As computers and other personal devices have become increasingly prevalent, interest in conversational AI has grown due to its multitude of potential applications in a variety of situations. Each conversational AI framework is comprised of several more basic modules such as automatic speech recognition (ASR), and the models for these need to be lightweight in order to be effectively deployed on the edge, where most of the devices are smaller and have less memory and processing power. However, most state-of-the-art (SOTA) ASR models are extremely large — they tend to have on the order of a few hundred million parameters. This makes them hard to deploy on a large scale given current limitations of devices on the edge.
To tackle this problem, NVIDIA is releasing QuartzNet, a new end-to-end neural ASR model architecture based on Jasper that is smaller than all other competing models.
The largest of the QuartzNet models has just under 19 million parameters, and achieves near SOTA accuracy on ASR benchmarks such as the LibriSpeech test-clean dataset, which has a 2.6% word error rate (WER) using Transformer-XL rescoring. QuartzNet also shows good transfer learning capability, and can be fine-tuned from a checkpoint on a smaller dataset to achieve good accuracy on more domain-specific speech. The model was initially designed by Samuel Kriman (from University of Illinois Urbana-Champaign) during his summer internship at NVIDIA.
Model Architecture
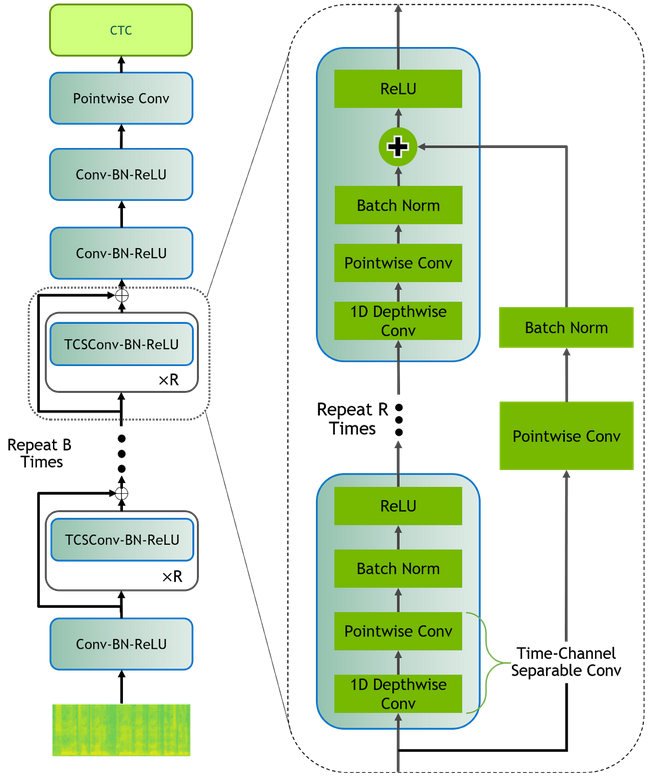
QuartzNet is derived from the Jasper architecture, and both are convolutional models composed of blocks of convolutions, batch normalization, ReLU, and dropout, followed by CTC loss. However, QuartzNet replaces Jasper’s 1D convolutions with 1D time-channel separable convolutions, which use many fewer parameters. This means that convolutional kernels can be made much larger, and the network can be made much deeper, without having too large of an impact on the total number of parameters in the model. For more details about the architecture and the separable convolutions, you can read the entire paper.
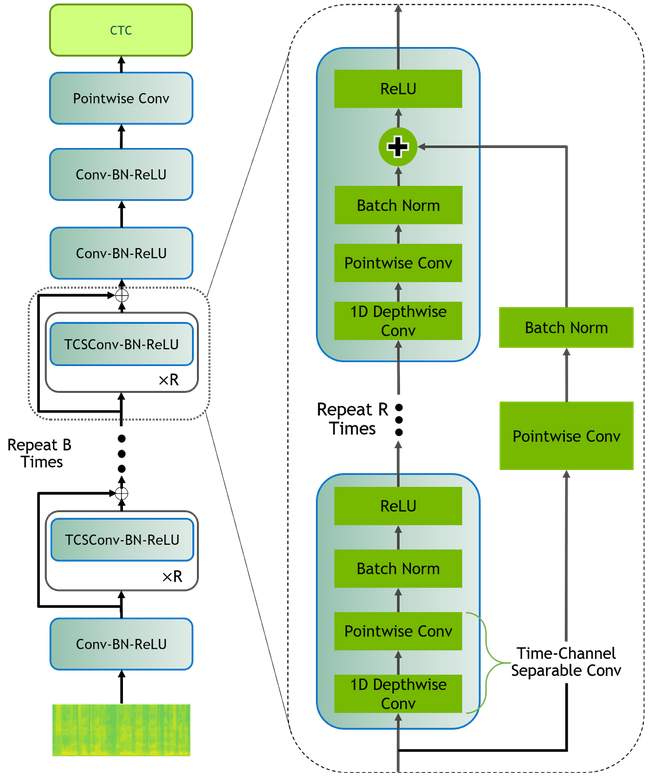
The largest QuartzNet model, QuartzNet-15×5, consists of 79 layers and has a total of 18.9 million parameters, with five blocks that repeat fifteen times plus four additional convolutional layers. The smallest model, QuartzNet-5×3, has only 19 layers and 6.4 million parameters, with one block repeated six times and another repeated nine times, along with the four additional convolutional layers.
Results
Using Neural Modules (NeMo), a toolkit released by NVIDIA in late September 2019, we trained this model on LibriSpeech dataset. The modular approach and flexibility of defining model components as building blocks helped speed up the process of experimentation. The nemo_asr package contains all the necessary neural modules for defining the training and inference pipeline.
With NeMo, simply:
- Instantiate the neural modules that comprise the model and pipeline
- Describe a DAG (directed acyclic graph) of modules; their connections; how data flows from input to output
- Call the train action to start training the model
The QuartzNet-15×5 model was trained on the LibriSpeech training dataset with two types of data augmentation: speed perturbation and Cutout. For the former, 10% speed perturbation was used, meaning that additional training samples were created by slowing down or speeding up the original audio data by 10%. Cutout refers to randomly masking out small rectangles out of the spectrogram input as a regularization technique.
The model was validated on LibriSpeech’s dev-clean and dev-other datasets, and evaluated on the test-clean and test-other datasets. The table below shows the results compared to other SOTA models, as well as the number of parameters in each.
| Model | Augmentation | Language Model | test-clean WER (%) | test-other WER (%) | # Parameters, in millions |
| wav2letter++ | Speed Perturb | ConvLM | 3.26 | 10.47 | 208 |
| LAS | SpecAugment | RNN | 2.5 | 5.8 | 360 |
| Time-Depth Separable Convolutions | Dropout, Label Smoothing |
N/A (greedy)
4-gram ConvLM |
5.36
4.21 3.28 |
15.64
11.87 9.84 |
37 |
| Multi-Stream Self-Attention | Speed Perturb | 4-gram
4-LSTM |
2.93
2.20 |
8.32
5.82 |
23 |
| JasperDR-10×5 | SpecAugment,
Speed Perturb |
N/A (greedy)
6-gram Transformer-XL |
4.32
3.24 2.84 |
11.82
8.76 7.84 |
333 |
| QuartzNet-15×5 | SpecCutout,
Speed Perturb |
N/A (greedy)
6-gram Transformer-XL |
3.90
2.96 2.69 |
11.28
8.07 7.25 |
19 |
Quartznet-15×5 was also trained on DGX-2 SuperPods and DGX-1 SuperPods with Amp mixed-precision. When trained on the LibriSpeech dataset with a global batch of 16K, scaling up to 32 DGX-2 nodes (512xGPUs total) resulted in 16 iterations per epoch. With synchronized batch normalization, training to a similar accuracy to the single-node result above took only four hours and 13 minutes, and training longer further decreased the WER.
In comparison, the single-node QuartzNet-15×5 experiment was trained on a single DGX-1 server with 8xV100 GPUs, and took nearly five days. Below is a table of different multi-node training configurations and their greedy decoding results, with single-node as a baseline in the first row.
| GPUs | Batch Size | Epochs | Time (h) | test-clean WER (%) | test-other WER (%) | dev-clean WER (%) | dev-other WER (%) |
| 1×8 | 32 | 400 | 122 | 3.90 | 11.28 | 3.8 | 11.1 |
| 32×8 | 4K | 1500 | 11.6 | 3.92 | 10.99 | 3.6 | 11.1 |
| 16×16 | 8K | 1500 | 7.9 | 3.93 | 10.82 | 3.5 | 11.3 |
| 32×16 | 16K | 1500 | 4.2 | 4.04 | 11.07 | 3.7 | 10.8 |
QuartzNet-5×3 with dropout was evaluated on the Wall Street Journal dataset, and a comparison of the results with other end-to-end models trained on standard speech features can be seen in the table below:
| Model | Language Model | 93-test WER (%) | 92-eval WER (%) | # Params, M |
| RNN-CTC | 3-gram | – | 8.7 | 26.5 |
| ResCNN-LAS | 3-gram | 9.7 | 6.7 | 6.6 |
| Wav2Letter++ | 4-gram
convLM |
9.5
7.5 |
5.6
4.1 |
17 |
| QuartzNet-5×3 | 4-gram
Transformer-XL |
8.1
7.0 |
5.8
4.5 |
6.4 |
QuartzNet-15×5 also performed well in a transfer learning experiment, demonstrating the capacity to generalize to data from different sources. In this experiment, the model was first pre-trained on the LibriSpeech and Common Voice datasets, then fine-tuned on the much smaller Wall Street Journal dataset. The following table shows the WER achieved on the LibriSpeech evaluation datasets prior to fine-tuning, and the corresponding WER on the Wall Street Journal results after fine-tuning, with various language model rescoring methods.
| Language Model | LibriSpeech test-clean WER (%) | LibriSpeech test-other WER (%) | WSJ
93-test WER (%) |
WSJ
92-eval WER (%) |
| N/A (greedy) | 4.19 | 10.98 | 8.97 | 6.37 |
| 4-gram | 3.21 | 8.04 | 5.57 | 3.51 |
| Transformer-XL | 2.96 | 7.53 | 4.82 | 2.99 |
The code for QuartzNet is open source, and is available on GitHub in the NeMo (Neural Modules) repository. With NeMo, you can try training QuartzNet from scratch, or fine-tuning a pre-trained checkpoint from NGC on your own data.
References
- DeVries 2017. “Improved Regularization of Convolutional Neural Networks with Cutout” Terrance DeVries, Graham W. Taylor
- Ko et al 2015. “Audio Augmentation for Speech Recognition” Tom Ko, Vijayaditya Peddinti, Daniel Povey, Sanjeev Khudanpur
- Kriman et al 2019. “QuartzNet: Deep Automatic Speech Recognition with 1D Time-Channel Separable Convolutions” Samuel Kriman, Stanislav Beliaev, Boris Ginsburg, Jocelyn Huang, Oleksii Kuchaiev, Vitaly Lavrukhin, Ryan Leary, Jason Li, Yang Zhang
- Li et al 2019. “Jasper: An End-to-End Convolutional Neural Acoustic Model” Jason Li, Vitaly Lavrukhin, Boris Ginsburg, Ryan Leary, Oleksii Kuchaiev, Jonathan M. Cohen, Huyen Nguyen, Ravi Teja Gadde
Additional Resources
- End-to-End NeMo ASR Tutorial (Jupyter notebook)
- Neural Modules Toolkit on Github
- Pretrained models available on NGC