

As a researcher building state-of-the-art speech and language models, you must be able to quickly experiment with novel network architectures. This experimentation may focus on modifying existing network architectures to improve performance, or it may be higher-level experimentation in which speech and language models are combined to build end-to-end applications.
A typical starting point for this type of work involves looking at example code and pretrained models from model zoos. However, reusing code and pretrained models this way can be tricky.
The inputs and outputs, coding style, and data processing layers in these models may not be compatible with each other. Worse still, you may be able to wire up these models in your code in such a way that it technically “works” but is in fact semantically wrong. A lot of time, effort, and duplicated code goes into making sure that you are reusing models safely.
As model complexity and model reuse increases, this approach becomes unsustainable.
Now compare this with how you build complex software applications. Here, the history is one of increasing levels of abstraction: from machine code to assembly languages, on to structured programming with compilers and type systems, and finally to object-oriented programming. With these higher-level tools come better guardrails and better code reuse.
Deep learning libraries have been going through a similar evolution.Low-level tools such as CUDA and cuDNN provide great performance, and TensorFlow provides great flexibility at the cost of human effort. However, tensors and simple operations and layers are still the central objects of high-level libraries, such as Keras and PyTorch.
Introducing NVIDIA NeMo
NVIDIA NeMo is an open-source toolkit with a PyTorch backend that pushes the abstractions one step further. NeMo makes it possible for you to quickly compose and train complex, state-of-the-art, neural network architectures with three lines of code. The NeMo model is composed of reusable components, Neural Modules, which are the building blocks of NeMo models.
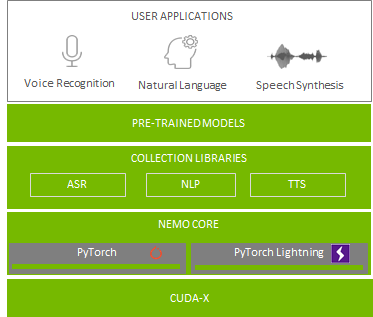
At the heart of the toolkit is the concept of a neural module. A neural module takes a set of inputs and computes a set of outputs. It can be thought of as an abstraction that’s somewhere between a layer and a full neural network. Typically, a module corresponds to a conceptual piece of a neural network, such as an encoder, decoder, or language model.
A neural module’s inputs and outputs have a neural type, which includes the semantics, axis order, and dimensions of the input/output tensor. This typing ensures safety semantic checks between the modules in NeMo models.
NeMo also comes with an extendable collection of models for ASR, NLP, and TTS. These collections provide methods to easily build state-of-the-art network architectures such as QuartzNet, BERT, Tacotron 2, and WaveGlow. With NeMo, you can also fine-tune these models on a custom dataset by automatically downloading and instantiating them from NVIDIA NGC with a readily available API.
Under the hood, the NeMo models are built on top of PyTorch and PyTorch Lightning, providing an easy path for researchers to integrate and develop with modules with which they are already comfortable. The integration with PyTorch Lightning also allows you to quickly invoke training actions with the trainer API. It enables NeMo models to use mixed-precision compute to get the highest performance possible using Tensor Cores on NVIDIA GPUs and allows scaling training to multi-GPU systems and multi-node clusters with a few lines of code.
This toolkit arose out of the challenges faced by the Applied Research team. By open-sourcing this work, NVIDIA hopes to share its benefits with the broader community of speech, NLP, and TTS researchers and encourage collaboration.
Building a new model
Build a simple ASR model to see how to use NeMo. You also see how the model can be developed in three lines of code, how you can easily tune hyperparameters using config files, and how the tool can scale out to multiple GPUs with minimal effort.
Getting started
The NVIDIA/NeMo GitHub repo outlines the general requirements and installation instructions. The repo shows NeMo installation in several ways:
- Using an NGC container.
- Using the package manager (pip) command:
pip install nemo_toolkit_[all/asr/nlp/tts]. The package manager allows you to install individual NeMo packages based on the collection that you specify, such as asr, nlp, or tts. - Using a Dockerfile that can be used to build a Docker image with a ready-to-run NeMo installation.
Use the Introduction to End-To-End Automatic Speech Recognition example Jupyter notebook to see how to set up the environment using the pip command and to train the QuartzNetASR model in NeMo.
QuartzNet
For this ASR example, you use a network called QuartzNet. QuartzNet is a variant of Jasper with fewer parameters that uses 1D time-channel separable convolutions instead of 1D convolutions from Jasper. It can transcribe speech samples without any additional alignment information. For more information, see QuartzNet: Deep Automatic Speech Recognition With 1D Time-Channel Separable Convolutions (PDF).
The training pipeline for this model consists of the following blocks. Each of these logical blocks corresponds to a neural module.

Jupyter notebook
The steps of model building in the Jupyter notebook are as follows:
- Instantiate the ASR model with a config.yaml file.
- Instantiate the model based on the configuration file.
- Invoke an action, for example, train.
The steps are few because you’re working with higher levels of abstraction.
For an ASR introduction and to explore step-by step-procedures, see the Introduction to End-To-End Automatic Speech Recognition Jupyter notebook.
Fine-tuning models on custom datasets
Fine-tuning plays an important role in building highly accurate models on custom datasets using pretrained models. It is a technique to perform transfer learning. Transfer learning transfers the knowledge gained in one task to perform another similar task. There are several pretrained models available in NGC that are a starting point to fine-tune your use case using NeMo. NeMo also has a ready-to-use API that automatically goes to NGC to download and instantiate model weights.
NeMo has the capability to export models to NVIDIA Riva. It exports in several formats: NeMo, PyTorch, PyTorch Lightning, TorchScript, or ONNX. To deploy these formats to Riva, you must apply TensorRT optimizations, generate a TensorRT engine, configure Triton Inference Server, and create a gRPC API for high-performance inference.
Pretrained models in NGC
Several pretrained models in NGC are available for ASR, NLP, and TTS such as Jasper, QuartzNet, CitriNet, BERT and Tacotron2, and WaveGlow. These models are trained on thousands of hours of open source data to get high accuracy, and are trained over 100K hours on DGX systems.
Multiple open source and commercial datasets are used to build these pretrained models, such as LibriSpeech, Mozilla Common Voice, AI-shell2 Mandarin Chinese, Wikipedia, BookCorpus, and LJSpeech. The datasets help models to gain a deep understanding of the context so they can perform effectively in real-time use cases.
All the pretrained models are downloadable, and the model code is open source, so you can train models on your own dataset or even build new models from the base architecture with NeMo.
For more information, see the following resources:
- Develop Smaller Speech Recognition Models with the NVIDIA NeMo Framework
- How to Build Domain-Specific Automatic Speech Recognition Models on GPUs
- NGC model repository (pretrained models)
- NeMo notebook tutorials (GitHub)
- Introduction to Building Conversational AI Apps for Enterprise (webinar)
- NVIDIA NeMo: Developing State-Of-The-Art Conversational AI Models in Three Lines Of Code (video)
