Posts by BoYang Hsueh

Agentic AI / Generative AI
Jun 07, 2024
Seamlessly Deploying a Swarm of LoRA Adapters with NVIDIA NIM
The latest state-of-the-art foundation large language models (LLMs) have billions of parameters and are pretrained on trillions of tokens of input text. They...
11 MIN READ

Simulation / Modeling / Design
Sep 08, 2022
Full-Stack Innovation Fuels Highest MLPerf Inference 2.1 Results for NVIDIA
Today’s AI-powered applications are enabling richer experiences, fueled by both larger and more complex AI models as well as the application of many models in...
14 MIN READ
Data Science
Aug 03, 2022
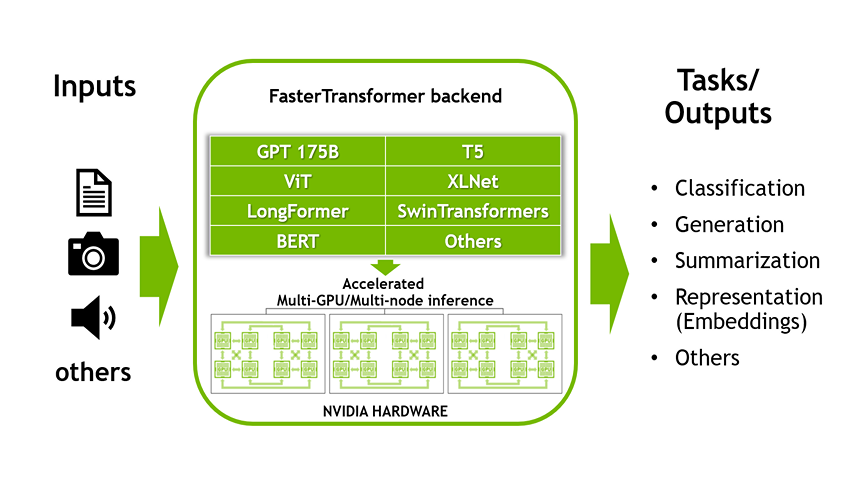
Accelerated Inference for Large Transformer Models Using NVIDIA Triton Inference Server
This is the first part of a two-part series discussing the NVIDIA Triton Inference Server’s FasterTransformer (FT) library, one of the fastest libraries for...
10 MIN READ
Data Science
Aug 03, 2022
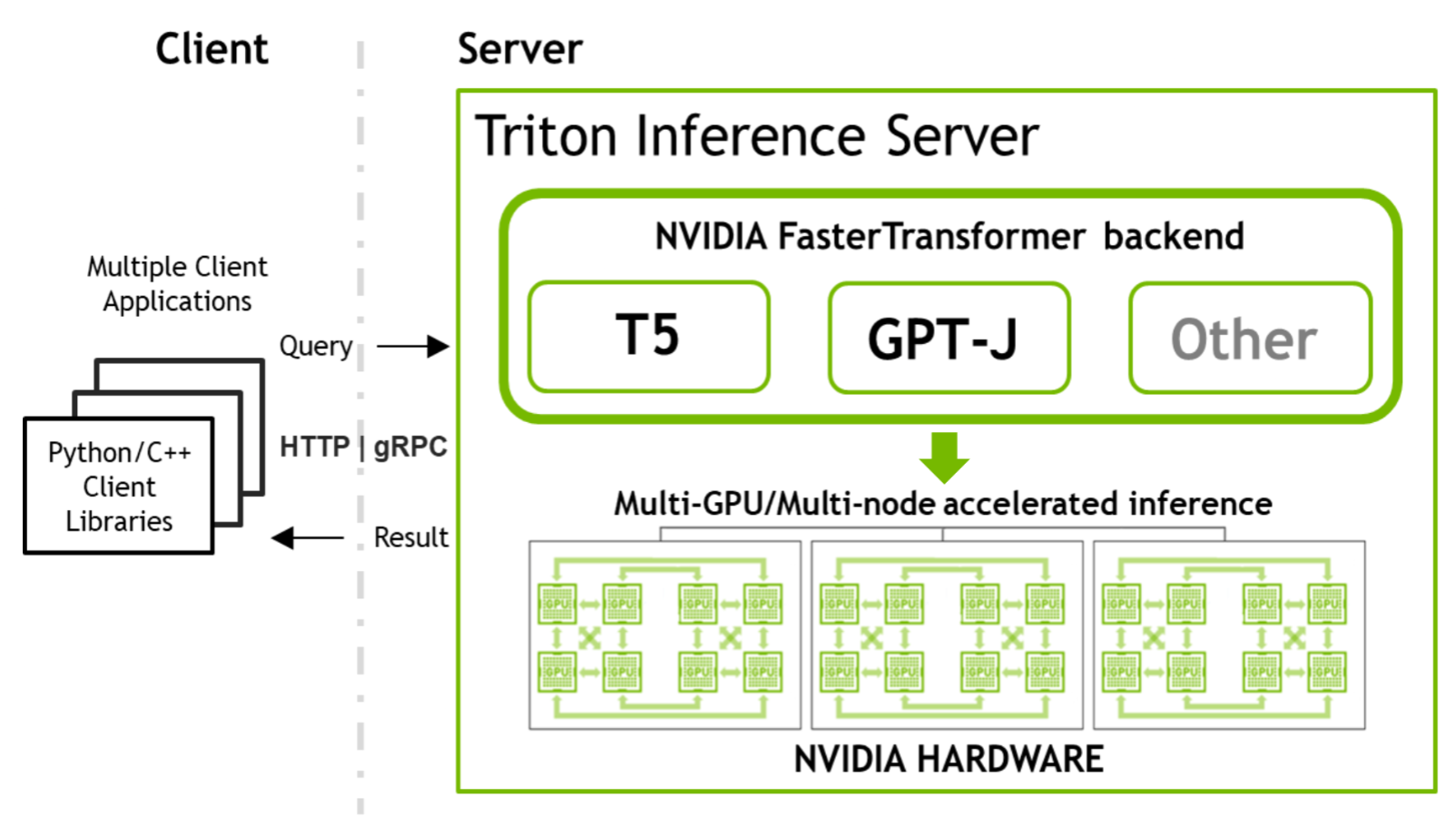
Deploying GPT-J and T5 with NVIDIA Triton Inference Server
This is the second part of a two-part series about NVIDIA tools that allow you to run large transformer models for accelerated inference. For an introduction to...
16 MIN READ