
The most exciting computing applications currently rely on training and running inference on complex AI models, often in demanding, real-time deployment scenarios. High-performance, accelerated AI platforms are needed to meet the demands of these applications and deliver the best user experiences.
New AI models are constantly being invented to enable new capabilities, and AI-powered applications often rely on many such models working in tandem. This means that an AI platform must be able to run the widest range of workloads and deliver excellent performance on all of them. MLPerf Inference—now in its seventh edition with v3.0—is a trusted, peer-reviewed suite of standardized inference performance tests that represents many such AI models.
AI applications run everywhere, from the largest hyperscale data centers to compact edge devices. MLPerf Inference represents both data center and edge environments. It also represents a range of real-world scenarios, such as offline (batch) processing, and latency-constrained server, single-stream, and multi-stream scenarios. This balance of workload breadth and depth ensures that MLPerf Inference is a valuable resource for those looking to select AI infrastructure to best meet the needs of a diverse set of deployments.
In the MLPerf Inference v3.0 round, NVIDIA submitted results on several products, including NVIDIA H100 Tensor Core GPUs (both SXM and PCIe add-in-card form factors) based on the NVIDIA Hopper architecture, the recently announced NVIDIA L4 Tensor Core GPU powered by the NVIDIA Ada Lovelace GPU architecture, as well as the NVIDIA Jetson AGX Orin and NVIDIA Jetson Orin NX AI computers for edge AI and robotics applications.
The NVIDIA AI platform (the core of the NVIDIA MLPerf submissions) is constantly enhanced with software innovations that increase performance and features, and leverage the capabilities of the latest NVIDIA products and architectures. TensorRT 8.6.0, the latest version of the NVIDIA high-performance deep learning inference SDK, is included on NVIDIA GPU Cloud. To access the containers, visit NVIDIA MLPerf Inference.
In the latest NVIDIA MLPerf Inference submission, many software enhancements were added, including support and optimizations to leverage the NVIDIA Ada Lovelace architecture that powers the NVIDIA L4 Tensor Core GPU, support for NVIDIA Jetson Orin NX, new kernels, and significant work to enable the NVIDIA network division submission.
The NVIDIA platform delivered record-breaking performance, energy efficiency, and versatility across its submissions. These achievements required delivering innovation at every layer of the NVIDIA full stack platform, from chips and systems to the network and inference software. This post details some of the software optimizations behind these results.
NVIDIA Hopper GPU delivers another giant leap
In this round, NVIDIA submitted results in the available category using the NVIDIA DGX H100 system, now in full production. DGX H100 delivered leadership per-accelerator performance, powered by the NVIDIA H100 Tensor Core GPU, boosting performance by up to 54% compared to the NVIDIA MLPerf Inference v2.1 H100 submission from just 6 months ago, which already delivered a significant performance leap compared to the NVIDIA A100 Tensor Core GPU. These results were fueled by the improvements detailed later in this post. (Note that per-accelerator performance is not a primary metric of MLPerf.)
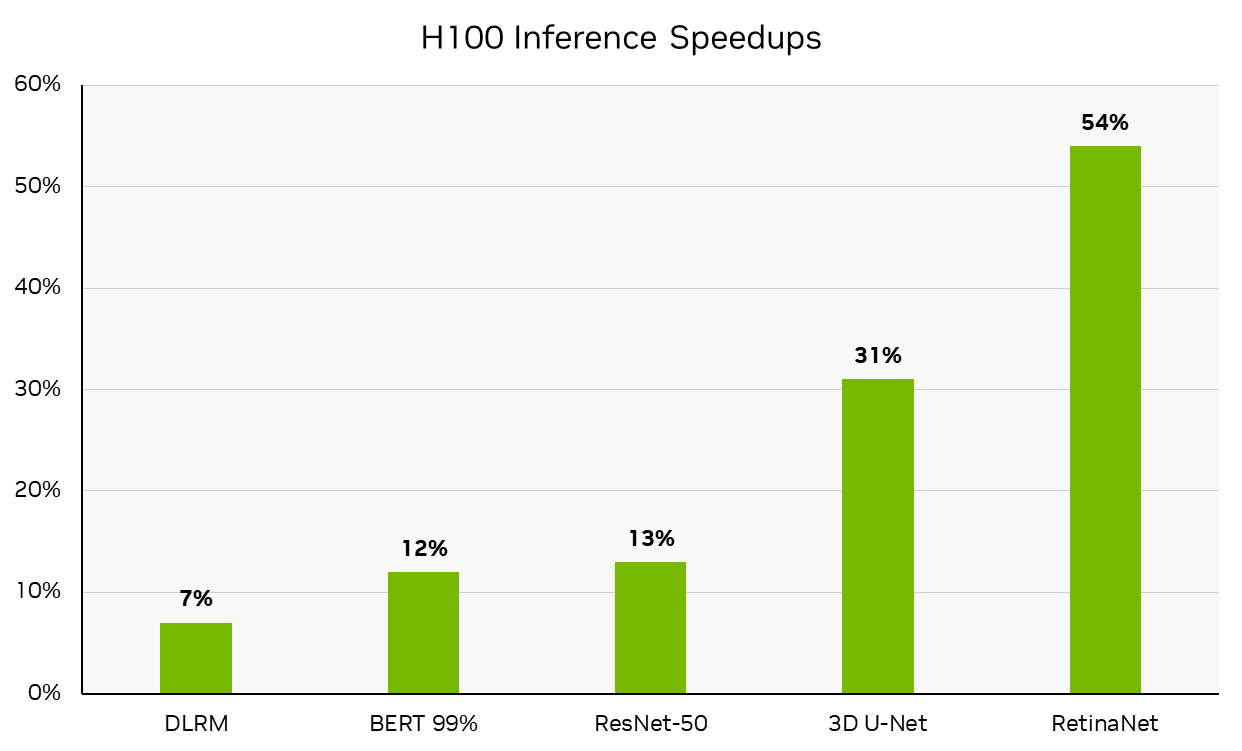
Per-accelerator performance is not a primary metric of MLPerf Inference. MLPerf Inference v3.0: Datacenter, Closed. Performance increase derived by calculating the percentage increase in inference throughput reported in MLPerf Inference v3.0 result ID 3.0-0070 (Available) compared to the inference throughput reported in MLPerf Inference v2.1 result ID 2.1-0121 (Preview). The MLPerf name and logo are trademarks of MLCommons Association in the United States and other countries. All rights reserved. Unauthorized use strictly prohibited. See www.mlcommons.org for more information.
NVIDIA L4 Tensor Core GPU vaults ahead
In MLPerf Inference v3.0, NVIDIA made the debut submission of the NVIDIA L4 Tensor Core GPU. Based on the new NVIDIA Ada Lovelace architecture, L4 is the successor to the popular NVIDIA T4 Tensor Core GPU, delivering significant improvements for AI, video, and graphics in the same single-slot, low-profile PCIe form factor.
NVIDIA Ada Lovelace architecture incorporates 4th Gen Tensor Cores with FP8, enabling excellent inference performance even at high accuracy. In MLPerf Inference v3.0, L4 delivered up to 3x more performance than T4 at 99.9% of the reference (FP32) accuracy of BERT—the highest BERT accuracy level tested in MLPerf Inference v3.0.
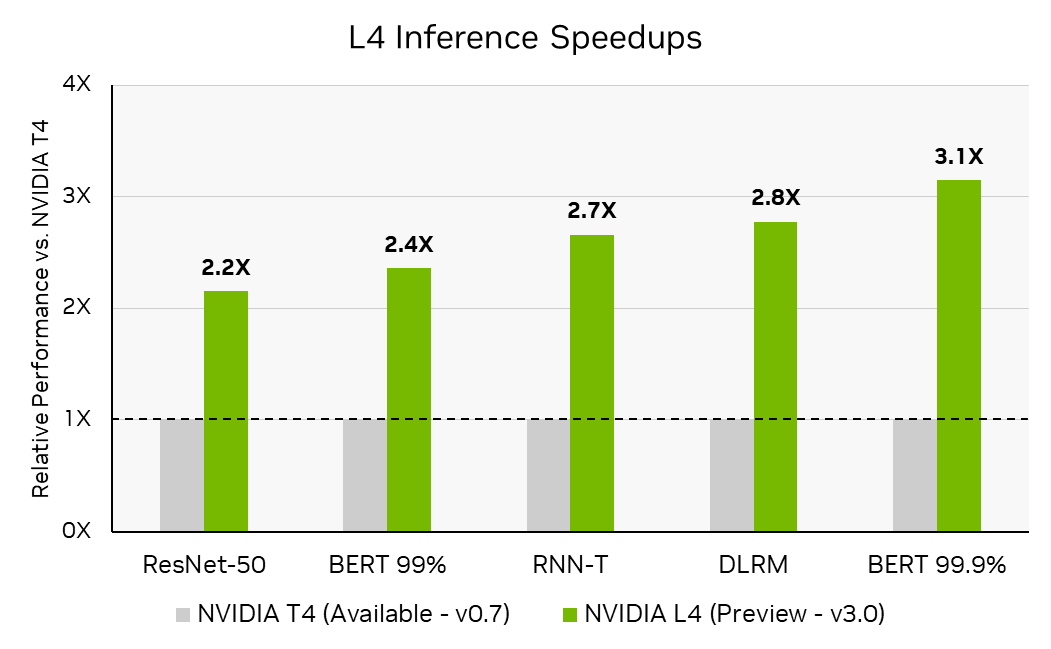
Per-accelerator throughput is not a primary metric of MLPerf Inference. MLPerf Inference v3.0: Datacenter Closed. Inference speedups calculated by dividing the inference throughputs reported in MLPerf Inference v0.7 result ID 0.7-113 by the number of accelerators to calculate T4 Tensor Core GPU per-accelerator throughput and calculating the ratios of the inference performance of the L4 Tensor Core GPU in 3.0-0123 (Preview) by the calculated per-accelerator throughput of T4. The MLPerf name and logo are trademarks of MLCommons Association in the United States and other countries. All rights reserved. Unauthorized use strictly prohibited. See www.mlcommons.org for more information.
The NVIDIA L4 also incorporates a large L2 cache, providing additional opportunity to increase performance and energy efficiency. In the NVIDIA MLPerf Inference v3.0 submission, two key software optimizations were implemented to take advantage of the larger L2 cache: cache residency and persistent cache management.
The larger L2 cache on L4 enabled the MLPerf workloads entirely within the cache. The L2 cache provides higher bandwidth at lower power than GDDR memory, so the significant reduction in GDDR accesses helped to both increase performance and reduce energy use.
Up to 1.4x higher performance was observed when batch sizes were optimized to enable the workloads to fit entirely within the L2 cache, compared to the performance when batch sizes were set to maximum capacity.
Another optimization used the L2 cache persistence feature first introduced in the NVIDIA Ampere architecture. This enables developers, with a single call to TensorRT, to tag a subset of the L2 cache so that it can be prioritized for retention (that is, scheduled to be evicted last). This feature is especially useful for inference when working under a regime of residency, as developers can target the memory being reused for layer activations across model execution, dramatically reducing GDDR write bandwidth usage.
Network division submission with NVIDIA DGX A100 and NVIDIA networking
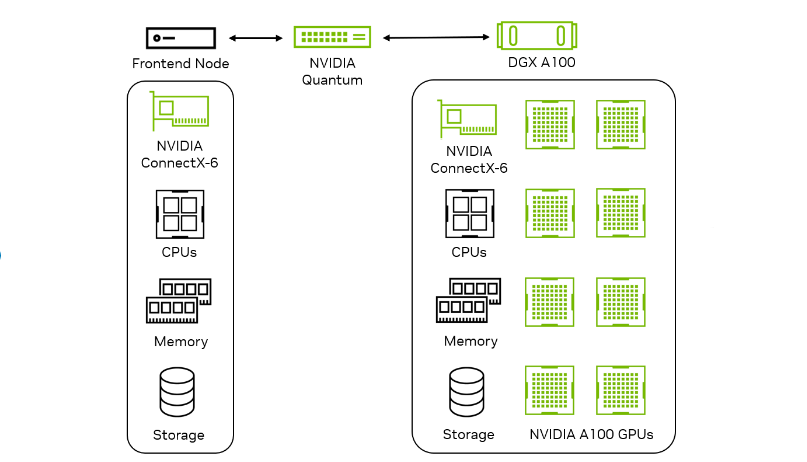
In MLPerf Inference v3.0, NVIDIA made its debut submission in the Network Division, which aims to measure the impact of networking on inference performance in a real data center setup. Network fabric such as Ethernet or NVIDIA InfiniBand connects the inference Accelerator nodes to the query generation Frontend nodes. The goal is to measure Accelerator node performance, along with the impact of networking components such as NIC, switch, and fabric.
| Benchmark | NVIDIA DGX A100 x8 | Performance of Network Division compared to Closed Division |
| RN50 Low Accuracy | Offline | 100% |
| RN50 Low Accuracy | Server | 100% |
| BERT Low Accuracy | Offline | 94% |
| BERT Low Accuracy | Server | 96% |
| BERT High Accuracy | Offline | 90% |
| BERT High Accuracy | Server | 96% |
Percentage of performance of Network Division submission relative to corresponding Closed Division submission is not a primary metric of MLPerf Inference v3.0. Percentages calculated by dividing the reported throughputs on ResNet-50 and BERT in MLPerf Inference v3.0 result ID 3.0-0136 by those reported in 3.0-0068. The MLPerf name and logo are trademarks of MLCommons Association in the United States and other countries. All rights reserved. Unauthorized use strictly prohibited. See www.mlcommons.org for more information.
In v3.0 Network Division, NVIDIA made submissions on the ResNet-50 and BERT data center workloads. These achieved 100% of single node performance on ResNet-50 by leveraging the high-bandwidth and low-latency GPUDirect RDMA technology on NVIDIA ConnectX-6 InfiniBand smart adapters. BERT had a minimal performance impact due to batching overhead on the host.
Several NVIDIA technologies came together to enable these performant results:
- Optimized inference engine from TensorRT
- InfiniBand Remote Direct Memory Access (RDMA) network transfer for low-latency, high-throughput tensor communication, built on IBV verbs in Mellanox OFED software stack
- Ethernet TCP socket for configuration exchange, run-state synchronization, and heartbeat monitoring
- NUMA-aware implementation utilizing CPU/GPU/NIC resources for best performance
NVIDIA Jetson Orin NX delivers significant performance boost
NVIDIA Jetson Orin NX 16 GB module is the most advanced AI computer for smaller, lower-power autonomous machines. It delivered up to 3.2x more performance compared to its predecessor, NVIDIA Jetson Xavier NX, in its first MLPerf Inference submission. NVIDIA partnered with Connect Tech on the Jetson Orin NX MLPerf Inference v3.0 submission, which was hosted on a Boson NGX007 carrier board. The Connect Tech Boson supports the Jetson Orin NX series and Jetson Orin Nano series with a compact carrier board that can be used for development and production; pairing the power of Orin with the convenience of commercial off-the-shelf.
The submission runs out of the box on Jetson Orin NX using the Boson NGX007 L4T image from Connect Tech and the Jetson AGX Orin software stack consisting of CUDA, cuDNN, and TensorRT. Jetson AGX Orin and Jetson Orin NX share the same submission code, demonstrating the versatility of the NVIDIA software stack to run on new Jetson products, third-party carrier boards, and host systems.
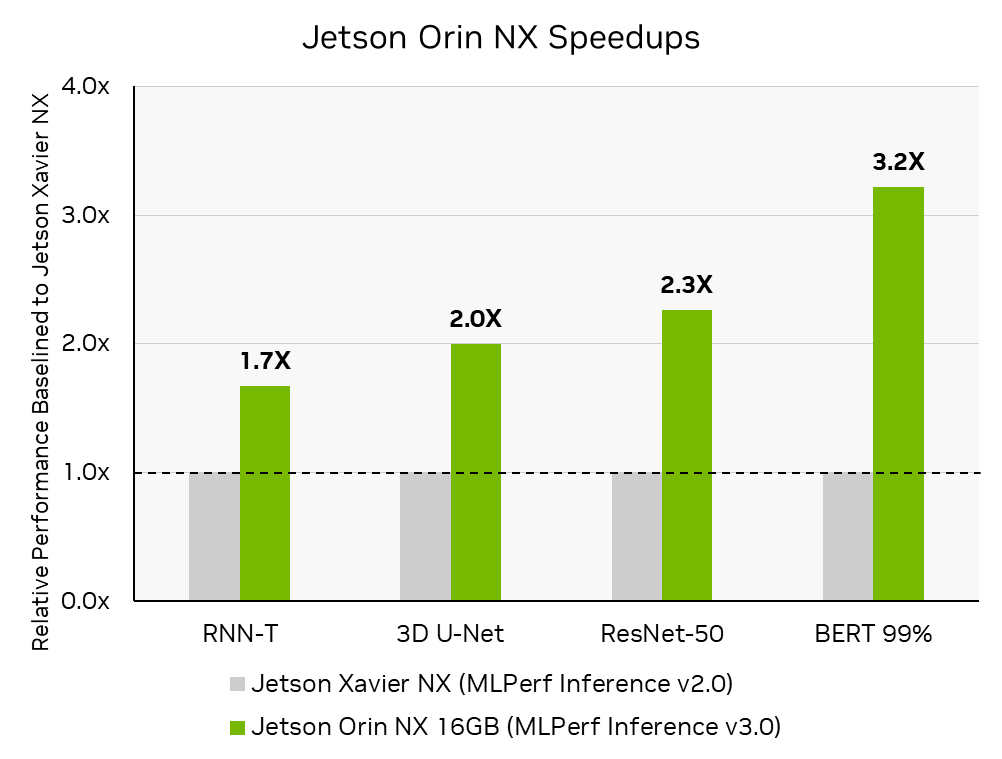
MLPerf Inference v3.0: Edge, Closed. Performance increase derived by calculating the increase in inference throughput reported in MLPerf Inference v3.0: Edge, Closed MLPerf-IDs 3.0-0079 compared to those reported in MLPerf Inference v2.0: Edge, Closed MLPerf ID 2.0-113. The MLPerf name and logo are trademarks of MLCommons Association in the United States and other countries. All rights reserved. Unauthorized use strictly prohibited. See www.mlcommons.org for more information.
RetinaNet optimizations
In MLPerf Inference v3.0, NVIDIA increased RetinaNet throughput by 20-60% across all submitted products, enabled by full-stack kernel improvements and optimized non-maximum suppression (NMS).
The RetinaNet NMS preprocessing phase has significant compute throughput and memory bandwidth due to the reshape, transpose, and concatenation of the 10 convolution layer outputs into two tensors. The serialization and filtering also resulted in compute resource underutilization.
To address these, NVIDIA developed an optimized kernel that transposes the convolution layer outputs in parallel. Additionally, label score filtering was fused with transpose, thus hiding memory load overhead and speeding the subsequent segment sorting. With these optimizations, NMS is now 50% faster than in 2.1.
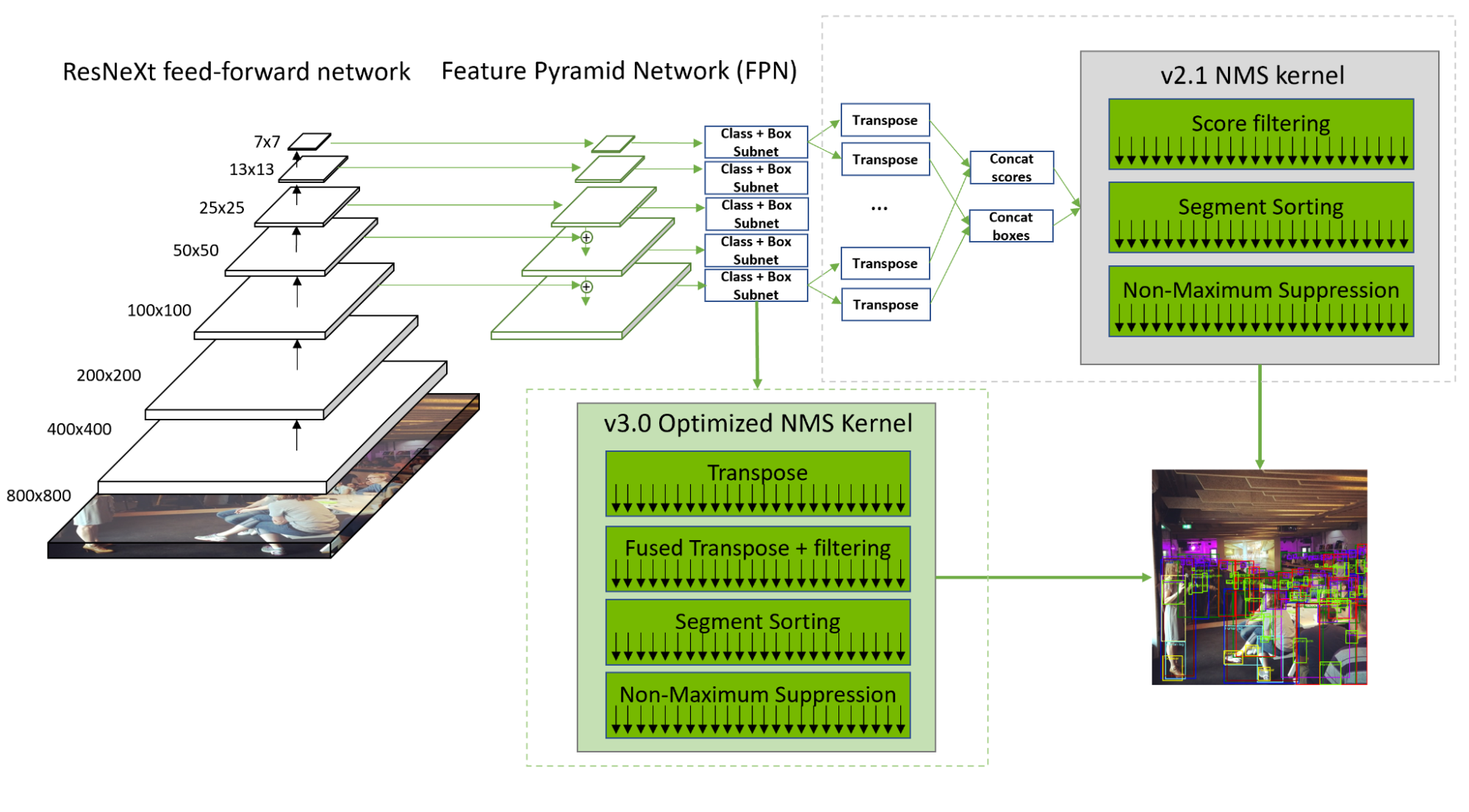
NVIDIA also added support for running large convolutions and RetinaNet in the Deep Learning Accelerator (DLA) cores of NVIDIA Orin. Available now in DLA 3.12.1 and TensorRT 8.5.2, this support enables the non-NMS part of RetinaNet to run entirely on DLAs, rather than workload shifting between GPU and DLA. The entire non-NMS portion can be compiled to a single DLA loadable and offloaded to runtime enabling RetinaNet to run concurrently on GPU and DLAs.
DLA 3.12.1 optimizations minimize both latency and DRAM bandwidth by boosting its SRAM utilization, as well as a new search algorithm to determine optimal split ratios between activation and weight data in SRAM. Visit NVIDIA/Deep-Learning-Accelerator-SW on GitHub for details.
This reduced latency by 20% and DRAM consumption by 50%. These DLA optimizations also benefit other CNN workloads. Additionally, DLA software also optimizes the ResNeXt grouped convolution pattern, resulting in a 1.8x speedup and a 1.8x reduction in DRAM traffic.
Such effective utilization of the Orin DLA capabilities was critical in speeding up RetinaNet by more than 50% in both performance and power efficiency (in less than a year on the same hardware), delivering on the NVIDIA commitment to constantly improve software performance on Jetson AGX Orin. See Delivering Server-Class Performance at the Edge with NVIDIA Jetson Orin to learn more.
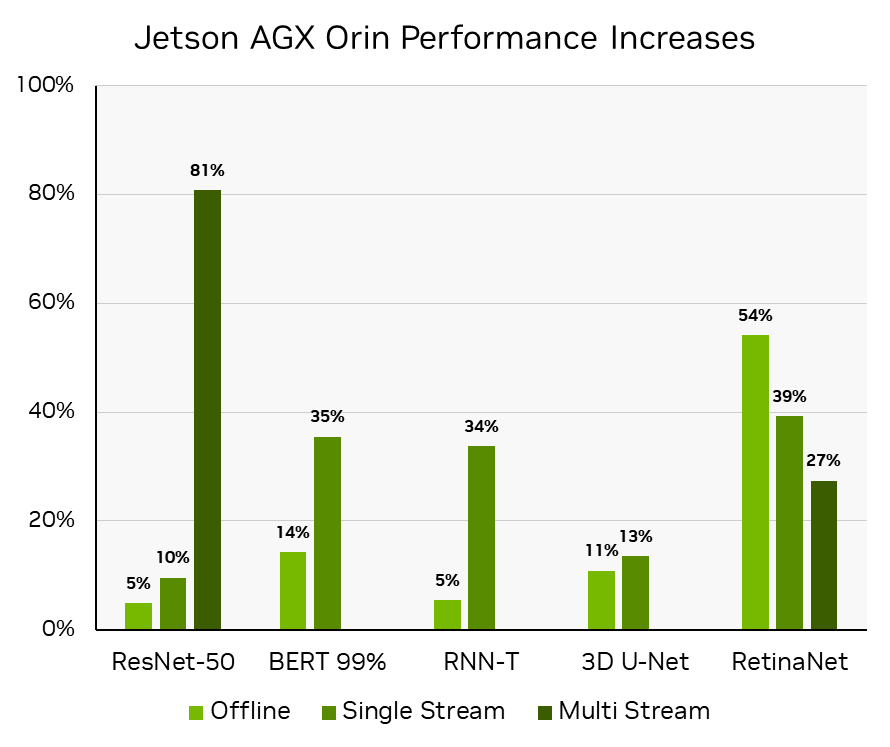
Performance increase derived by calculating the percent increase in inference throughput reported in MLPerf Inference v3.0: Edge, Closed. MLPerf-IDs 3.0-0080 compared to those reported in MLPerf Inference v2.0: Edge, Closed 2.0-140 for ResNet-50, BERT, and RNN-T workloads, and to those reported in MLPerf Inference v2.1: Edge, Closed 2.1-0095 for RetinaNet, as RetinaNet was first added in v2.1. The MLPerf name and logo are trademarks of MLCommons Association in the United States and other countries. All rights reserved. Unauthorized use strictly prohibited. See www.mlcommons.org for more information.
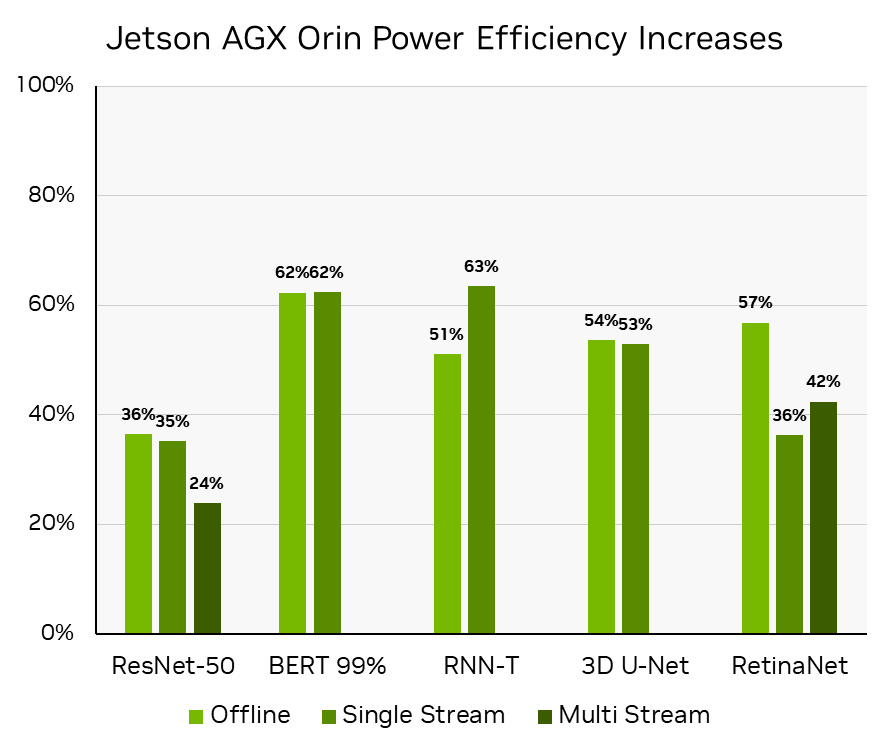
MLPerf Inference v3.0: Edge, Closed, Power. Power efficiency is derived by calculating the increase in throughput/watt for Offline scenarios and Joules/Stream for the Single- and Multi-Stream scenarios in MLPerf Inference v3.0 MLPerf-ID 3.0-0081 compared to MLPerf Inference v2.0 MLPerf-ID 2.1-141 for ResNet-50, BERT, and RNN-T workloads, and MLPerf Inference v2.1 MLPerf ID 2.1-0096 for RetinaNet, as RetinaNet was first added in MLPerf Inference v2.1.
3D U-Net sliding window batching
3D U-Net uses sliding window inference on the KiTS19 input data. Each input image is divided into ROI sub-volumes with 50% overlap and used for subvolume segmentation. Results are aggregated and normalized to obtain the segmentation for the input image. See Getting the Best Performance on MLPerf Inference 2.0 to learn more.
For MLPerf Inference v3.0, sliding window batching was introduced for batching of subvolumes. Since the batching is on subvolumes of a given image only and not between different images, this benefits the single-stream scenario as well. (See MLPerf Inference: NVIDIA Innovations Bring Leading Performance for more details.) This improves GPU utilization, particularly with NVIDIA A100 and H100 GPUs, leading to up to 30% higher performance.
The challenge is to ensure functional correctness during race conditions introduced in the final output tensor aggregation of overlapped elements. To solve this, CUDA Cooperative Groups were employed in the aggregation and normalization kernel. Though this adds synchronization overhead, it yields better performance due to the gain from batching neighboring subvolumes together. Subvolumes have a 50% data overlap, which improves caching and reduces memory traffic.
ResNet-50 optimizations
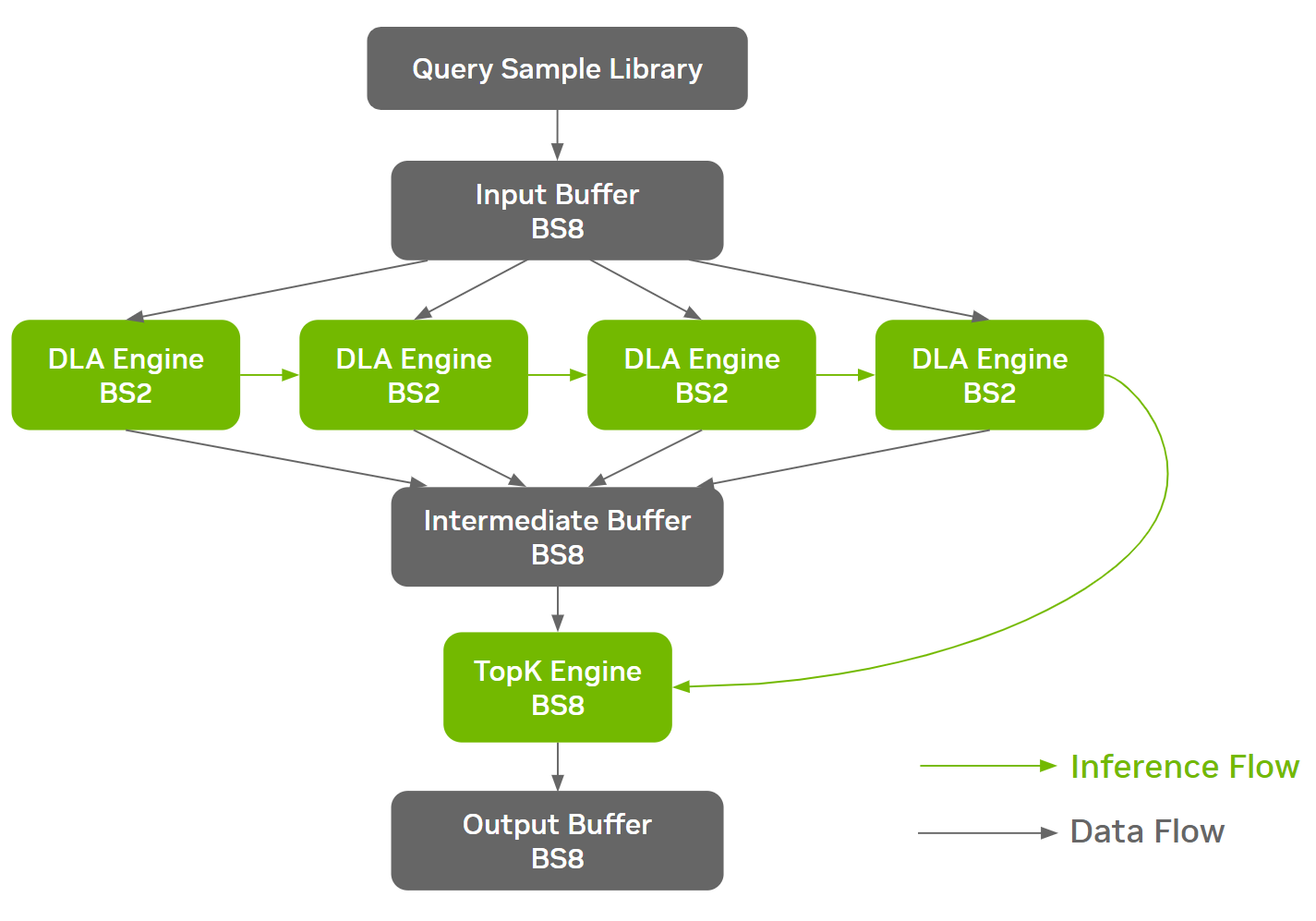
Workloads such as ResNet-50 have diverse memory characteristics at different stages of the network architecture, creating opportunities for DRAM-oriented optimizations. One such optimization employed in the NVIDIA MLPerf Inference v3.0 ResNet-50 submission was batch splitting.
This enables different batch sizes to run at different stages of the network, finding the optimal tradeoff between efficiency and DRAM bandwidth utilization. The NVIDIA submission employs splitting of larger batches into smaller batches ahead of memory-heavy sections, running inference on them sequentially, and then gathering them back into larger batches.
During the build phase, ONNX GraphSurgeon automatically recognizes defined cut points and splits the single ONNX model into multiple cloned subgraphs. TensorRT generates an independent engine for every unique ONNX partition. The harness is responsible for orchestrating the execution of the engines and the management of the communication buffers so that no additional device-to-device (D2D) copies are introduced.
With the batch splitting approach, ~3% end-to-end performance improvement was achieved in the ResNet-50 Offline on Orin systems. The figure below illustrates the data flow and the inference flow in the harness as an example.
NVIDIA AI inference leadership from cloud to edge
The NVIDIA platform continues to advance AI inference performance through extensive full-stack engineering. Through software, NVIDIA H100 Tensor Core GPU delivered up to a 54% increase in inference performance in one round. Deep software-hardware co-optimization enabled the NVIDIA L4 Tensor Core GPU to deliver up to 3x more performance compared to the NVIDIA T4 GPU.
For autonomous machines and robotics, NVIDIA Jetson AGX Orin saw performance and performance per watt boosts by more than 50%. The NVIDIA Jetson Orin NX delivered up to 3.2x more performance than its predecessor.
The NVIDIA platform also continues to showcase leading versatility, delivering exceptional performance across all MLPerf Inference workloads. As AI continues to transform computing, the need to deliver great performance across a diverse and growing set of workloads, across a growing set of deployment options, will only increase. The NVIDIA platform is evolving rapidly to meet the current needs of AI-powered applications while preparing to accelerate those of the future.
