
NVIDIA announces the newest CUDA Toolkit software release, 12.0. This release is the first major release in many years and it focuses on new programming models and CUDA application acceleration through new hardware capabilities.
For more information, watch the YouTube Premiere webinar, CUDA 12.0: New Features and Beyond.
You can now target architecture-specific features and instructions in the NVIDIA Hopper and NVIDIA Ada Lovelace architectures with CUDA custom code, enhanced libraries, and developer tools.
CUDA 12.0 includes many changes, both major and minor. Not all changes are listed here, but this post offers an overview of the key capabilities.
Overview
- Support for new NVIDIA Hopper and NVIDIA Ada Lovelace architecture features with additional programming model enhancements for all GPUs, including new PTX instructions and exposure through higher-level C and C++ APIs
- Support for revamped CUDA dynamic parallelism APIs, offering substantial performance improvements compared to the legacy APIs
- Enhancements to the CUDA Graphs API:
- You can now schedule graph launches from GPU device-side kernels by calling built-in functions. With this ability, user code in kernels can dynamically schedule graph launches, greatly increasing the flexibility of CUDA Graphs.
- The
cudaGraphInstantiateAPI has been refactored to remove unused parameters.
- Support for the GCC 12 host compiler
- Support for C++20
- New
nvJitLinklibrary in the CUDA Toolkit for JIT LTO - Library optimizations and performance improvements
- Updates to Nsight Compute and Nsight Systems Developer Tools
- Updated support for the latest Linux versions
For more information, see CUDA Toolkit 12.0 Release Notes. CUDA Toolkit 12.0 is available to download.
NVIDIA Hopper and NVIDIA Ada Lovelace architecture support
CUDA applications can immediately benefit from increased streaming multiprocessor (SM) counts, higher memory bandwidth, and higher clock rates in new GPU families. The CUDA and CUDA libraries expose new performance optimizations based on GPU hardware architecture enhancements.
CUDA 12.0 exposes programmable functionality for many features of the NVIDIA Hopper and NVIDIA Ada Lovelace architectures:
- Many tensor operations are now available through public PTX:
- TMA operations
- TMA bulk operations
- 32x Ultra xMMA (including FP8 and FP16)
- Launch parameters control
membardomains in NVIDIA Hopper GPUs - Support Hopper asynchronous transaction barrier in C++ and PTX
- Support for C intrinsics for cooperative grid array (CGA) relaxed barriers
- Support for programmatic L2 Cache to SM multicast (NVIDIA Hopper GPUs only)
- Support for public PTX for SIMT collectives:
elect_one - Genomics and DPX instructions are now available for NVIDIA Hopper GPUs to provide faster combined-math arithmetic operations (three-way max, fused add+max, and so on).
Lazy loading
Lazy loading is a technique for delaying the loading of both kernels and CPU-side modules until loading is required by the application. The default is preemptively loading all the modules the first time a library is initialized. This can result in significant savings, not only of device and host memory, but also in the end-to-end execution time of your algorithms.
Lazy loading has been part of CUDA since the 11.7 release. Subsequent CUDA releases have continued to augment and extend it. From the application development perspective, nothing specific is required to opt into lazy loading. Your existing applications work with lazy loading as-is.
If you have operations that are particularly latency-sensitive, you may want to profile your applications. The tradeoff with lazy loading is a minimal amount of latency at the point in the application where the functions are first loaded. This is overall lower than the total latency without lazy loading.
| Metric | Baseline | CUDA 11.7 | CUDA 11.8+ | Improvement |
| End-to-end runtime [s] | 2.9 | 1.7 | 0.7 | 4x |
| Binary load time [s] | 1.6 | 0.8 | 0.01 | 118x |
| Device memory footprint [MB] | 1245 | 435 | 435 | 3x |
| Host memory footprint [MB] | 1866 | 1229 | 60 | 31x |
All libraries used with lazy loading must be built with 11.7+ to be eligible.
Lazy loading is not enabled in the CUDA stack by default in this release. To evaluate it for your application, run with the environment variable CUDA_MODULE_LOADING=LAZY set.
Compatibility
CUDA minor version compatibility is a feature introduced in 11.x that gives you the flexibility to dynamically link your application against any minor version of the CUDA Toolkit within the same major release. Compile your code one time, and you can dynamically link against libraries, the CUDA runtime, and the user-mode driver from any minor version within the same major version of CUDA Toolkit.
For example, 11.6 applications can link against the 11.8 runtime and the reverse. This is accomplished through API or ABI consistency within the library files. For more information, see CUDA Compatibility.
Minor version compatibility continues into CUDA 12.x. However, as 12.0 is a new major release, the compatibility guarantees are reset. Applications that used minor version compatibility in 11.x may have issues when linking against 12.0. Either recompile your application against 12.0 or statically link to the needed libraries within 11.x to ensure the continuity of your development.
Likewise, applications recompiled or built in 12.0 will link to future versions of 12.x but will not link against components of CUDA Toolkit 11.x.
JIT LTO support
CUDA 12.0 Toolkit introduces a new nvJitLink library for JIT LTO support. NVIDIA is deprecating the support for the driver version of this feature. For more information, see Deprecated Features.
C++20 compiler support
CUDA Toolkit 12.0 adds support for the C++20 standard. C++20 is enabled for the following host compilers and their minimal versions:
- GCC 10
- Clang 11
- MSVC 2022
- NVC++ 22.x
- Arm C/C++ 22.x
For more information about features, see the corresponding host compiler documentation.
While the majority of C++20 features are available in both host and device code, some are restricted.
Module support
Modules are introduced in C++20 as a new way to import and export entities across translation units.
Because it requires complex interaction between the CUDA device compiler and the host compiler, modules are not supported in CUDA C++, in either host or device code. Uses of the module and export and import keywords are diagnosed as errors.
Coroutine support
Coroutines are resumable functions. Execution can be suspended, in which case control is returned to the caller. Subsequent invocations of the coroutine resume at the point where it was suspended.
Coroutines are supported in host code but are not supported in device code. Uses of the co_await, co_yield, and co_return keywords in the scope of a device function are diagnosed as errors during device compilation.
Three-way comparison operator
The three-way comparison operator <=> is a new kind of relational enabling the compiler to synthetize other relational operators.
Because it is tightly coupled with utility functions from the Standard Template Library, its use is restricted in device code whenever a host function is implicitly called.
Uses where the operator is called directly and does not require implicit calls are enabled.
Nsight Developer Tools
Nsight Developer Tools are receiving updates coinciding with CUDA Toolkit 12.0.
NVIDIA Nsight Systems 2022.5 introduces a preview of InfiniBand switch metrics sampling. NVIDIA Quantum InfiniBand switches offer high-bandwidth, low-latency communication. Viewing switch metrics on the Nsight Systems timeline enables you to better understand your application’s network usage. You can use this information to optimize the application’s performance.

Nsight tools are built to be used collaboratively. Performance analysis in Nsight Systems often informs a deeper dive into kernel activity in Nsight Compute.
To streamline this process, Nsight Compute 2022.4 introduces Nsight Systems integration. This feature enables you to launch system trace activity and view the report in the Nsight Compute interface. You can then inspect the report and initiate kernel profiling from within the context menu.
With this workflow, you don’t have to run two different applications: it can all be done within one.
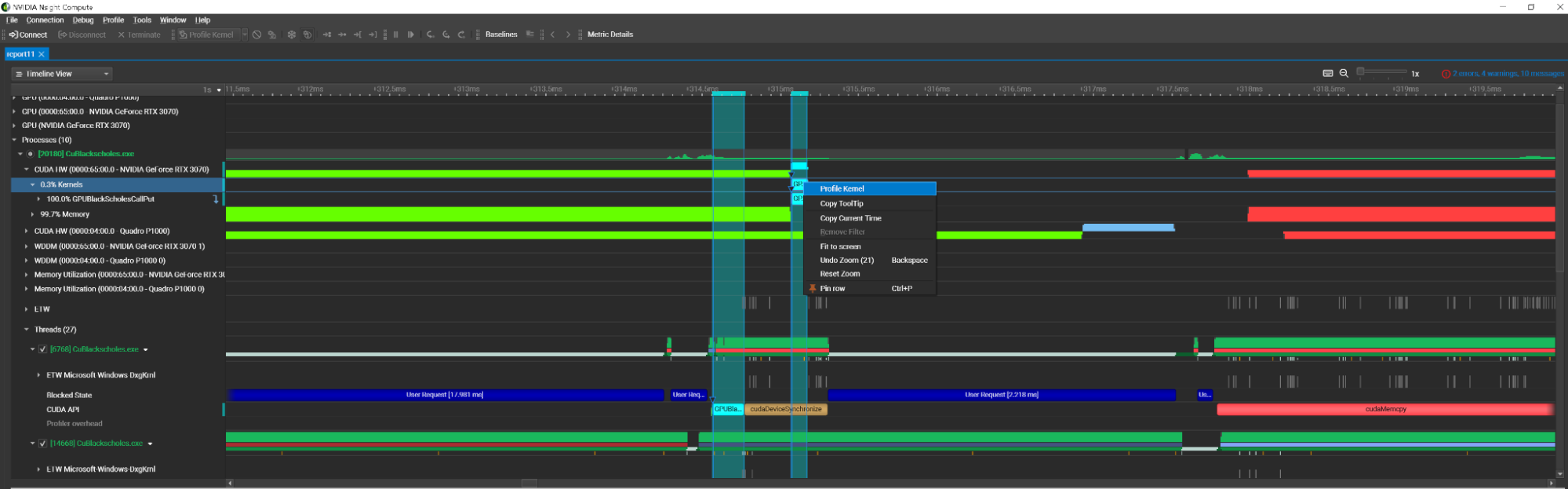
Nsight Compute 2022.4 also introduces a new inline function table that provides performance metrics split out for multiple inlined instances of a function. This heavily requested feature enables you to understand whether a function is suffering from performance issues in general or only in specific inlined cases.
It also enables you to understand where inlining is occurring, which can often lead to confusion when this level of detail is not available. The main source view continues to show the aggregation of metrics at a per-line level while the table lists the multiple locations where the function was inlined and the performance metrics for each location.
The Acceleration Structure viewer has also received a variety of optimizations and improvements, including support for NVIDIA OptiX curve profiling.
For more information, see NVIDIA Nsight Compute, NVIDIA Nsight Systems, and Nsight Visual Studio Code Edition.
Math library updates
All optimizations and features added to the library come at a cost, usually in the form of binary size. Binary size for each library has slowly increased over the course of their lifespan. NVIDIA has made significant efforts to shrink these binaries without sacrificing performance. cuFFT saw the largest size reduction, with over 50% between CUDA Toolkit 11.8 and 12.0.
There are also a few library-specific features worth calling out.
cuBLAS
cuBLASLt exposes mixed-precision multiplication operations with the new FP8 data types. These operations also support BF16 and FP16 bias fusions, as well as FP16 bias with GELU activation fusions for GEMMs with FP8 input and output data types.
Regarding performance, FP8 GEMMs can be up to 3x and 4.5x faster on H100 PCIe and SXM, respectively, compared to BF16 on A100. The CUDA Math API provides FP8 conversions to facilitate the use of the new FP8 matrix multiplication operations.
cuBLAS 12.0 extends the API to support 64-bit integer problem sizes, leading dimensions, and vector increments. These new functions have the same API as their 32-bit integer counterparts except that they have the _64 suffix in the name and declare the corresponding parameters as int64_t.
cublasStatus_t cublasIsamax(cublasHandle_t handle, int n, const float *x, int incx, int *result);
The 64-bit integer counterpart is as follows:
cublasStatus_t cublasIsamax_64(cublasHandle_t handle, int64_t n, const float *x, int64_t incx, int64_t *result);
Performance is the focus for cuBLAS. When the arguments passed to 64-bit integer API fit into the 32-bit range, the library uses the same kernels as if you called the 32-bit integer API. To try the new API, the migration should be as simple as just adding the _64 suffix to cuBLAS functions, thanks to the C/C++ autoconversion from int32_t values to int64_t.
cuFFT
During plan initialization, cuFFT conducts a series of steps, including heuristics, to determine which kernels are used as well as kernel module loads.
Starting with CUDA 12.0, cuFFT delivers a larger portion of kernels using the CUDA Parallel Thread eXecution (PTX) assembly form, instead of the binary form.
The PTX code of cuFFT kernels is loaded and compiled further to the binary code by the CUDA device driver at runtime when a cuFFT plan is initialized. The first improvement available, due to the new implementation, will enable many new accelerated kernels for the NVIDIA Maxwell, NVIDIA Pascal, NVIDIA Volta, and NVIDIA Turing architectures.
cuSPARSE
To reduce the amount of required workspace for sparse-sparse matrix multiplication (SpGEMM), NVIDIA is releasing two new algorithms with lower memory usage. The first algorithm computes a strict bound on the number of intermediate products, while the second one enables partitioning the computation in chunks. These new algorithms are beneficial for customers on devices with smaller memory storage.
INT8 support has been added to cusparseGather, cusparseScatter, and cusparseCsr2cscEx2.
Finally, for SpSV and SpSM, the preprocessing time is improved by an average factor of 2.5x. For the execution phase, SpSV is improved by an average factor of 1.1x, while SpSM is improved by an average factor of 3.0x.
Math API
The new NVIDIA Hopper architecture comes with new Genomics and DPX instructions for faster means of computing combined arithmetic operations like three-way max, fused add+max, and so on.
New DPX instructions accelerate dynamic programming algorithms by up to 7x over the A100 GPU. Dynamic programming is an algorithmic technique for solving a complex recursive problem by breaking it down into simpler sub-problems. For a better user experience, these instructions are now exposed through the Math API.
An example would be a three-way max + ReLU operation, max(max(max(a, b), c), 0).
int __vimax3_s32_relu ( const int a, const int b, const int c )
For more information, see Boosting Dynamic Programming Performance Using NVIDIA Hopper GPU DPX Instructions.
Image processing updates: nvJPEG
nvJPEG now has an improved implementation that significantly reduces the GPU memory footprint. This is accomplished by using zero-copy memory operations, fusing kernels, and in-place color space conversion.
Summary
We continue to focus on helping researchers, scientists, and developers solve the world’s most complicated AI/ML and data sciences challenges through simplified programming models.
This CUDA 12.0 release is the first major release in many years and is foundational to help accelerate applications through the use of next-generation NVIDIA GPUs. New architecture-specific features and instructions in the NVIDIA Hopper and NVIDIA Ada Lovelace architectures are now targetable with CUDA custom code, enhanced libraries, and developer tools.
With the CUDA Toolkit, you can develop, optimize, and deploy your applications on GPU-accelerated embedded systems, desktop workstations, enterprise data centers, cloud-based platforms, and HPC supercomputers. The toolkit includes GPU-accelerated libraries, debugging and optimization tools, a C/C++ compiler, a runtime library, and access to many advanced C/C++ and Python libraries.