
NVIDIA NeMo, an end-to-end platform for the development of multimodal generative AI models at scale anywhere—on any cloud and on-premises—released the Parakeet family of automatic speech recognition (ASR) models. These state-of-the-art ASR models, developed in collaboration with Suno.ai, transcribe spoken English with exceptional accuracy.
This post details Parakeet ASR models that are breaking new ground in speech recognition.
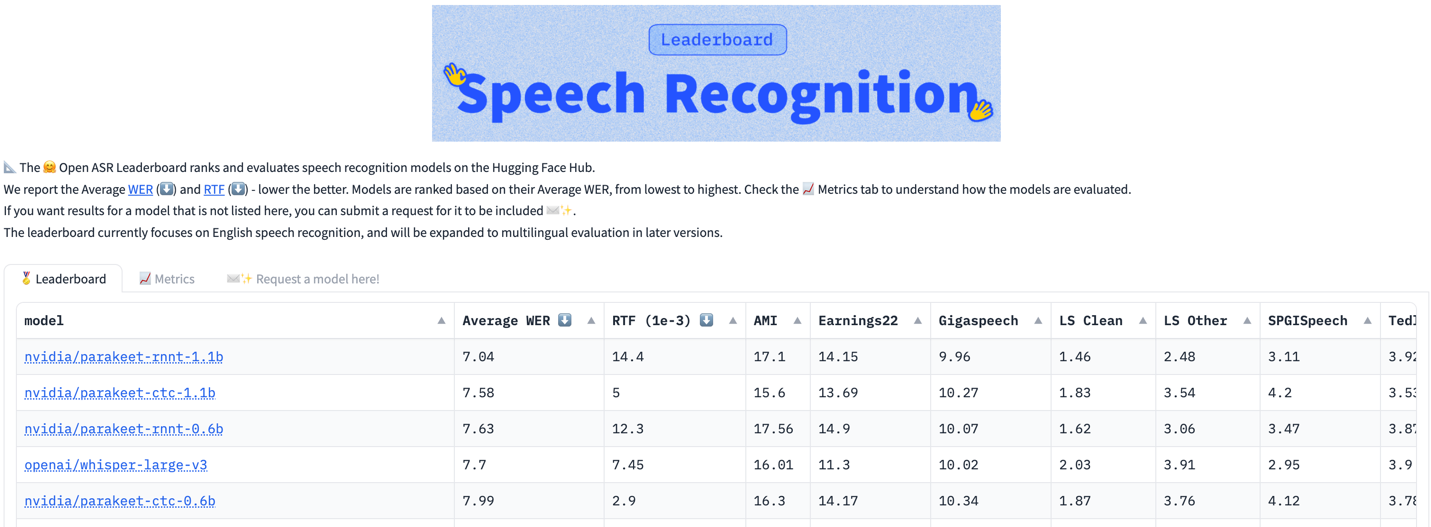
Introducing the Parakeet ASR family
Four released Parakeet models are based on recurrent neural network transducer (RNNT) or connectionist temporal classification (CTC) decoders. They boast 0.6B and 1.1B parameters and tackle diverse audio environments exhibiting resilience against non-speech segments, including music and silence.
Trained on an extensive public and proprietary 64,000-hour dataset, these models demonstrate exceptional accuracy for a wide array of accents and dialects, vocal ranges, and diverse domains and noise conditions.
| Model | Accuracy / Speed Trade-Off | Use Case |
| Parakeet CTC 1.1B Parakeet CTC 0.6B |
|
|
| Parakeet RNNT 1.1B Parakeet RNNT 0.6B |
|
|
Benefits of using Parakeet ASR models
Built using the NeMo framework, Parakeet models prioritize user-friendliness and flexibility. Pretrained checkpoints are readily available, so integrating these models into projects is easy. They can be immediately deployed as-is, or further fine-tuned for specific tasks.
Here are the key benefits of Parakeet models:
- State-of-the-art accuracy: Superior word error rate (WER) accuracy across diverse audio sources and domains with strong robustness to non-speech segments.
- Open-source and extensibility: Seamless integration and customization.
- Pretrained checkpoints: Ready-to-use for inference or further fine-tuning.
- Different model sizes: 0.6B– and 1.1B-parameter model sizes for robust comprehension of complex speech patterns.
- Permissive license: Released under a CC-BY-4.0 license, model checkpoints can be used in any commercial application.
Try the parakeet-rnnt-1.1B model firsthand inside the Gradio demo. To access the model locally and explore the toolkit, see the NVIDIA/NeMo GitHub repo.
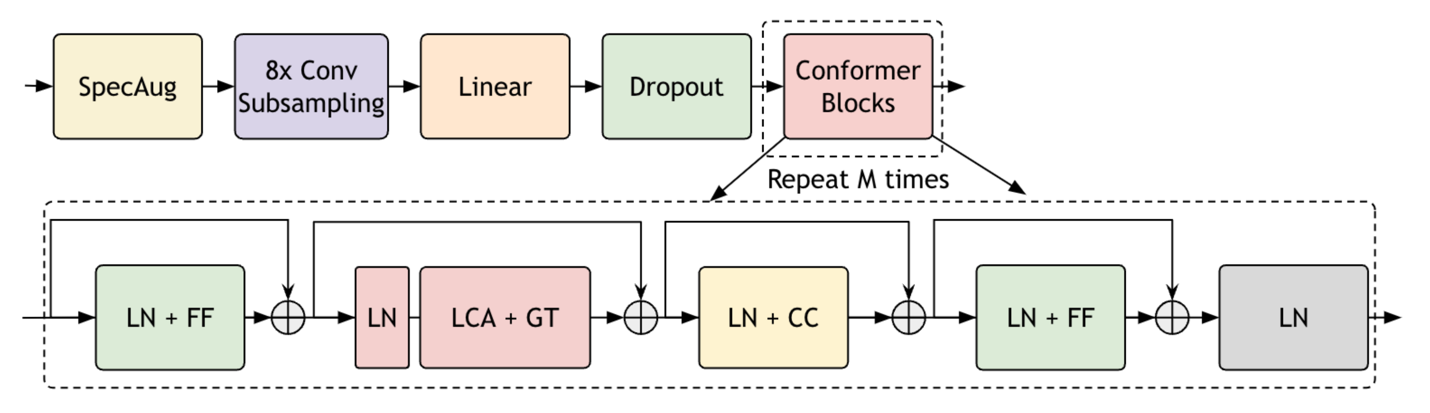
Diving into the Parakeet architecture
Parakeet models are based on Fast Conformer, an optimized version of the conformer model with 8x depthwise-separable convolutional downsampling, modified convolution kernel size, and an efficient subsampling module.
The Parakeet architecture is designed to support inference on long audio segments, up to 11 hours of speech, on an NVIDIA A100 GPU 80GB card using local attention. The model is trained end-to-end using an RNNT or CTC decoder.
For more information about long audio inference, see the ICASSP 2024 paper, Investigating End-to-End ASR Architectures for Long Form Audio Transcription.
Parakeet FC-based models excel in both inference and training speed, seamlessly navigating memory constraints. Generally, models will often have different real-time factor (RTF) scores under different inference scenarios.
We normally measure RTF on an entire dataset, composed of different audio files with some fixed batch size. In this case, we compute RTF as the time taken by the ASR system to transcribe a single audio clip divided by the total duration of the spoken audio by Parakeet models of various sizes. In this scenario, we measure the speed of the model to transcribe a long audio file, one that generally cannot be processed by attention models due to their quadratic compute complexity with respect to the audio length.
Table 2 shows RTF and the maximum duration of input audio for inference on an NVIDIA A100 80GB card in one single pass.
| Parakeet Size | Max Duration of Audio with Full Attention [minutes] | RTF 30-sec audio (RNNT) | RTF 30-sec audio (CTC) | Max Duration with Limited Context [hours] |
| 120M | 30 | 11.8e-3 | 1.5e-3 | 14 |
| 0.6B | 30 | 13.3e-3 | 2.0e-3 | 13 |
| 1.1B | 30 | 14.6e-3 | 3.4e-3 | 12.5 |
With limited context attention, even the largest model can infer up to 13 hrs of audio in one single pass.
The Parakeet model with 1B parameters can process 12.5 hours of audio in a single pass, while the medium size (0.6B) model can handle 13 hours. CTC models excel in inference speed, with a CTC RTF of 2e-3 for a 30-second audio, making them ideal for transcribing meeting audio.
FastConformer with limited context attention and fine-tuning using a global token achieves superior accuracies even on extensive long-form audio datasets (Table 3).
| Model | TED-LIUM3 | Earnings21 | Earnings22 | CORAAL |
| FC with Limited Context Attention | 5.88 | 17.08 | 24.67 | 37.35 |
| + Fine-Tuning | 5.08 | 14.82 | 20.44 | 30.28 |
| + Global Token | 4.98 | 13.84 | 19.49 | 28.75 |
How to use Parakeet models
To use the Parakeet models, install NeMo as a pip package. Install Cython and PyTorch (2.0 and later) before installing NeMo. Then, install NeMo as a pip package:
pip install nemo_toolkit['asr']
After NeMo is installed, evaluate a list of audio files:
import nemo.collections.asr as nemo_asr
asr_model = nemo_asr.models.ASRModel.from_pretrained(model_name="nvidia/parakeet-rnnt-1.1b")
transcript = asr_model.transcribe(["some_audio_file.wav"])
Parakeet models for long-form speech inference
After a Fast Conformer model is loaded, you can easily modify the attention type to limited context attention after building the model. You can also apply audio chunking for the subsampling module to perform inference on huge audio files.
These models were trained with global attention, and switching to local attention degrades their performance. However, they can still transcribe long audio files reasonably well.
For limited context attention on huge files (up to 11 hours on an A100 GPU), perform the following steps:
# Enable local attention
asr_model.change_attention_model("rel_pos_local_attn", [128, 128]) # local attn
# Enable chunking for subsampling module
asr_model.change_subsampling_conv_chunking_factor(1) # 1 = auto select
# Transcribe a huge audio file
asr_model.transcribe(["<path to a huge audio file>.wav"]) # 10+ hours!
You can fine-tune Parakeet models for other languages on your own datasets. Below are some helpful tutorials:
- Finetuning on data in NeMo manifest format: ASR CTC language finetuning tutorial
- Finetuning on data in Hugging Face datasets format: ASR with Transducer Models using HF Datasets tutorial.
Conclusion
NeMo Parakeet models advance English transcription accuracy and performance, offering businesses and developers a spectrum of options for real-world applications with diverse speech patterns and noise levels.
For more information about the architecture behind Parakeet ASR models, see Fast Conformer with Linearly Scalable Attention for Efficient Speech Recognition and End-to-End ASR Architecture for Long-Form Audio Transcription.
From the latest NeMo ASR models, Parakeet-CTC is available now. Other models will be available soon as part of NVIDIA Riva. Try the Parakeet-RNNT-1.1B firsthand in the Gradio demo and access the model locally on the /NVIDIA/NeMo GitHub repo.
Experience speech and translation AI models through the NVIDIA API catalog and run them on-premises with NVIDIA NIM. NVIDIA LaunchPad provides the necessary hardware and software stacks on private hosted infrastructure for additional exploration.