NVIDIA announces the newest release of the CUDA development environment, CUDA 11.4. This release includes GPU-accelerated libraries, debugging and optimization tools, programming language enhancements, and a runtime library to build and deploy your application on GPUs across the major CPU architectures: x86, Arm, and POWER.
CUDA 11.4 is focused on enhancing the programming model and performance of your CUDA applications. CUDA continues to push the boundaries of GPU acceleration and lay the foundation for new applications in HPC, graphics, CAE applications, AI and deep learning, automotive, healthcare, and data sciences.
CUDA 11.4 has several important features. This post offers an overview of the key capabilities:
- CUDA Programming model enhancements:
- CUDA Graphs
- Multi-Process Service (MPS)
- Formalizing Asynchronous Data Movement
- C++ Language support – CUDA
- Compiler enhancements
- CUDA Driver Enhancements
CUDA 11.4 ships with the R470 driver, which is a long-term support branch. GPUDirect RDMA and GPUDirect technology Storage (GDS) are now part of the CUDA Driver and Toolkit. This streamlines the workflow and enables our developers to leverage these technologies without the need for separate installation of additional packages. The driver enables new MIG configurations for the recently launched NVIDIA A30 GPU, which doubles the memory per MIG slice. This results in greater peak performance for various workloads on the A30 GPU, especially for AI inference workloads.
CUDA 11.4 is available to download.
CUDA programming model enhancements
This release introduced key enhancements to improve the performance of CUDA Graphs without requiring any modifications to the application or any other user intervention. It also improves the ease of use of Multi-Process Service (MPS). We formalized the asynchronous programming model in the CUDA Programming Guide.
CUDA Graphs
Reducing graph launch latency is a common request from the developer community, especially in applications that have real-time constraints, such as 5G telecom workloads or AI inference workloads. CUDA 11.4 delivers performance improvements in reducing the CUDA graph launch times. In addition, we also integrated the stream-ordered memory allocation feature that was introduced in CUDA 11.2.
For more information, see CUDA Graphs in the CUDA Toolkit Programming Guide and Getting Started with CUDA Graphs.
Performance improvements
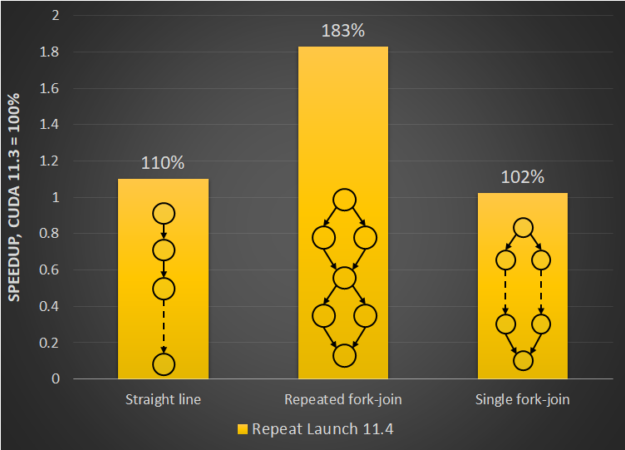
CUDA graphs are ideal for workloads that are executed multiple times, so a key tradeoff in choosing graphs for a workload is amortizing the cost of creating a graph over repeated launches. The higher the number of repetitions or iterations, the larger the performance improvement.
In CUDA 11.4, we made a couple of key changes to CUDA graph internals that further improve the launch performance. CUDA graphs already sidesteps streams to enable lower latency runtime execution. We extended this, to bypass streams even at the launch phase, submitting a graph as a single block of work directly to the hardware. We’ve seen good performance gains from these host improvements, both for single-threaded and multithreaded applications.
Figure 1 shows the relative improvement in launch latency for the re-launch of different graph patterns. There is significant benefit for graphs that have a fork or join pattern.
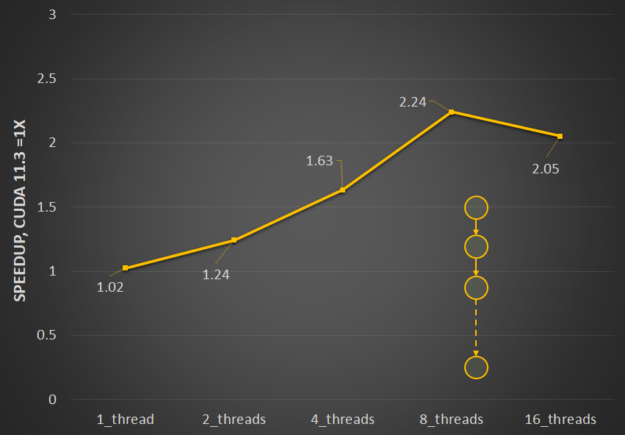
Multithreaded launch performance is particularly affected by the resource contention that happens when launching multiple graphs in parallel. We’ve optimized the interthread locking to reduce contention, and so multithreaded launch is now significantly more efficient. Figure 2 shows the relative performance benefits of the changes in CUDA 11.4 to ease resource contention and how it scales with the number of threads.
Stream-ordered memory allocator support
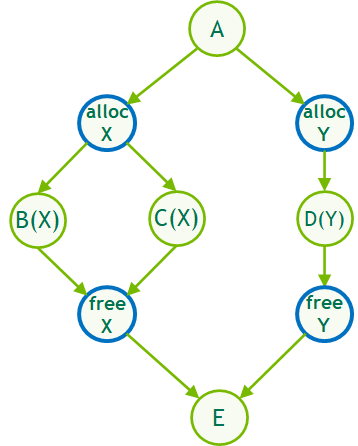
The stream-ordered memory allocator enables applications to order memory allocation and deallocation with respect to other work launched into a CUDA stream. This also enables allocation re-use, which can significantly improve application performance. For more information about the feature and capabilities, see Enhancing Memory Allocation with New NVIDIA CUDA 11.2 Features.
In CUDA 11.4, CUDA Graphs now supports stream-ordered memory allocation both through stream capture or in native graph construction through new allocate and free node types, enabling the same efficient, deferred memory reuse logic within graphs.
These node types are collectively referred to as memory nodes. They can be created in several ways:
- Using the explicit API
- Using
cudaGraphAddMemAllocNodeandcudaGraphAddMemFreeNode, respectively
- Using
- Using stream capture
- Using
cudaMallocAsync/cudaMallocFromPoolAsyncandcudaFreeAsync, respectively
- Using
In the same way that stream-ordered allocation uses implicit stream ordering and event dependencies to reuse memory, graph-ordered allocation uses the dependency information defined by the edges of the graph to do the same.
For more information, see Stream Ordered Memory Allocator.
Enhancements to MPS
The Multi-Process Service (MPS) is a binary-compatible client-server runtime implementation of the CUDA API designed to transparently enable co-operative multiprocess CUDA applications.
It consists of a control daemon process, client runtime, and server process. MPS enables better GPU utilization in cases where a single process does not use all the compute and memory-bandwidth capacity. MPS also reduces on-GPU context storage and context switching. For more information, see Multi-Process Service in the GPU Management and Deployment guide.
In this release, we made a couple of key enhancements to improve the ease of use of MPS.
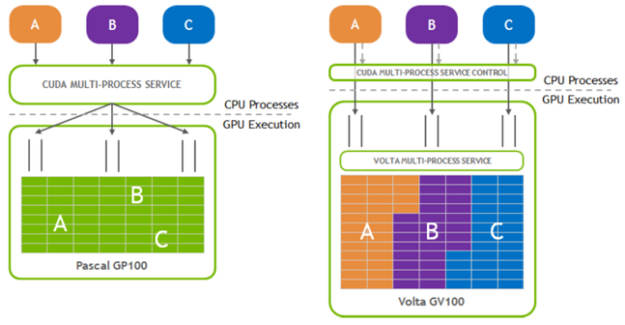
Programmatic configuration of SM partitions
There are certain use cases that share the following characteristics:
- They consist of kernels that have little to no interaction, which enables concurrent execution.
- The ratio of SMs required by these workloads may change and requires flexibility in allocating the right number of SMs.
The MPS active thread percentage setting enables you to limit the execution to a portion of the SMs. Before CUDA 11.4, this was a fixed value that was set equally for all clients within the process. In CUDA 11.4, this has been extended to offer a mechanism to partition the SMs at a per-client level through a programmatic interface. This enables you to create contexts that have different SM partitions within the same application process.
A new resource type called CU_EXEC_AFFINITY_TYPE_SM_COUNT enables you to specify a minimum number N that the context requires. The system guarantees that at least this many SMs are assigned, although more may be reserved. CUDA 11.4 also introduces a related affinity API cuCtxGetExecAffinity, which queries the exact amount of a resource (such as the SM count) allocated for a context. For more information, see the cuCtxGetExecAffinity section in the API documentation.
Error reporting
To improve the error reporting and ease of diagnosing the root cause of MPS issues, we introduced new and detailed driver and runtime error codes. These error codes provide more specificity regarding the type of error. They supplement the common MPS error codes with additional information to help you trace down the cause of the failures. Use these error codes in your applications with the error messages in the server log, as part of the root cause analysis.
New error codes:
CUDA_ERROR_MPS_CONNECTION_FAILED CUDA_ERROR_MPS_SERVER_NOT_READY CUDA_ERROR_MPS_RPC_FAILURE CUDA_ERROR_MPS_MAX_CLIENTS_REACHED CUDA_ERROR_MPS_MAX_CONNECTIONS_REACHED
Formalizing asynchronous data movement
In support of the asynchronous memory transfer operations, enabled by NVIDIA A100 GPU microarchitecture, in CUDA 11.4, we formalized and defined the asynchronous SIMT programming model. The asynchronous programming model defines the behavior and the APIs for C++ 20 barriers and cuda::memcpy_async on the GPU.
For more information about how you can use the asynchronous APIs to overlap memory operations from global memory, with computations in the streaming multiprocessors (SMs), see Asynchronous SIMT Programming Model.
Other enhancements
In addition to the key capabilities listed earlier, there are a few enhancements in CUDA 11.4 geared towards improving the mulit-thread submission throughput and extending the CUDA forward compatibility support to NVIDIA RTX GPUs.
Multithread submission throughput
In 11.4, we reduced the serialization of the CUDA API overheads between CPU threads. These changes are enabled by default. However, to assist with the triage of possible issues because of the underlying changes, we provide an environment variable, CUDA_REDUCE_API_SERIALIZATION, to turn off these changes. This was one of the underlying changes discussed earlier that contributed to the performance improvements for CUDA graphs.
CUDA forward compatibility
To enable use cases where you want to update your CUDA toolkit but stay on your current driver version, for example to reduce the risk or the overhead of additional validation needed to move to a new driver, CUDA offers the CUDA forward compatibility path. This was introduced in CUDA 10.0 but was initially limited to data-center GPUs. CUDA 11.4 eases those restrictions and you can now take advantage of the forward compatibility path for NVIDIA RTX GPUs as well.
C++ language support for CUDA
Here are some key enhancements included with C++ language support in CUDA 11.4.
- Major releases:
- NVIDIA C++ Standard Library (libcu++) 1.5.0 was released with CUDA 11.4.
- Thrust 1.12.0 has the new
thrust::universal_vectorAPI that enables you to use the CUDA unified memory with Thrust.
- Bug fix release: The CUDA 11.4 toolkit release includes CUB 1.12.0.
- New asynchronous
thrust::async:exclusive_scanandinclusive_scanalgorithms have been added, and the synchronous versions of these were updated to usecub::DeviceScandirectly.
CUDA compiler enhancements
CUDA 11.4 NVCC C++ compiler has JIT LTO support in preview, offers more L1 and L2 cache control, and exposes a C++ symbol demangling static library along with NVIDIA Nsight debugger support for alloca.
JIT link time optimization
JIT link-time optimization (LTO) is a preview feature and is available only on CUDA Toolkit 11.4, not on embedded platforms. This feature enables LTO to be performed at runtime. Use NVRTC to generate NVVM IR, and then use the cuLink driver APIs to link the NVVM IR and do LTO.
The following code example shows how runtime JIT LTO can be used in your program.
Generate NVVM IR using nvrtcCompileProgram with the -dlto option and retrieve the generated NVVM IR using the newly introduced nvrtcGetNVVM. Existing cuLink APIs are augmented to take newly introduced JIT LTO options to accept NVVM IR as input and to perform JIT LTO. Pass the CU_JIT_LTO option to cuLinkCreate API to instantiate the linker and then use CU_JIT_INPUT_NVVM as option to cuLinkAddFile or cuLinkAddData API for further linking of NVVM IR.
nvrtcProgram prog1, prog2; CUlinkState linkState; int err; void* cubin; size_t cubinSize; char *nvvmIR1, *nvvmIR2; NVRTC_SAFE_CALL( nvrtcCompileProgram(&prog1, ...); NVRTC_SAFE_CALL( nvrtcCompileProgram(&prog2, ...); const char* opts = (“--gpu-architecture=compute_80”, “--dlto”); nvrtcGetNVVM(prog1, &nvvmIR1); nvrtcGetNVVM(prog1, &nvvmIR2); options[0] = CU_JIT_LTO; values[0] = (void*)&walltime; ... cuLinkCreate(..., options, values, &linkState); err = cuLinkAddData(linkState, CU_JIT_INPUT_NVVM, (void*)nvvmIR1, strlen(nvvmIR1) + 1, ...); ... err = cuLinkAddData(linkState, CU_JIT_INPUT_NVVM, (void*)nvvmIR2, strlen(nvvmIR2) + 1, ...); ... cuLinkComplete(linkState, &cubin, &cubinSize); ...
Libcu++flt library support
The CUDA SDK now ships with libcu++filt, a static library that converts compiler-mangled C++ symbols into user-readable names. The following API, found in the nv_decode.h header file, is the entry point to the library:
char* __cu_demangle(const char* id, char *output_buffer, size_t *length, int *status)
The following C++ example code shows usage:
#include <iostream>
#include "/usr/local/cuda-14.0/bin/nv_decode.h"
using namespace std;
int main(int argc, char **argv)
{
const char* mangled_name = "_ZN6Scope15Func1Enez";
int status = 1;
char* w = __cu_demangle(mangled_name,0,0,&status);
if(status != 0)
cout<<"Demangling failed for: "<<mangled_name<<endl<<"Status: "<<status<<endl;
else
cout<<"Demangling Succeeded: "<<w<<endl;
}
This code example outputs as follows:
Demangling Succeeded: Scope1::Func1(__int128, long double, ...) Demangling Succeeded: Scope1::Func1(__int128, long double, ...)
For more information, see Library Availability in the CUDA Binary Utilities documentation.
Configuring cache behavior in PTX
PTX ISA 7.4 gives you more control over caching behavior of both L1 and L2 caches. The following capabilities are introduced in this PTX ISA version:
- Enhanced data prefetching: The new
.level::prefetch_sizequalifier can be used to prefetch additional data along with memory load or store operations. This enables exploiting the spatial locality of data. - Eviction priority control: PTX ISA 7.4 introduces four cache eviction priorities. These eviction priorities can be specified with the
.level::eviction_priorityqualifier on memory load or store operations (applicable to the L1 cache) and on theprefetchinstruction (applicable to the L2 cache).evict_normal(default)evict_last(useful when the data should be kept in the cache longer)evict_first(useful for streaming data)no_allocate(avoid data from being cached at all)
- Enhanced L2 cache control: This comes in two flavors:
- Cache control on specific addresses: The new discard instruction enables discarding data from cache without writing it back to memory. It should be only used when the data is no longer required. The new
applypriorityinstruction sets the eviction priority of specific data toevict_normal. This is [articularly useful in downgrading the eviction priority fromevict_lastwhen the data no longer needs to be persistent in cache. - Cache-hints on memory operations: The new
createpolicyinstruction enables creating a cache policy descriptor that encodes one or more cache eviction priorities for different data regions. Several memory operations including load, store, asynchronous copy, atom, red, and so on can accept cache policy descriptor as an operand when the.level::cache_hintqualifier is used.
- Cache control on specific addresses: The new discard instruction enables discarding data from cache without writing it back to memory. It should be only used when the data is no longer required. The new
These extensions are treated as performance hints only. The caching behavior specified using these extensions is not guaranteed by the caching system. For more information about usage, see the PTX ISA specification.
Other compiler enhancements in CUDA 11.4 include support for a new host compiler: ICC 2021. The diagnostics emitted by the CUDA frontend compiler are now ANSI colored and Nsight debugger can now correctly unwind CUDA applications with alloca calls, in the Call Stack view.
Nsight Developer Tools
New versions are now available for NVIDIA Nsight Visual Studio Code Edition (VSCE) and Nsight Compute 2021.2, adding enhancements to the developer experience for CUDA programming.
NVIDIA Nsight VSCE is an application development environment for heterogeneous platforms bringing CUDA development for GPUs into Microsoft Visual Studio Code. NVIDIA Nsight VSCE enables you to build and debug GPU kernels and native CPU code in the same session as well as inspect the state of the GPU and memory.
It includes IntelliSense code highlighting for CUDA applications and an integrated GPU debugging experience from the IDE with support for stepping through code, setting breakpoint, and inspecting memory states and system information in CUDA kernels. Now it’s easy to develop and debug CUDA applications directly from Visual Studio Code.
Nsight Compute 2021.2 adds new features that help detect more performance issues and make it easier to understand and fix them. The new register dependency visualization (Figure 6) helps identify long dependency chains and inefficient register usage that can limit performance. This release also adds a frequently requested feature to enable you to view the side-by-side assembly and correlated source code for CUDA kernels in the source view, without needing to collect a profile. This standalone source viewer feature enables you to open .cubin files directly from disk in the GUI to see the code correlation.
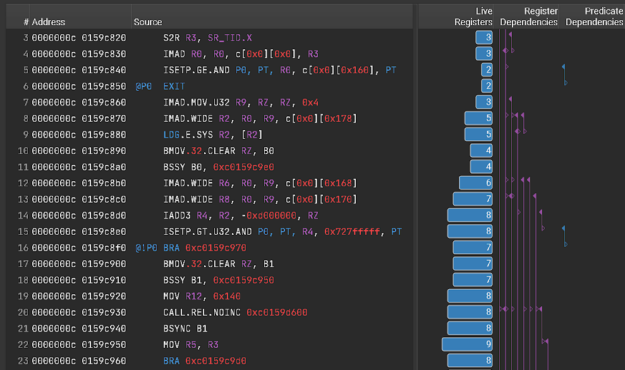
Several features, including highlighted focus metrics, report cross-links, increased rule visibility, and documentation references all add to the built-in profile and optimization guided analysis that Nsight Compute provides to help you understand and fix performance bottlenecks.
This release also includes support for OptiX 7 resource tracking, a new Python interface for reading report data, and improvements to management of baseline reports, font settings, and CLI filters.
For overall updates, see NVIDIA Developer Tools Overview. Download the tools to your code.
For more information about the CUDA 11 generation toolkit capabilities and introductions, see CUDA 11 Features Revealed and follow all CUDA posts.
Acknowledgements
Thanks to the following key contributors: Stephen Jones, Arthy Sundaram, Fred Oh, and Sally Stevenson.
