encoder so that you can adapt these optimizations to any BERT-based NLP task. BERT is applied to an expanding set of speech and NLP applications beyond conversational AI, all of which can take advantage of these optimizations.
Question answering (QA) or reading comprehension is a popular way to test the ability of models to understand the context. The SQuAD leaderboard tracks the top performers for this task, for a dataset and test set that they provide. There has been rapid progress in QA ability in the last few years, with global contributions from academia and companies.
In this post, we demonstrate how to create a simple QA application using Python, powered by TensorRT-optimized BERT code that NVIDIA released today. The example provides an API to input passages and questions, and it returns responses generated by the BERT model.
Here’s a brief review of the steps to perform training and inference using TensorRT for BERT.
BERT training and inference pipeline
A major problem faced by NLP researchers and developers is scarcity of high-quality labeled training data for their specific NLP task. To overcome the problem of learning a model for the task from scratch, breakthroughs in NLP use the vast amounts of unlabeled text and break the NLP task into two parts:
- Learning to represent the meaning of words, the relationship between them, that is, building up a language model using auxiliary tasks and a large corpus of text
- Specializing the language model to the actual task by augmenting the language model with a relatively small, task-specific network that is trained in a supervised manner.
These two stages are typically referred to as pretraining and fine-tuning. This paradigm enables the use of the pretrained language model to a wide range of tasks without any task-specific change to the model architecture. In this example, BERT provides a high-quality language model that is fine-tuned for QA but suitable for other tasks such as sentence classification and sentiment analysis.
You can either start with the pretrained checkpoints available online or pretrain BERT on your own custom corpus (Figure 1). You can also initialize pretraining from a checkpoint and then continue training on custom data.
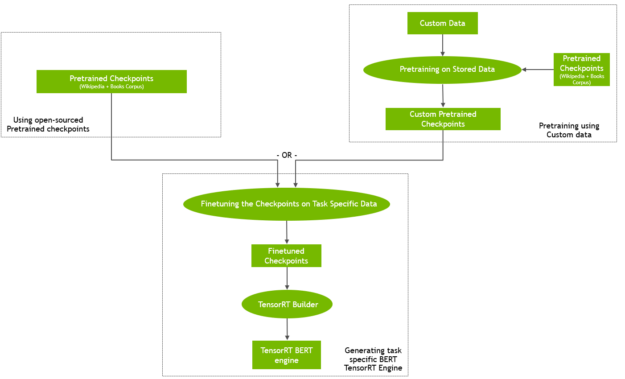
Pretraining with custom or domain-specific data may yield interesting results, for example BioBert. However, it is computationally intensive and requires a massively parallel compute infrastructure to complete within a reasonable amount of time. GPU-enabled, multinode training is an ideal solution for such scenarios. For more information about how NVIDIA developers were able to train BERT in less than an hour, see Training BERT with GPUs.
In the fine-tuning step, the task-specific network based on the pretrained BERT language model is trained using the task-specific training data. For QA, this is (paragraph, question, answer) triples. Compared to pretraining, fine-tuning is generally far less computationally demanding.
To perform inference using a QA neural network:
- Create a TensorRT engine by passing the fine-tuned weights and network definition to the TensorRT builder.
- Start the TensorRT runtime with this engine.
- Feed a passage and a question to the TensorRT runtime and receive as output the answer predicted by the network.
Figure 2 shows the entire workflow.

Run the sample!
Set up your environment to perform BERT inference with the following steps:
- Create a Docker image with the prerequisites.
- Build the TensorRT engine from the fine-tuned weights.
- Perform inference given a passage and query.
We use scripts to perform these steps, which you can find in the TensorRT BERT sample repo. While we describe several options that you can pass to each script, to get started quickly, you could also run the following code example:
# Clone the TensorRT repository and navigate to BERT demo directory git clone --recursive https://github.com/NVIDIA/TensorRT && cd TensorRT # Create and launch the Docker image # Here we assume the following: # - the os being ubuntu-18.04 (see below for other supported versions) # - cuda version is 11.3.1 bash docker/build.sh --file docker/ubuntu-18.04.Dockerfile --tag tensorrt-ubuntu18.04-cuda11.3 --cuda 11.3.1 # Run the Docker container just created bash docker/launch.sh --tag tensorrt-ubuntu18.04-cuda11.3 --gpus all # cd into the BERT demo folder cd $TRT_OSSPATH/demo/BERT # Download the BERT model fine-tuned checkpoint bash scripts/download_model.sh # Build the TensorRT runtime engine. # To build an engine, use the builder.py script. mkdir -p engines && python3 builder.py -m models/fine-tuned/bert_tf_ckpt_large_qa_squad2_amp_128_v19.03.1/model.ckpt -o engines/bert_large_128.engine -b 1 -s 128 --fp16 -c models/fine-tuned/bert_tf_ckpt_large_qa_squad2_amp_128_v19.03.1
This last command builds an engine with a maximum batch size of 1 (-b 1), and sequence length of 128 (-s 128) using mixed precision (--fp16) and the BERT Large SQuAD v2 FP16 Sequence Length 128 checkpoint (-c models/fine-tuned/bert_tf_ckpt_large_qa_squad2_amp_128_v19.03.1).
Now, give it a passage and see how much information it can decipher by asking a few questions.
python3 inference.py -e engines/bert_large_128.engine -p "TensorRT is a high performance deep learning inference platform that delivers low latency and high throughput for apps such as recommenders, speech and image/video on NVIDIA GPUs. It includes parsers to import models, and plugins to support novel ops and layers before applying optimizations for inference. Today NVIDIA is open-sourcing parsers and plugins in TensorRT so that the deep learning community can customize and extend these components to take advantage of powerful TensorRT optimizations for your apps." -q "What is TensorRT?" -v models/fine-tuned/bert_tf_ckpt_large_qa_squad2_amp_128_v19.03.1/vocab.txt
The result of this command should be something similar to the following:
Passage: TensorRT is a high performance deep learning inference platform that delivers low latency and high throughput for apps such as recommenders, speech and image/video on NVIDIA GPUs. It includes parsers to import models, and plugins to support novel ops and layers before applying optimizations for inference. Today NVIDIA is open-sourcing parsers and plugins in TensorRT so that the deep learning community can customize and extend these components to take advantage of powerful TensorRT optimizations for your apps.
Question: What is TensorRT? Answer: 'a high performance deep learning inference platform'
Given the same passage with a different question, you should get the following result:
Question: What is included in TensorRT? Answer: 'parsers to import models, and plugins to support novel ops and layers before applying optimizations for inference'
The answers provided by the model are accurate based on the text of the passage that was provided. The sample uses FP16 precision for performing inference with TensorRT. This helps achieve the highest performance possible on Tensor Cores in NVIDIA GPUs. In our tests, we measured the accuracy of TensorRT to be comparable to in-framework inference with FP16 precision.
Script options
Here are the options available with the scripts. The docker/build.sh script builds the docker image using the Dockerfile supplied in the docker folder. It installs all necessary packages, depending on the OS you are selecting as Dockerfile. For this post, we used ubuntu-18.04 but dockerfiles for ubuntu-16.04 and ubuntu-20.04 are also provided.
Run the script as follows:
bash docker/build.sh --file docker/ubuntu-xx.04.Dockerfile --tag tensorrt-tag --cuda cuda_versionAfter creating and running the environment, download fine-tuned weights for BERT. Note that you do not need the pretrained weights to create the TensorRT engine (just the fine-tuned weights). Along with the fine-tuned weights, use the associated configuration file, which specifies parameters such as number of attention heads, number of layers, and the vocab.txt file, which contains the learned vocabulary from the training process. These are packaged with the fine-tuned model downloaded from NGC; download them using the download_model.sh script. As part of this script, you can specify the set of fine-tuned weights for the BERT model to download. The command-line parameters control the exact BERT model to be used later for model building and inference:
sh download_model.sh [tf|pyt] [base|large|megatron-large] [128|384] [v2|v1_1] [sparse] [int8-qat] tf | pyt tensorflow or pytorch version base | large | megatron-large - determine whether to download a BERT-base or BERT-large or megatron model to optimize 128 | 384 - determine whether to download a BERT model for sequence length 128 or 384 v2 | v1_1, fine-tuned on squad2 or squad1.1 sparse, download sparse version int8-qat, download int8 weights
Examples:
# Running with default parametersbash download_model.sh# Running with custom parameters (BERT-large, FP32 fine-tuned weights, 128 sequence length)sh download_model.sh large tf fp32 128
This script by default downloads fine-tuned TensorFlow BERT-large, with FP16 precision and a sequence length of 128. In addition to the fine-tuned model, you use the configuration file, enumerating model parameters and the vocabulary file used to convert BERT model output to a textual answer.
Next, you can build the TensorRT engine and use it for a QA example, that is, inference. The script builder.py builds the TensorRT engine for inference based on the downloaded BERT fine-tuned model.
Make sure that the sequence length provided to the following script matches the sequence length of the model that was downloaded.
python3 builder.py [-h] [-m CKPT] [-x ONNX] [-pt PYTORCH] -o OUTPUT [-b BATCH_SIZE] [-s SEQUENCE_LENGTH] -c CONFIG_DIR [-f] [-i] [-t] [-w WORKSPACE_SIZE] [-j SQUAD_JSON] [-v VOCAB_FILE] [-n CALIB_NUM] [-p CALIB_PATH] [-g] [-iln] [-imh] [-sp] [-tcf TIMING_CACHE_FILE]
Here are the optional arguments:
-h, --help show this help message and exit -m CKPT, --ckpt CKPT The checkpoint file basename, e.g.: basename(model.ckpt-766908.data-00000-of-00001) is model.ckpt-766908 (default: None) -x ONNX, --onnx ONNX The ONNX model file path. (default: None) -pt PYTORCH, --pytorch PYTORCH The PyTorch checkpoint file path. (default: None) -o OUTPUT, --output OUTPUT The bert engine file, ex bert.engine (default: bert_base_384.engine) -b BATCH_SIZE, --batch-size BATCH_SIZE Batch size(s) to optimize for. The engine will be usable with any batch size below this, but may not be optimal for smaller sizes. Can be specified multiple times to optimize for more than one batch size.(default: []) -s SEQUENCE_LENGTH, --sequence-length SEQUENCE_LENGTH Sequence length of the BERT model (default: []) -c CONFIG_DIR, --config-dir CONFIG_DIR The folder containing the bert_config.json, which can be downloaded e.g. from https://github.com/google-research/bert#pre-trained-models (default: None) -f, --fp16 Indicates that inference should be run in FP16 precision (default: False) -i, --int8 Indicates that inference should be run in INT8 precision (default: False) -t, --strict Indicates that inference should be run in strict precision mode (default: False) -w WORKSPACE_SIZE, --workspace-size WORKSPACE_SIZE Workspace size in MiB for building the BERT engine (default: 1000) -j SQUAD_JSON, --squad-json SQUAD_JSON squad json dataset used for int8 calibration (default: squad/dev-v1.1.json) -v VOCAB_FILE, --vocab-file VOCAB_FILE Path to file containing entire understandable vocab (default: ./pre-trained_model/uncased_L-24_H-1024_A-16/vocab.txt) -n CALIB_NUM, --calib-num CALIB_NUM calibration batch numbers (default: 100) -p CALIB_PATH, --calib-path CALIB_PATH calibration cache path (default: None) -g, --force-fc2-gemm Force use gemm to implement FC2 layer (default: False) -iln, --force-int8-skipln Run skip layernorm with INT8 (FP32 or FP16 by default) inputs and output (default: False) -imh, --force-int8-multihead Run multi-head attention with INT8 (FP32 or FP16 by default) input and output (default: False) -sp, --sparse Indicates that model is sparse (default: False) -tcf TIMING_CACHE_FILE, --timing-cache-file TIMING_CACHE_FILE Path to tensorrt build timeing cache file, only available for tensorrt 8.0 and later (default: None)
Example:
python3 builder.py -m models/fine-tuned/bert_tf_ckpt_large_qa_squad2_amp_128_v19.03.1/model.ckpt -o engines/bert_large_128.engine -b 1 -s 128 --fp16 -c models/fine-tuned/bert_tf_ckpt_large_qa_squad2_amp_128_v19.03.1
You should now have a TensorRT engine, engines/bert_large_128.engine, to use in the inference.py script for QA.
Later in this post, we describe the process to build the TensorRT engine. You can now provide a passage and a query to inference.py and see if the model is able to answer your queries correctly.
There are few ways to interact with the inference script:
- The passage and question can be provided as command-line arguments using the –passage and –question flags.
- They can be passed in from a given file using the –passage_file and –question_file flags.
- If neither of these flags are given during execution, you are prompted to enter the passage and question after the execution has begun.
Here are the parameters for the inference.py script:
Usage: inference.py [-h] [-e ENGINE] [-b BATCH_SIZE] [-p [PASSAGE [PASSAGE ...]]] [-pf PASSAGE_FILE] [-q [QUESTION [QUESTION ...]]] [-qf QUESTION_FILE] [-sq SQUAD_JSON] [-o OUTPUT_PREDICTION_FILE] [-v VOCAB_FILE] [-s SEQUENCE_LENGTH] [--max-query-length MAX_QUERY_LENGTH] [--max-answer-length MAX_ANSWER_LENGTH] [--n-best-size N_BEST_SIZE] [--doc-stride DOC_STRIDE]
This script uses a prebuilt TensorRT BERT QA engine to answer a question based on the provided passage.
Here are the optional arguments:
-h, --help show this help message and exit -e ENGINE, --engine ENGINE Path to BERT TensorRT engine -b BATCH_SIZE, --batch-size BATCH_SIZE Batch size for inference. -p [PASSAGE [PASSAGE ...]], --passage [PASSAGE [PASSAGE ...]] Text for paragraph/passage for BERT QA -pf PASSAGE_FILE, --passage-file PASSAGE_FILE File containing input passage -q [QUESTION [QUESTION ...]], --question [QUESTION [QUESTION ...]] Text for query/question for BERT QA -qf QUESTION_FILE, --question-file QUESTION_FILE File containing input question -sq SQUAD_JSON, --squad-json SQUAD_JSON SQuAD json file -o OUTPUT_PREDICTION_FILE, --output-prediction-file OUTPUT_PREDICTION_FILE Output prediction file for SQuAD evaluation -v VOCAB_FILE, --vocab-file VOCAB_FILE Path to file containing entire understandable vocab -s SEQUENCE_LENGTH, --sequence-length SEQUENCE_LENGTH The sequence length to use. Defaults to 128 --max-query-length MAX_QUERY_LENGTH The maximum length of a query in number of tokens. Queries longer than this will be truncated --max-answer-length MAX_ANSWER_LENGTH The maximum length of an answer that can be generated --n-best-size N_BEST_SIZE Total number of n-best predictions to generate in the nbest_predictions.json output file --doc-stride DOC_STRIDE When splitting up a long document into chunks, what stride to take between chunks
BERT inference with TensorRT
For a step-by-step description and walkthrough of the inference process, see the Python script inference.py and the detailed Jupyter notebook inference.ipynb in the sample folder. Here are a few key parameters and concepts for performing inference with TensorRT.
BERT, or more specifically, the encoder layer, uses the following parameters to govern its operation:
- Batch size
- Sequence Length
- Number of attention heads
The value of these parameters, which depend on the BERT model chosen, are used to set the configuration parameters for the TensorRT plan file (execution engine).
For each encoder, also specify the number of hidden layers and the attention head size. You can also read all the earlier parameters from the TensorFlow checkpoint file.
As the BERT model we are using has been fine-tuned for a downstream task of QA on the SQuAD dataset, the output for the network (that is, the output fully connected layer) is a span of text where the answer appears in the passage, referred to as h_output in the sample. After you generate the TensorRT engine, you can serialize it and use it later with TensorRT runtime.
During inference, you perform memory copies from CPU to GPU and the reverse asynchronously to get tensors into and out of the GPU memory, respectively. Asynchronous memory copy operation hides the latency of memory transfer by overlapping computations with memory copy operation between device and host. Figure 3 shows the asynchronous memory copies and kernel execution.
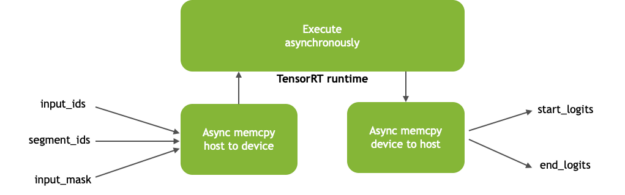
The inputs to the BERT model (Figure 3) include the following:
input_ids: tensor with token ids of paragraph concatenated along with question that is used as input for inferencesegment_ids: distinguishes between passage and questioninput_mask: indicates which elements in the sequence are tokens, and which ones are padding elements
The outputs (start_logits and end_logits) represent the span of the answer, which the network predicts inside the passage based on the question.
Benchmarking BERT inference performance
BERT can be applied both for online and offline use cases. Online NLP applications, such as conversational AI, place tight latency budgets during inference. Several models need to execute in a sequence in response to a single user query. When used as a service, the total time a customer experiences includes compute time as well as input and output network latency. Longer times lead to a sluggish performance and a poor customer experience.
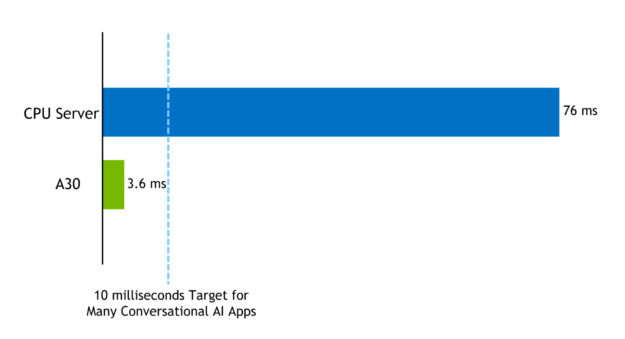
While the exact latency available for a single model can vary by application, several real-time applications need the language model to execute in under 10 ms.
Using an NVIDIA Ampere Architecture A100 GPU, BERT-Large optimized with TensorRT 8 can perform inference in 1.2ms for a QA task similar to that available in SQuAD with batch size = 1 and sequence length = 128.
Using the TensorRT optimized sample, you can execute different batch sizes for BERT-base or BERT-large within the 10 ms latency budget. For example, the latency for inference on a BERT-Large model with sequence length = 384 batch size = 1 on A30 with TensorRT8 was 3.62ms. The same model, sequence length =384 with highly optimized code on a CPU-only platform (**) for batch size = 1 was 76ms.
The performance measures the compute-only latency time for executing the network on a QA task between passing tensors as input and gathering logits as output. You can find the code used to benchmark the sample in the script scripts/inference_benchmark.sh in the repo.
Summary
NVIDIA is releasing TensorRT 8.0, which makes it possible to perform BERT inference in 0.74ms on A30 GPUs. The code for benchmarking inference on BERT is available as a sample in the TensorRT open-source repo.
This post gives an overview of how to use the TensorRT sample and performance results. We further describe a workflow of how to use the BERT sample as part of a simple application and Jupyter notebook where you can pass a paragraph and ask questions related to it. The new optimizations and performance achievable makes it practical to use BERT in production for applications with tight latency budgets, such as conversational AI.
We are always looking for new ideas for new examples and applications to share. What NLP applications do you use BERT for and what examples would you like to see from us in the future?
If you have questions regarding the TensorRT sample repo, check the NVIDIA TensorRT Developer Forum to see if other members of the TensorRT community have a resolution first. NVIDIA Registered Developer Program members can also file bugs at https://developer.nvidia.com/nvidia-developer-program.
(*)
- CPU-only specifications: Gold 6240@2.60GHz 3.9GHz Turbo (Cascade Lake) HT Off, Single node, Single Socket, Number of CPU Threads = 18, Data=Real, Batch Size=1; Sequence Length=128; nireq=1; Precision=FP32; Data=Real; OpenVINO 2019 R2
- GPU-server specification: Gold 6140@2GHz 3.7GHz Turbo (Skylake) HT On, Single node, Dual Socket, Number of CPU Threads = 72, T4 16GB, Driver Version 418.67 (r418_00), BERT-base, Batch Size=1; Number of heads = 12, Size per head = 64; 12 layers; Sequence Length=128; Precision=FP16; XLA=Yes; Data=Real; TensorRT 5.1
(**)
- CPU-only specifications: Platinum 8380H@2.90GHz to 4.3 GHz Turbo (Cooper Lake) HT Off, Single node, Single Socket, Number of CPU Threads = 28, BERT-Large, Data=Real, Batch Size=1; Sequence Length=384; nireq=1; Precision=INT8; Data=Real; OpenVINO 2021 R3
- GPU-server specification: AMD EPYC 7742@2.25GHz 3.4GHz Turbo (Rome) HT Off, Single node, Number of CPU Threads = 64, A30(GA100) 1*24258 MiB 1*56 SM, Driver Version 470.29 (r470_00), BERT-Large, Batch Size=1; Sequence Length=384; Precision=INT8; TensorRT 8.0
