As speech recognition applications become mainstream and get deployed through devices in the home, car, and office, research from academia and industry for this space has exploded. To present their latest work, global AI leaders and developers, including NVIDIA researchers, will come together in Austria next week to discuss the latest automatic speech recognition (ASR) breakthroughs, at the annual Interspeech Conference.
Interspeech is the world‘s largest and most comprehensive conference on the science and technology of spoken language processing.
Speech applications are compute intensive and require a powerful and flexible platform with hardware and software. Today GPUs are the most popular solution available for performing speech based research. Today, in conjunction with the conference, NVIDIA is announcing several models developed to advance research in this field.
Introducing NVIDIA Neural Modules
Neural Modules is an open source toolkit that makes it possible to easily and safely compose complex neural network architectures using reusable components.
Neural Modules is the platform that allows developers to build new state of the art speech and natural language processing networks easily through API Compatible modules. This platform provides collections to quickly get started with application development. It is being released as open source so users can extend and contribute collections back to the platform.
Neural Modules lets users define a model as an arbitrary directed acyclic graph composed of Modules that are defined with input and output types; checking semantic compatibility. This is different than the OpenSeq2Seq framework where the responsibility of checking types is up to the user. Also, it is inherently framework agnostic by design although first release is based on PyTorch.
To help you get started with Neural Modules, we’ve published a technical how-to blog, with step-by-step instructions on how to build your own automatic speech recognition (ASR) model using Neural Modules.
We are encouraging contributions to the toolkit. Neural Modules toolkit will play a major role in NVIDIA’s recently announced partnership with Mila on the new SpeechBrain Project. Early adopters such as Dessa, Kensho Technologies and Optum have also said they are excited about this launch and looking forward to collaboration.
Download Neural Modules from GitHub
Announcing Jasper ASR Model
NVIDIA is also releasing Jasper (Just Another Speech Recognizer), an ASR model comprised of 54 layers that can achieve sub 3 percent word error rate (WER) on the LibriSpeech dataset.
This speech recognition pipeline can be separated into 4 major components: an audio feature extractor and preprocessor, the Jasper neural network, a beam search decoder and a post rescorer, as illustrated below.
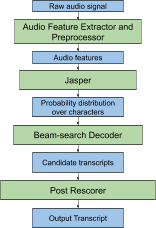
Main components of the Jasper-based speech recognition pipeline
Jasper is very deep convolutional models composed from 1D -convolutions, batch normalization, ReLU, and dropout layers. Jasper has a block architecture: a Jasper BxR model has B blocks, each with R sub-blocks. Each sub-block applies the following operations: a 1D- convolution, batch norm, ReLU, and dropout. All sub-blocks in a block have the same number of output channels. Each block input is connected directly into the last sub- block via a residual connection. The residual connection is first projected through a 1×1 convolution to account for different numbers of input and output channels, then through a batch norm layer. The output of this batch norm layer is added to the output of the batch norm layer in the last sub-block. The result of this sum is passed through the activation function and dropout to produce the output of the current block.

Following table shows the results of experiments on LibriSpeech dataset:

Learn More: https://arxiv.org/pdf/1904.03288.pdf
Summary
These projects and new models reaffirm NVIDIA’s commitment to building tools that allow developers to build state of the art applications.
If you are planning to attend the conference, take a look at these other papers and conference sessions to learn more about building speech applications with NVIDIA GPUs:
Jasper: An End-to-End Convolutional Neural Acoustic Model
Oral; Monday, 1200–1220
Using Attention Networks and Adversarial Augmentation for Styrian Dialect Continuous Sleepiness and Baby Sound Recognition
Oral; Wednesday, 1039–1047
