
The latest release of CUDA Toolkit, version 12.4, continues to push accelerated computing performance using the latest NVIDIA GPUs. This post explains the new features and enhancements included in this release:
- CUDA driver update
- Access-counter-based memory migration for NVIDIA Grace Hopper systems
- Confidential Computing support
- CUDA Graphs conditionals
- CUB Performance improvements
- Compiler updates
- Enhanced Monitoring capabilities
- Enhanced NVIDIA Nsight Compute and NVIDIA Nsight Systems Developer Tools
CUDA and the CUDA Toolkit software provide the foundation for all NVIDIA GPU-accelerated computing applications in data science and analytics, machine learning, deep learning with large language models (LLMs) for both training and inference, graphics and simulation, and scientific computing. The CUDA software stack and ecosystem delivers a platform to help developers solve the world’s most complex computing problems, particularly in multi-GPU and multi-node distributed architectures.
CUDA drivers for Linux (R550) and Windows (R551)
Each release of the CUDA Toolkit requires a minimum version of the CUDA driver. The CUDA driver is backward-compatible, meaning that applications compiled against a particular version of CUDA will continue to work on later driver releases. For more information on compatibility, see the CUDA C++ Best Practices Guide.
Access-counter-based migration for NVIDIA Grace Hopper memory
This release introduces a new memory migration algorithm for NVIDIA Grace Hopper systems. It uses hardware access counters to determine memory page access patterns and migrates memory to the hardware memory (CPU or GPU) from which it’s accessed most often. The result is enhanced data locality for most applications, enabling the use of system-allocated memory (using standard calls like malloc and mmap) from third-party libraries directly in GPU-accelerated kernels.
As this is the first release with the capability enabled, developers may find that applications that had been optimized for earlier memory migration algorithms may see a performance regression if optimized for the earlier behaviors. Should this occur, we’ve introduced a supported but temporary flag to opt out of this behavior. You can control the enablement of this feature by unloading and reloading the NVIDIA UVM driver:
# modprobe -r nvidia_uvm
# modprobe nvidia_uvm uvm_perf_access_counter_mimc_migration_enable=0
Setting the parameter to the value 1 will enable access-counter-based migration, and 0 will disable it.
NVIDIA Confidential Computing
NVIDIA Confidential Computing solutions for the NVIDIA Hopper architecture are now available for general access. Secure and protect your workloads from unauthorized access and physical attacks. For more information, see NVIDIA Trusted Computing Solutions.
CUDA Graphs enhancements
CUDA Graphs APIs continue to be the most efficient way to launch repeated invocations of complex on-device functional sequences. CUDA Toolkit 12.4 introduces many enhancements to CUDA Graphs, including conditional nodes, device-side node parameter updates, and more.
Graph conditional nodes
In many applications, having dynamic control over the execution of work in CUDA Graphs can substantially increase the flexibility and ease-of-use of graph launches. For instance, you may have an algorithm that involves iterating over a series of operations many times until the result converges below a certain threshold, as is common in AI. CUDA Toolkit 12.4 improves on APIs for runtime control of conditional graph nodes, a feature introduced with release 12.3.
Conditional nodes can contain work described by a graph, which is executed conditionally or in a loop. In addition, support is now available for a new type of child graph for memory allocation nodes within the conditional node body, as well as new capture functionality to capture into these child graphs.
Device-side node parameter update for device graphs
With CUDA Toolkit 12.4, it’s now possible to dynamically update kernel node parameters (grid geometry and other kernel parameters) through device-side APIs for nodes residing within on-device graphs. At graph creation, a node can “opt in” to being device-updatable through a new kernel node attribute. This attribute, when enabled, will return the device node handle as part of the setAttribute call.
Device-updatable kernel nodes can be updated from any other kernel, be it from another graph, the same graph, or even a stream kernel launch.
Once a node has opted in to being device-updatable, it can no longer be removed from the graph using cudaGraphnodeDestroy. The node can also no longer opt out of being device-updatable once it has opted into this functionality, nor can it be updated to a function on a different device or context after opting into this functionality.
To opt in to this feature, set the attribute CU_KERNEL_NODE_ATTRIBUTE_DEVICE_UPDATABLE_KERNEL_NODE on the node after node creation. Once enabled, node parameters can be controlled using the following API calls:
cudaGraphKernelNodeSetGridDimcudaGraphKernelNodeSetEnabledcudaGraphKernelNodeSetParam
Updatable graph node priorities without recompilation
When recording graph nodes from streams, it’s often desirable to record and honor the stream priority of the graph nodes at the time of capture rather than assigning priorities heuristically. CUDA Toolkit 11.7 introduced the ability for all graph nodes to work in this way, using a flag passed into cuGraphInstantiate. However, requiring a compile-time flag can make it inconvenient for users to switch between using the recorded and heuristic profiles without a full recompile.
CUDA Toolkit 12.4 introduces the new environment variable CUDA_GRAPHS_USE_NODE_PRIORITY to enable control over graph node priorities at runtime. The environment variable operates according to the behavior outlined in Table 1.
CUDA_GRAPHS_USE_NODE_PRIORITY value | UseNodePriority behavior on graph instantiate |
| 0 | UseNodePriority is cleared on all graph instantiations |
| Non-zero | UseNodePriority is set on all graph instantiations |
| Unset | Flag passed in graph instantiate (or default flag value) is used |
CUDA_GRAPHS_USE_NODE_PRIORITY environment variable settingsCUB performance enhancements
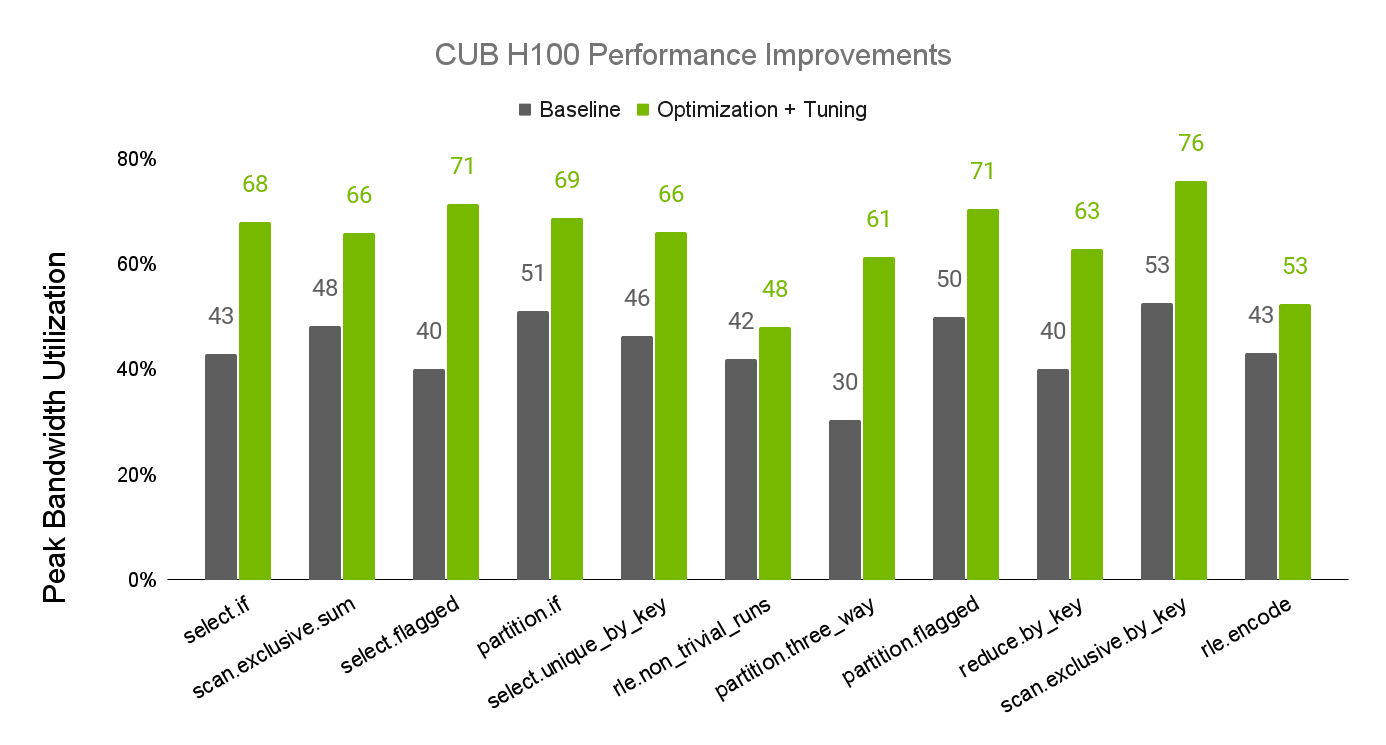
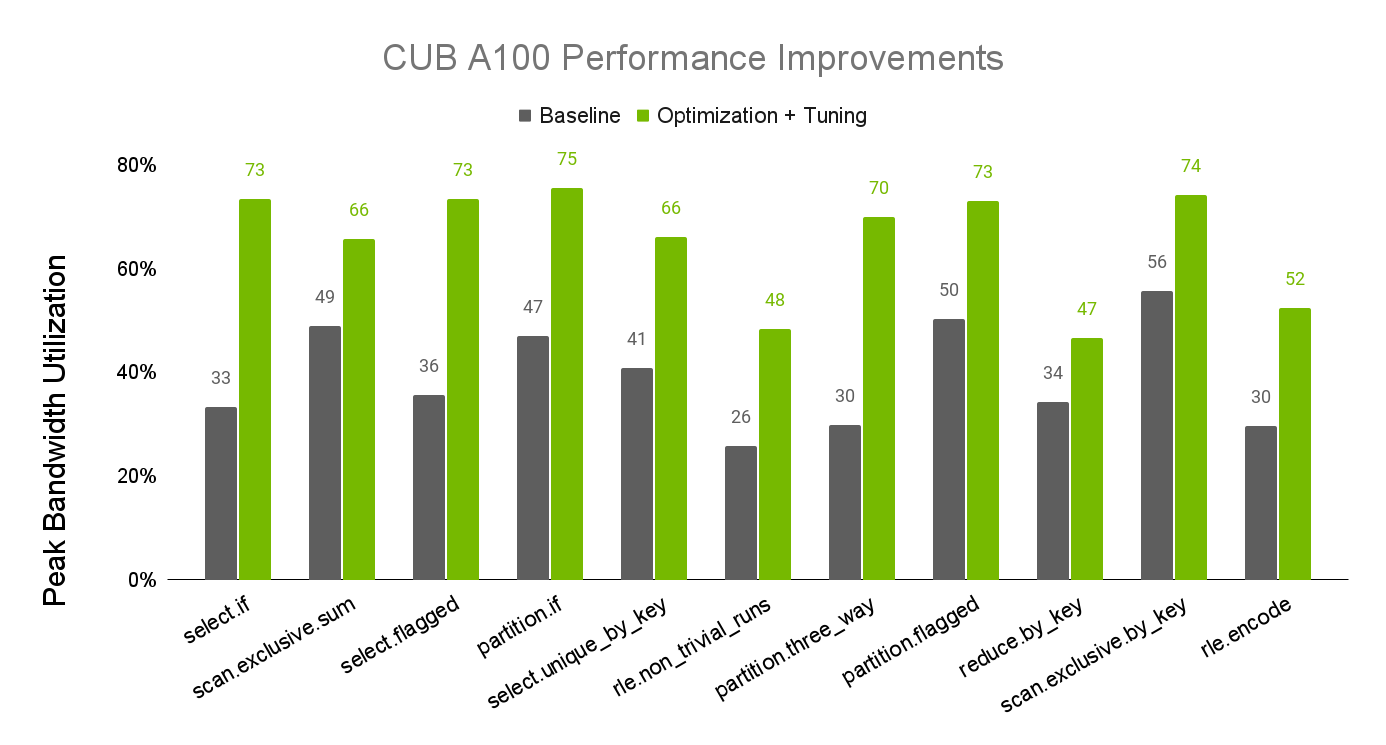
CUB is a component of the CUDA C++ Core Libraries available both in CUDA Toolkit and through NVIDIA/cccl on GitHub. Recent updates to the performance tuning of CUB have resulted in substantial performance improvements to CUB algorithms on NVIDIA A100 and H100 GPUs. Figures 1 and 2 show the improvements to algorithm performance, as measured by their realized percentage of available device memory bandwidth.
For more information about CUB performance tuning, see the CUB Tuning Infrastructure documentation.
Compiler updates
The CUDA Toolkit 12.4 release introduces support for GCC 13 as a host-side compiler, along with improved compile-time performance. It also offers a new library, nvFatbin, to enable runtime manipulation of binary objects supporting multiple GPU architectures. This library enables programmatic creation of fat binaries, making it easier to work with runtime compilation.
Enhanced monitoring capabilities
This release provides many new metrics to NVIDIA Management Library (NVML) and NVIDIA System Management Interface (nvidia-smi) enhancing visibility into overall GPU utilization at scale:
- NVJPG and NVOFA utilization percentage
- PCIe class and subclass reporting
dmonreports now available in CSV format- More descriptive error codes returned from NVML
dmonnow reports gpm metrics for MIG (that is,nvidia-smi dmon --gpm-metricsruns in MIG mode)- NVML running against older drivers will report
FUNCTION_NOT_FOUNDin some cases, failing gracefully if NVML is newer than the driver - NVML APIs to query protected memory information for Hopper Confidential Computing
For more information, see the NVML documentation and NVIDIA System Management Interface documentation.
NVIDIA Nsight Developer Tools
The latest versions of NVIDIA Nsight Developer Tools are included in the CUDA Toolkit 12.4 release to help you optimize and debug your CUDA applications on Grace Hopper platforms.
NVIDIA Nsight Compute
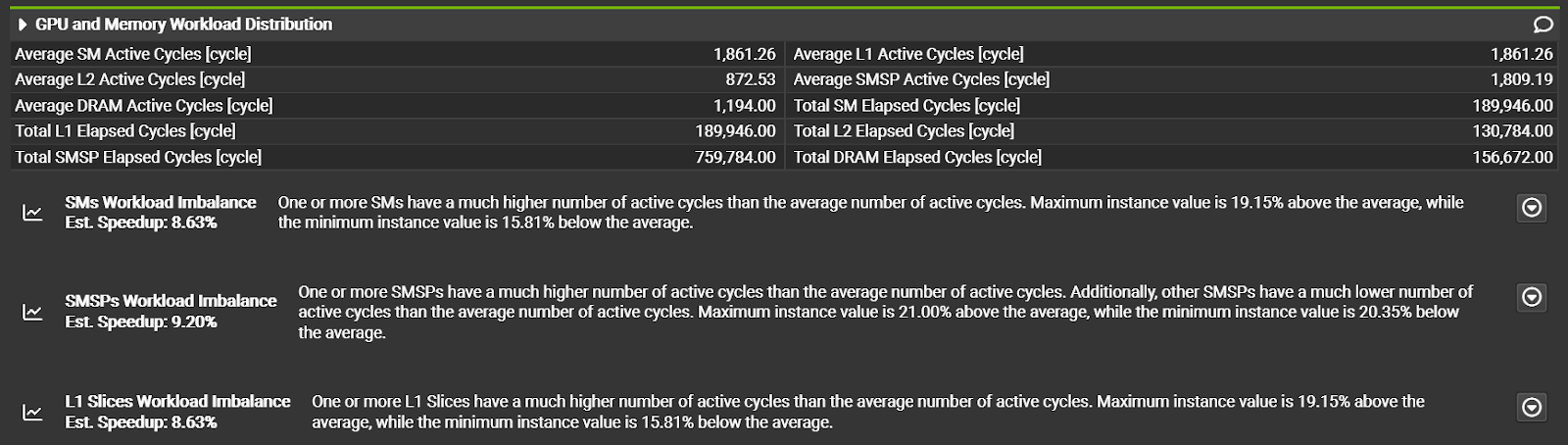
NVIDIA Nsight Compute provides detailed profiling and analysis for CUDA kernels. Version 2024.1 debuts with CUDA Toolkit 12.4. This version of Nsight Compute adds a GPU and Memory Workload Distribution section to help users understand the balance of work across SMs and the memory system. New rules identify load imbalances where uneven work distribution could be impacting performance. Use this new section and the built-in rules to detect uneven workload distributions that may keep you from achieving peak performance.
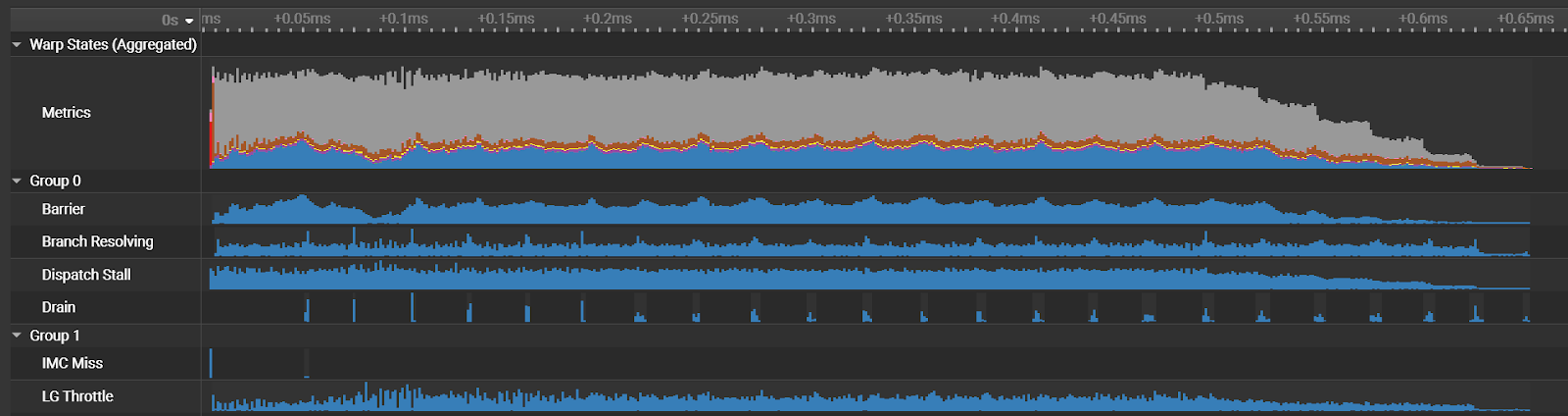
In addition, a new PM Sampling Warp State section provides more detailed time-correlated performance information and several improvements to the recently added Source Comparison page.
To learn more about Nsight Compute 2024.1 features, see Getting Started with Nsight Compute.
NVIDIA Nsight Systems
CUDA Toolkit 12.4 also includes NVIDIA Nsight Systems, a performance tuning tool that profiles hardware metrics and CUDA apps, APIs, and libraries on a unified timeline.
Nsight Systems delivers multi-node analysis scripts called recipes. These automatically triage metrics captured across the data center, helping you diagnose performance limiters. A new recipe delivers a summary of NVIDIA Collective Communications Library (NCCL) functions and their execution time. Furthermore, support for multi-node analysis has been extended to Mac, Windows x64, and Linux Arm Servers.
To learn more about what’s new in Nsight Systems, see Getting Started with Nsight Systems. For a deeper dive into how Nsight Systems supports development at data center scale, see Accelerating Data Center and HPC Performance Analysis with NVIDIA Nsight Systems.
Summary
The CUDA Toolkit 12.4 release enriches the foundational NVIDIA driver and runtime software for accelerated computing while continuing to provide enhanced support for the newest NVIDIA GPUs, accelerated libraries, compilers, and developer tools.
Want more information? Check out the CUDA documentation, browse the latest NVIDIA Deep Learning Institute offerings, and visit the NGC Catalog. Ask questions and join the conversation in the CUDA Developer Forums.
