

As a researcher building state-of-the-art conversational AI models, you need to be able to quickly experiment with novel network architectures. This experimentation may focus on modifying existing network architectures to improve performance, or it may be higher-level experimentation in which speech and language models are combined to build end-to-end applications.
A typical starting point for this type of work involves looking at example code and pre-trained models from model zoos — but reusing code and pre-trained models this way can be quite tricky.
The inputs and outputs, the coding style, and the data processing layers in these models may not be compatible with each other. Worse still, you may be able to wire up these models in your code in such a way that it technically “works”, but is in fact semantically wrong. So a lot of time, effort and duplicated code goes into making sure you are reusing models safely.
As model complexity and model reuse increases, this approach becomes unsustainable.
Now let’s compare this with how we build complex software applications. Here, the history is one of increasing levels of abstraction: from machine code to assembly languages, to structured programming with compilers and type systems, and finally object oriented programming. With these higher-level tools came better guardrails and better code reuse.
Deep learning libraries have been going through a similar evolution, from low-level tools such as CUDA and cuDNN which provide great performance, to TensorFlow that provides great flexibility but at the cost of human effort, to higher-level tools like Keras. However, tensors and simple operations/layers are still the central objects of high-level libraries such as Keras and PyTorch.
Introducing Neural Modules Toolkit
Neural Modules is a new open source toolkit that pushes these abstractions one step further, making it possible to easily and safely compose complex neural network architectures using reusable components. Neural Modules is also built for speed. It can scale out training to multiple GPUs and multiple nodes. It can also take advantage of mixed-precision to speed up training even further. It currently supports a PyTorch backend and can be extended to support other backends.

At the heart of the toolkit is the concept of a Neural Module. A Neural Module takes a set of inputs and computes a set of outputs. It can be thought of as an abstraction that’s somewhere between a layer and a full neural network. Typically, a module corresponds to a conceptual piece of a neural network, such as: an encoder, a decoder, a language model, an acoustic model, etc.
A Neural Module’s inputs/outputs have a Neural Type, that describes the semantics, the axis order, and the dimensions of the input/output tensor. This typing allows Neural Modules to be safely chained together to build applications, as in the ASR example below.
Neural Modules toolkit also comes with an extendable collection of modules for ASR and NLP. These collections provide APIs for data loading, preprocessing and training different network architectures, like Jasper and BERT. They also include pretrained models for transfer learning. We plan to expand these collections into other domains like computer vision and text to speech, as well as tools for sensor fusion.
This toolkit arose out of the challenges faced by our NVIDIA Applied Research team. By open sourcing this work, we hope to share its benefits with the broader community of Speech and NLP researchers and encourage collaboration.
In Action
Let’s build a simple ASR model to see how it’s very easy using Neural Modules. You will get to see how Neural Types provide semantic safety checks, and how the tool can scale out to multiple GPUs with minimal effort.
Getting Started
The GitHub repo outlines general requirements and installation instructions. The repository also contains a Dockerfile that can be used to build a Docker image with a ready-to-run Neural Modules installation. We will use this Dockerfile and an example Jupyter notebook to demonstrate training the Jasper ASR model.
To set up this environment, first clone Neural Modules:
git clone https://github.com/NVIDIA/NeMo.git
Next, download a dataset for training. We will keep this dataset outside the NeMo tree to avoid a huge Docker build context. In this example, we use $HOME/nemo-data/LibriSpeech. Adjust your path as needed.
cd NeMo
mkdir -p $HOME/nemo-data/LibriSpeech
python scripts/get_librispeech_data.py \
--data_root=$HOME/nemo-data/LibriSpeech \
--data_set=dev_clean,train_clean_100
# This downloads 26GB of data... plenty of time for a coffee
Now build the Docker image:
docker build -t nemo-demo .
And then run the container, mapping in the data directory used above. For example:
docker run --runtime=nvidia --rm -it --ipc=host \
-v $HOME/nemo-data/LibriSpeech:/workspace/nemo/data \
nemo-demo
Once inside the running Docker container, use the start-jupyter.sh script to start JupyterLab. Open the JupyterLab web interface in your browser and launch the examples/asr/NeMo-ASR-Tutorial-blog.ipynb notebook to get started.
Jasper
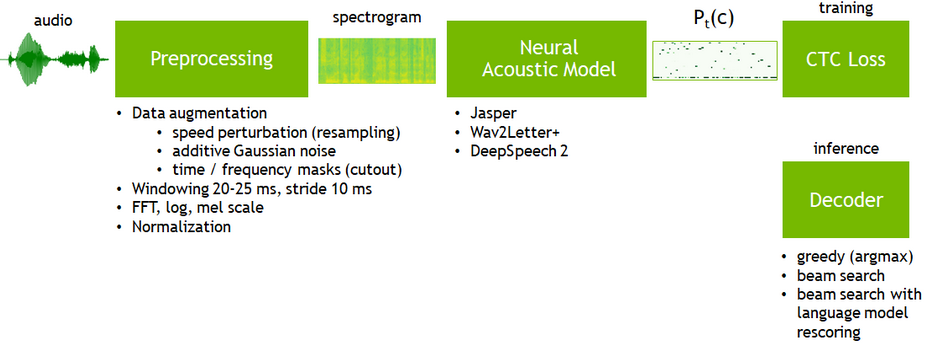
We’ll be using a network called Jasper for this ASR example. Jasper is an end-to-end ASR model, which means it can transcribe speech samples without any additional alignment information.
The training pipeline for this model consists of the following blocks. Each of these logical blocks corresponds to a neural module.
Jupyter Notebook
The overall structure of this model looks like this:

As you can see, it’s fairly simple because we’re working with higher-levels of abstraction.
You can follow the steps in the Jupyter notebook to explore this example, including training the Jasper model as well as enabling mixed precision and multi-GPU training.
Wrapping Up
We’re excited about how this modular approach to deep learning can improve the productivity of its practitioners. We’ve just started this journey, and plan to have monthly releases with new functionality.
Check out our GitHub repo for more info, and we would love to hear your feedback!