
The NVIDIA AI Red Team is focused on scaling secure development practices across the data, science, and AI ecosystems. We participate in open-source security initiatives, release tools, present at industry conferences, host educational competitions, and provide innovative training.
Covering 3 years and totaling almost 140GB of source code, the recently released Meta Kaggle for Code dataset is a great opportunity to analyze the security of machine learning (ML) research and experimentation competition code at scale. Our goal was to use this data to answer the following questions:
- What is the state of security hygiene in ML research code?
- How can security organizations improve the secure coding practices of ML researchers?
Our analysis shows that ML researchers continue to use insecure coding practices despite public documentation about security risks and relatively frictionless and advanced security tooling. We theorize that researchers prioritize rapid experimentation and do not think of themselves or their projects as targets because they are usually not running production services.
Additionally, the Kaggle environment may exacerbate security negligence based on isolation from researchers’ “real infrastructure.” However, researchers must acknowledge their position in the software supply chain and should be aware of risks to their research and systems from insecure coding practices.
Although originally proposed in the 2015 research paper Explaining and Harnessing Adversarial Examples, we also found little evidence of adoption of adversarial training or assessment in ML research pipelines. This may be partly due to the structure of Kaggle competitions and scoring metrics, but it is consistent with our other research and observations. However, with recent advances in multimodal models and demonstrated image-based prompt injection attacks, researchers should prioritize testing their models under adversarial conditions and perturbations.
Observations
The most significant observations were the use of plaintext credentials, insecure deserialization (primarily pickle), a lack of adversarial robustness and evaluation techniques, and typos. Focus defensive controls and education around these topics.
Plaintext credentials
Researchers still use long-lived, plaintext credentials and commit them to source control. We found over 140 unique active, plaintext credentials to third-party services like OpenAI, AWS, GitHub, and others. For some credential types, the credentials can be associated with other user data such as emails, exposing the user to phishing and other attacks.
In keeping with standard industry practices around Coordinated Vulnerability Disclosure, we reported this credential exposure to Kaggle on August 24, 2023. They have taken steps to mitigate this risk.
Insecure deserialization
The most prevalent risk is insecure deserialization. Furthermore, many notebooks included path traversal iteration that increased the likelihood of a malicious payload being executed.
For example, a user iterated through feature_dir and fileName to repeatedly execute the following command: feature = np.load(feature_dir + fileName + '.npy', allow_pickle=True).
The majority of the XML Injection findings were generated from pandas read html calls that can be vulnerable to XML external entity attacks and most of the mishandled sensitive information findings were related to http usage instead of https.
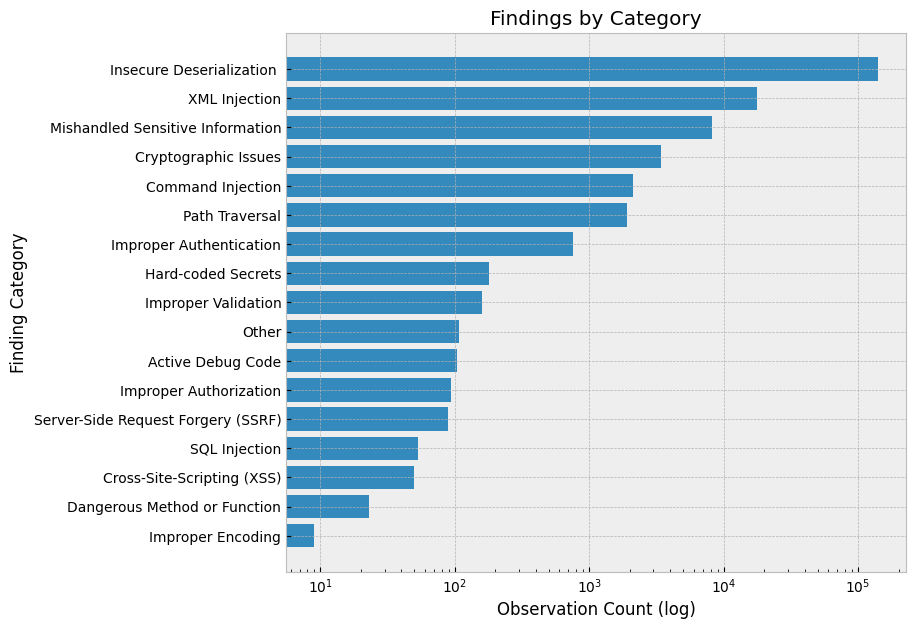
Pickle is still the standard
The de facto serialization format for researchers is still the pickle module. It was among the top 50 most imported modules with almost 5,000 imports. ONNX, a more secure serialization format for ML models, was directly imported just nine times. The pickle module may also have been used indirectly through built-in serialization formats in other libraries.
For instance, many NumPy or PyTorch serialization calls rely on built-in save methods that are still pickle-based. For example, we identified over 45,000 examples where pickle files were loaded as part of pandas, joblib, and NumPy deserialization.
Lack of adversarial retraining or testing
There is no evidence of adversarial retraining or testing. Common adversarial retraining and testing libraries like Adversarial RobustnessToolbox (ART), Counterfit, TextAttack, and CleverHans do not appear in any of the imports. For common explainability tools, there were no imports for Alibi, but Fairlearn was imported 34 times.
Other training techniques to protect privacy, such as federated learning and differential privacy, were almost entirely absent too (with the exception of PyDP, which was imported once).
Typos
We observed typos such as imports for panda and mathplotlib (which should have been pandas and matplotlib, respectively), among others. Typosquatting on PyPI is a notorious mechanism for spreading malware. For more details, see A PyPI Typosquatting Campaign Post-Mortem.
A few positives
We did not identify any instances where researchers loaded serialized objects or models from sources that would be easy to hijack or modify in transit. Additionally, no URLs found in the dataset were associated with malware or social engineering according to the Google Safe Browsing Lookup API.
Recommendations
Particularly with research, security controls must be layered and calibrated to minimally impact velocity. Understand what controls are necessary to protect the researcher, research, and network, and what additional controls may be necessary to transition successful research to production. Our recommendations, listed below, are based on the preceding observations.
Develop alternatives to entering long-lived credentials in source code
Alternatives include using a secrets manager, environment variables, input prompts, and credential vending services that provide short-lived tokens. Multifactor authentication (MFA) also reduces the impact of credentials leaked in source code.
Experience shows repeatedly that if developers start using credentials in source code, the chance of a leak significantly increases. Leaks can happen in datasets like this, accidental commits into version control, or exposure through history and logging as illustrated by our demonstration at JupyterCon 2023.
Use automation to catch mistakes before they are committed to remote resources
Version control systems like GitHub and continuous deployment systems like Jenkins have often been “crown jewels” for attackers. Use precommit hooks to run security automation and prevent local mistakes from being broadcast to these targets.
Establish guidelines, standards, and toolings to limit deserialization exploitation risks
The security risks of pickle are well documented, but still do require a malicious actor to have sufficient access and privileges to execute an attack. Our team recommends that organizations move towards more robust serialization formats like ONNX and protocol buffers. If your tool or organization must support pickle, implement integrity verification steps that can be validated without deserialization.
Identify and mitigate potential adversarial ML attacks
Vulnerabilities and exploits during research and development can impact the security and effectiveness of the resulting service. Understand the various attacks against ML systems to build appropriate threat models and defensive controls. To learn more, see NVIDIA AI Red Team: An Introduction.
For instance, including adversarial retraining during training time can ensure your classifier is more robust to adversarial evasion attacks. Consider adding an adversarial robustness metric to your evaluation framework when comparing model performance. If you are sponsoring a Kaggle competition, consider adding adversarial examples to the evaluation dataset so you are rewarding the most robust solution.
Consider the lifespan and isolation of your development environments
All analyzed user code ran on the Kaggle platform’s ephemeral environments, isolated from developer host machines. However, your organization may not have the same level of tenant isolation. It is important to not unnecessarily hinder the velocity of researchers, but consider the potential impact and blast-radius of a simple mistake (such as a misspelled import statement) and work to ensure domain resource isolation and network segmentation where possible.
Use allow/block lists and internal artifact repositories for artifacts like imports and datasets
Acknowledging the potential impact to research velocity, consider maintaining internal repositories of “known good” libraries and datasets or implement an import hooking scheme to reduce the risk of malicious package installs and imports. Similar hygiene for datasets improves security, reproducibility, and auditability.
Methodology
The dataset contains about 140GB of R, Python, and Jupyter Notebook source code publicly hosted on Kaggle. Kaggle allows users to save versions, so many of these artifacts are simply updates and changes to other files. Our analysis is limited to the Python files and Jupyter Notebooks—around 3.5 million files that were executed on Kaggle from April 2020 to August 2023.
Some analysis was manual, but we also relied heavily on two existing open-source security tools, TruffleHog to identify credentials and Semgrep to perform static analysis. Use these tools to repeat our analysis and consider them for inclusion in your kit of security tools.
To identify and validate credentials, TruffleHog can be run in a Docker container against source code repositories or local files. For this analysis, we ran TruffleHog against a local download with docker run --rm -it -v "kaggle:/pwd" trufflesecurity/trufflehog:latest filesystem /pwd --json --only-verified > trufflehog_findings.json.
TruffleHog also supports precommit hooks to help ensure credentials are not committed to remote repositories and CI/CD integration to continually monitor for leakage. TruffleHog was able to run against the Kaggle dataset without modification and we deduplicated findings based on unique secret values.
Semgrep is a static code analyzer that uses rules to identify potential weaknesses in the target source code. Since Semgrep does not natively support Jupyter notebooks, we used nbconvert to convert them to Python files before Semgrep processing. We used 162 rules from the default Python rules and rules maintained by Trail of Bits that are more focused on ML applications.
After installing Semgrep, run these two rulesets against your local Kaggle download with semgrep --config "p/trailofbits" --config "p/python" --json kaggle/ -o semgrep_findings.json. During analysis, we filtered out the Trail of Bits automatic memory pinning rule because we could not find a direct path or evidence of previous exploitation.
The NVIDIA AI Red Team wrapped these tools in a meta-tool called lintML. To reproduce our results, try it with lintML –semgrep-options “--config ‘p/python’ –config ‘p/trailofbits’” <directory>.
Limitations
While we are proud of the volume of this analysis, it is still “single source” in that all samples were collected through Kaggle. It is likely that, while many findings may be the same, the underlying distribution of security observations from other data sources would be different.
For example, a similar analysis performed on GitHub artifacts may skew towards “more secure” as those repositories are more likely to contain productionized code.
Furthermore, Kaggle competitions reward rapid iteration and accuracy, which potentially lead to different library imports, techniques, and security considerations that productionized research. For instance, Kaggle competitions usually provide the necessary data. In reality, sourcing, cleaning, and labeling data are often significant design decisions and sources of potential vulnerabilities.
This analysis was simultaneously enabled and limited by the tools we used. If a credential or validator did not exist in TruffleHog, there is no associated finding here. Likewise, Semgrep analysis was limited by the rulesets we chose. Only a subset of these findings are likely exploitable, but the quantity may be correlated with overall project risk.
Further, the finding quantity analysis may have been biased by the distribution of rules (more deserialization rules yielding more findings). Security researchers should continue contributing to established tools for findings related to machine learning security (as the NVIDIA AI Red Team has done for both TruffleHog and Semgrep rules). The NVIDIA AI Red Team is particularly interested in applications of data flow and taint analysis to machine learning applications.
Conclusion
Kaggle is a place for experimentation, research, and competition. It rewards rapid experiment iteration and performance, so these code artifacts are not representative of production services.
Or are they? Code is often reused, habits are formed during research, and defaults are sticky. In a similar analysis of over 300 highly ranked machine learning repositories on GitHub, we still found hardcoded credentials to third-party services and the full range of findings presented here. Increasing security awareness and informative and preventative controls during research helps ensure secure products and increases the professionalism and security posture of your enterprise.
Security professionals should use this analysis as a foundation for analyzing research and development practices in their organizations. Most of these findings represent baseline security controls. If you start to find them in your organization’s research code, they are signals to engage more thoroughly with research and development teams.
Use similar techniques to evaluate artifacts across your machine learning development cycle to ensure relaxed research practices are not propagating risk into production products. Identify opportunities to provide low-friction tooling early, not just in production delivery pipelines. Leverage proactive adversarial assessments and exercises to increase education, awareness, and reasonable security controls.
Researchers should focus on establishing and maintaining good security hygiene as part of scientific integrity. Security risks should be viewed as unwanted variables that should be mitigated to ensure the veracity of the experiments. Think about the provenance of data and code that you are pulling into your organization. Engage with your security teams for guidance on best-practices and environment hardening.
Just as you would when rigorously testing a hypothesis, be critical when testing your project and identify opportunities where accuracy may not be the sole metric you want to optimize and consider including robustness, explainability, and fairness tests. Even if you aren’t writing a production service, you may still be exposing yourself, your research, and your organization to potential risk.
Use our Security Practices notebook to begin analyzing this data yourself, or download a local copy of the Meta Kaggle Code to evaluate with TruffleHog and Semgrep. Experiment with lintML to identify risks in your ML training code.
To learn more about ML security, check out Black Hat Machine Learning at Black Hat Europe 2023.
Acknowledgments
We would like to thank Kaggle for making this dataset available. This kind of data can help elevate security awareness and baseline the industry. The NVIDIA AI Red Team is constantly trying to meet ML practitioners where they are, and Kaggle has been a great partner and enabler for that mission. For more details, see Improving Machine Learning Security Skills at a DEF CON Competition. We would also like to thank all of the Kaggle competitors for contributing code to the dataset.
Additionally, we would like to thank TruffleHog, Semgrep, and Trail of Bits for open sourcing security tools that enabled this research and Jupyter, pandas, NumPy, and Matplotlib for high-quality data analysis and visualization tools.
