
AI continues to drive breakthrough innovation across industries, including consumer Internet, healthcare and life sciences, financial services, retail, manufacturing, and supercomputing. Researchers continue to push the boundaries of what’s possible with rapidly evolving models that are growing in size, complexity, and diversity. In addition, many of these complex, large-scale models need to deliver results in real time for AI-powered services like chatbots, digital assistants, and fraud detection to name a few.
Given the wide array of uses for AI inference, evaluating performance poses numerous challenges for developers and infrastructure managers. For AI inference on data center, edge, and mobile platforms, MLPerf Inference 1.1 is an industry-standard benchmark that measures performance across computer vision, medical imaging, natural language, and recommender systems. These benchmarks were developed by a consortium of AI industry leaders, providing the most comprehensive set of peer-reviewed performance data available today, both for AI training and inference.
To perform well on the wide array of tests in this benchmark requires a full-stack platform with great ecosystem support, both for frameworks and networks. NVIDIA was the only company to make submissions for all data center and edge tests and deliver leading performance across the board.
One of the great byproducts of this work is that many of these optimizations have found their way into inference developer tools like TensorRT and NVIDIA Triton. The TensorRT SDK for high-performance deep learning inference includes a deep learning inference optimizer and runtime that delivers low latency and high throughput for deep learning inference applications.
The Triton Inference Server software simplifies the deployment of AI models at scale in production. This open-source inference serving software enables teams to deploy trained AI models from any framework from local storage or cloud platform on any GPU– or CPU-based infrastructure.
By the numbers
Across the board in both data center and edge categories, NVIDIA took top spots in performance tests with the NVIDIA A100 Tensor Core GPU and all but one with our NVIDIA A30 Tensor Core GPU. Over the last year since results for MLPerf Inference 0.7 were published, NVIDIA delivered up to 50% more performance from software improvements alone.
In another industry first, NVIDIA made the first-ever datacenter category submissions with a GPU-accelerated Arm-based server, which supported all workloads and delivered results equal to those seen on a similarly configured x86-based server. These new Arm-based submissions set new performance world records for GPU-accelerated Arm servers. This marks an important milestone for these platforms as they have now proven themselves in a peer-reviewed industry-standard benchmark to deliver market-leading performance. It also shows the performance, versatility, and readiness of the NVIDIA Arm software ecosystem for tackling computing challenges in the data center.

MLPerf v1.1 Inference Closed; Per-accelerator performance derived from the best MLPerf results for respective submissions using reported accelerator count in Data Center Offline. x86 Server: 1.1-034, Arm Server: 1.1-033 MLPerf name and logo are trademarks. Source: www.mlcommons.org.
A look at overall performance shows that NVIDIA leads across the board. Figure 2 shows results for the server scenario, where inference work for the system-under-test is generated using a Poisson distribution to model real-world workload patterns more closely.
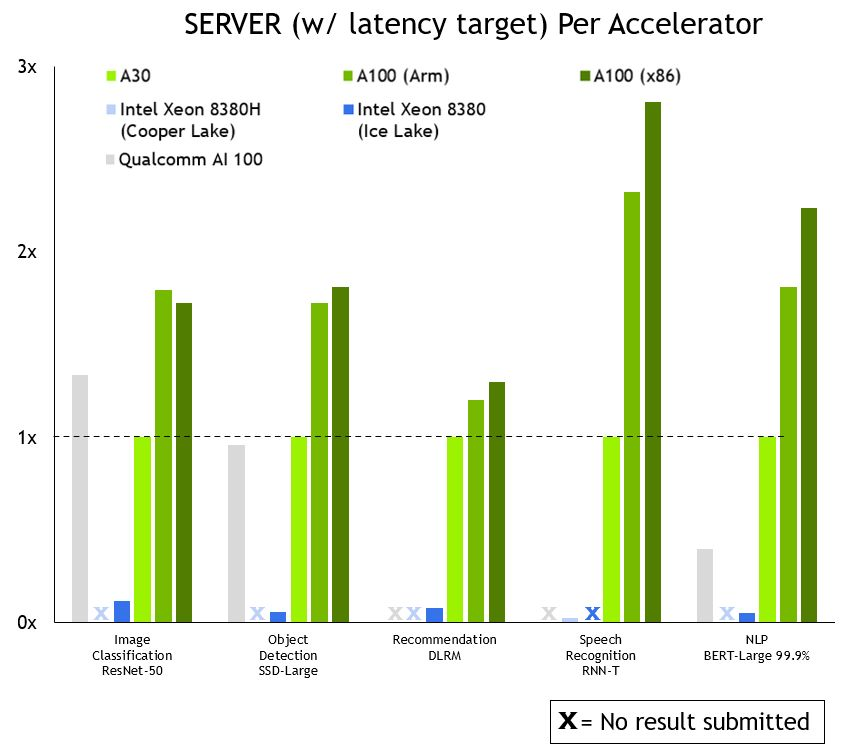
MLPerf v1.1 Inference Closed; Per-accelerator performance derived from the best MLPerf results for respective submissions using reported accelerator count in Data Center Offline and Server. Qualcomm AI 100: 1.1-057 and 1.1-058, Intel Xeon 8380: 1.1-023 and 1.1-024, Intel Xeon 8380H 1.1-026, NVIDIA A30: 1.1-43, NVIDIA A100 (Arm): 1.1-033, NVIDIA A100 (X86): 1.1-047. MLPerf name and logo are trademarks. For more information, see www.mlcommons.org.
NVIDIA outperforms CPU-only servers across the board, by as much as 104x. This performance advantage translates into an ability to run inference on larger, more complex models, as well as multiple models run in real-time jobs in conversational AI, recommender systems, and digital assistants.
Optimizations behind the results
Our engineering team implemented several optimizations to make these great results possible. For starters, all these results—both for Arm–based and x86-based servers—were generated using TensorRT 8, which is now generally available. Of particular interest was the use of non-power-of-two kernels, which was implemented to speed up workloads such as the BERT-Large Single Stream scenario test.
NVIDIA submissions take advantage of the new host policy feature added to the NVIDIA Triton Inference server. You can specify a host policy while configuring the NVIDIA Triton server that enables thread and memory pinning in the server application. With this feature, NVIDIA Triton can specify the optimal location of inputs for every GPU in the system. The optimal location can be based on the non-uniform memory architecture (NUMA) configuration of the system, in which case there is a query sample library on every NUMA node.
You can also use the host policy to enable the start_from_device configuration setting, where the server will pick up the input on the GPU chosen for execution. This setting can also land network inputs directly into GPU memory, entirely bypassing the CPU and system memory copies.
Inference power trio: TensorRT, NVIDIA Triton, and NGC
NVIDIA inference leadership comes from building the most performant AI accelerators, both for training and inference. But just as important is the NVIDIA end-to-end, full-stack software ecosystem that supports all AI frameworks and more than 800 HPC applications.
All this software is available at NGC, the NVIDIA hub with GPU-optimized software for deep learning, machine learning, and HPC. NGC takes care of all the plumbing so data scientists, developers, and researchers can focus on building solutions, gathering insights, and delivering business value.
NGC is freely available through the marketplace of your preferred cloud provider. There, you can find the latest versions of both TensorRT as well as NVIDIA Triton, both of which were instrumental in producing the latest MLPerf Inference 1.1 results.
For more information about the NVIDIA inference platform, see the Inference Technical Overview paper that covers the trends in AI inference, challenges around deploying AI applications, and details of inference development tools and application frameworks.