
오늘날 GPU 애플리케이션을 가속할 수 있는 주요 방법은 컴파일러 지시문, 프로그래밍 언어, 프로그래밍된 라이브러리 등 세 가지가 있습니다. OpenACC 같은 컴파일러 지시문은 GPU에 대한 코드 이식이 쉽다 보니 지시문 기반 프로그래밍 모델을 이용해 가속하는 데 사용됩니다. 지시문은 사용이 쉽지만 일부 시나리오에서는 최적의 성능을 제공하지 못할 수도 있습니다.
CUDA C, C++ 같은 프로그래밍 언어는 애플리케이션 가속 시 뛰어난 유연성을 발휘하지만 사용자가 최신 하드웨어에서 새로운 기능을 이용해 성능을 최적화하려면 직접 코드를 작성해야 합니다. 이러한 단점을 해결할 수 있는 것이 바로 프로그래밍된 라이브러리입니다.
NVIDIA Math 라이브러리는 코드를 재사용할 수 있는 능력이 우수할 뿐만 아니라 GPU 하드웨어에 최적화되어 성능까지 극대화할 수 있습니다. 애플리케이션을 손쉽게 가속할 수 있는 방법을 찾고 있다면 이 블로그를 읽으면서 라이브러리를 사용해 애플리케이션 성능을 높일 수 있는 방법에 대해 자세히 알아보세요.
CUDA Toolkit와 고성능 컴퓨팅(HPC) 소프트웨어 개발 키트(SDK)에서 기본적으로 제공되는 NVIDIA Math 라이브러리는 광범위한 컴퓨팅 집약적 응용 분야에서 볼 수 있는 품질 높은 함수 구현체를 제공합니다. 해당 응용 분야로는 머신 러닝, 딥 러닝, 분자 동역학, 전산 유체 역학(CFD), 계산 화학, 의료 영상 처리, 지진 탐광 등이 있습니다.
이러한 라이브러리는 OpenBLAS, LAPACK, Intel MKL 같은 일반 CPU 라이브러리를 대체할 뿐만 아니라 최소한의 코드 변경만으로 NVIDIA GPU를 통해 애플리케이션을 가속할 수 있도록 설계되었습니다. 우리는 이러한 과정을 알 수 있도록 DGEMM(Double Precision General Matrix Multiplication) 함수 예제를 작성하여 cuBLAS와 OpenBLAS의 성능을 비교했습니다.
아래 코드 예제는 OpenBLAS DGEMM 호출을 어떻게 사용하는지 보여줍니다.
// Init Data
…
// Execute GEMM
cblas_dgemm(CblasColMajor, CblasNoTrans, CblasTrans, m, n, k, alpha, A.data(), lda, B.data(), ldb, beta, C.data(), ldc);아래 두 번째 코드 예제는 cuBLAS DEGMM 호출을 나타낸 것입니다.
// Init Data
…
// Data movement to GPU
…
// Execute GEMM
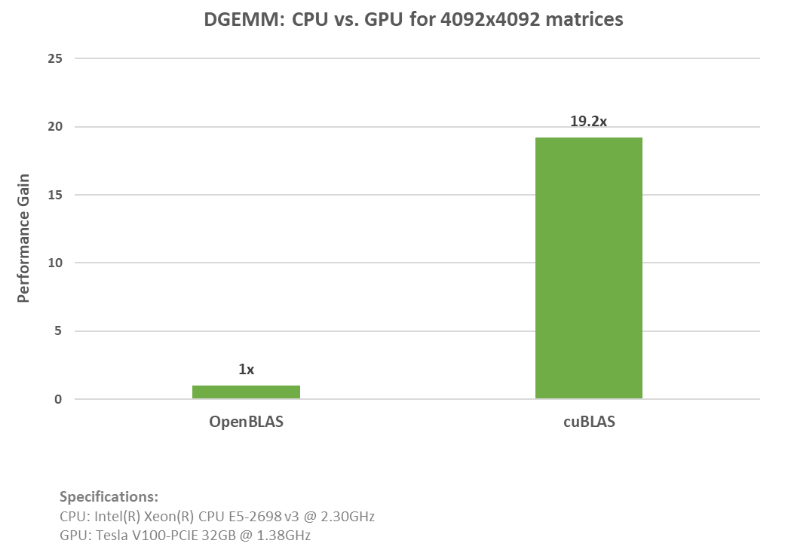
cublasDgemm(cublasH, CUBLAS_OP_N, CUBLAS_OP_T, m, n, k, &alpha, d_A, lda, d_B, ldb, &beta, d_C, ldc));위 예제에서 알 수 있듯이 손쉽게 추가하여 OpenBLAS CPU 코드를 cuBLAS API 함수로 대체할 수 있습니다. cuBLAS 및 OpenBLAS 예제에 대한 전체 코드를 살펴보세요. cuBLAS 예제는 NVIDIA(R) V100 Tensor Core GPU에서 거의 20배까지 가속하여 실행했습니다. 아래 그래프는 위의 두 예제를 실행했을 때 가속도와 규격을 나타낸 것입니다.
흥미로운 사실: 이 라이브러리는 cuPy, cuDNN, RAPIDS 같은 하이 레벨 Python API를 통해 호출되기 때문에 API를 사용한 경험이 있다면 이미 NVIDIA Math 라이브러리를 사용한 셈입니다.
이번 게시글에서 사용 가능한 Math 라이브러리에 대해 알아보겠습니다. 최신 업데이트 및 정보는 NVIDIA Math 라이브러리의 최근 개발 소식에서 알아볼 수 있습니다.
CPU에 의존하는 방법을 뛰어넘는 성능 향상
BLAS의 GPU 가속 구현부터 난수 생성에 이르기까지 이용할 수 있는 NVIDIA Math 라이브러리는 많습니다. 이제부터 NVIDIA Math 라이브러리에 대한 개요를 읽으면서 애플케이션 성능을 손쉽게 높일 수 있는 방법에 대해 알아보세요.
cuBLAS를 통한 BLAS 가속
GEMM(General Matrix Multiplication)은 AI 및 계산 과학 분야에 배포되는 BLAS(Basic Linear Algebra Subprograms) 중에서 가장 높은 인기를 자랑합니다. 또한 딥 러닝 프레임워크에서도 기본적인 블록을 형성합니다. GEMM을 딥 러닝 프레임워크에 사용하는 방법에 대해 자세히 알고 싶다면 딥 러닝에서 GEMM이 중요한 이유를 참조하세요.
cuBLAS 라이브러리는 뛰어난 GPU 가속 기능을 이용하는 BLAS 구현체입니다. 이 라이브러리는 점곱(레벨 1), 벡터합(레벨 2), 행렬곱(레벨 3) 같은 벡터 및 행렬 연산을 실행할 수 있는 루틴으로 구성되어 있습니다.
또한 행렬-행렬 곱을 병렬 처리하고 싶다면 cuBLAS가 다기능 배치 처리 방식의 GEMM을 지원하여 텐서 계산, 머신 러닝 및 LAPACK에서도 사용할 수 있습니다. 머신 러닝, 텐서 계산에서 효율을 높일 수 있는 방법에 대해 자세히 알고 싶다면 CPU 및 GPU에서 BLAS 커널 확장을 통한 텐서 계산을 참조하세요.
cuBLASXt
문제 규모가 너무 커서 GPU만으로 부족하거나, 애플리케이션에 싱글-노드, 멀티-GPU 지원이 필요하다면 cuBLASXt가 좋은 해답이 될 수 있습니다. cuBLASXt는 하이브리드 CPU-GPU 계산이 가능할 뿐만 아니라 BLAS Level 3 연산을 지원하여 herk 같이 Hermitian 랭크를 업데이트하는 행렬-행렬 연산도 실행합니다.
cuBLASLt
cuBLASLt는 GEMM을 지원하는 경량 라이브러리입니다. 이 라이브러리는 커널 2개 이상을 단일 커널로 “결합”한 융합 커널을 사용해 애플리케이션을 가속하기 때문에 데이터 재사용이 가능할 뿐만 아니라 데이터 전송도 줄어듭니다. 또한 사용자가 에필로그에 후처리 옵션을 설정하는 것도 가능합니다(바이어스와 ReLU 변환을 차례대로 적용하거나, 바이어스 기울기를 입력 행렬에 적용).
cuBLASMg: CUDA Math Library Early Access 프로그램
문제 규모가 크다면 cuBLASMg가 최신 멀티-GPU, 멀티-노드 행렬-행렬곱을 지원하는지 확인하세요. 현재 이 행렬곱은 CUDA Math Library Early Access 프로그램에서 지원하고 있습니다. 지금 프로그램에 가입하세요.
cuSPARSE를 통한 희소 행렬 처리
희소 행렬, 밀집 행렬곱(SpMM)은 경제, 그래프, 데이터 분석, 머신 러닝, 딥 러닝, CFD, 지진 탐광 분야 등에서 다양한 복합 알고리즘에 사용됩니다. 여러 가지 과학 시뮬레이션에서 효율적인 희소 행렬 처리는 이제 필수입니다.
신경망 확장과 이로 인한 비용 및 리소스 상승 때문에 희소화에 대한 필요성이 대두되었습니다. 딥 러닝 훈련 및 추론 시 리소스 사용을 최적화해야 한다는 점에서 희소성은 점차 인기를 더하고 있습니다. 이러한 관점과 cuSPARSE 같은 라이브러리의 필요성에 대해 자세히 알고 싶다면 심층 신경망을 위한 희소성의 미래를 참조하세요.
cuSPARSE에서 제공하는 BLAS 세트는 GPU 가속 솔버를 개발할 때 사용되는 희소 행렬을 처리하는 데 효과적입니다. 라이브러리 루틴은 4가지 카테고리가 있습니다.
- 레벨 1은 희소 벡터와 밀집 벡터 사이에서 점곱 같은 연산을 실행합니다.
- 레벨 2는 희소 행렬과 밀집 벡터 사이에서 행렬-벡터곱 같은 연산을 실행합니다.
- 레벨 3은 희소 행렬과 밀집 벡터 세트 사이에서 행렬-행렬곱 같은 연산을 실행합니다.
- 레벨 4는 다양한 행렬 형식을 서로 변환하고, 압축 희소행(CSR) 행렬을 압축합니다.
cuSPARSELt
행렬 가지치기 및 압축이 가능한 helper 함수와 함께 희소 행렬-밀집 행렬곱을 계산할 수 있는 경량 버전의 cuSPARSE 라이브러리를 원한다면 cuSPARSELt를 사용하세요. cuSPARSELt 라이브러리에 대해 자세히 알고 싶다면 cuSPARSELt를 통한 NVIDIA Ampere 구조화 희소성 살펴보기를 참조하세요.
cuTENSOR를 통한 텐서 애플리케이션 가속화
cuTENSOR 라이브러리는 텐서 선형대수 라이브러리 구현체입니다. 텐서는 머신 러닝 애플리케이션에 필수적일 뿐만 아니라 응용 문제에 필요한 지배 방정식을 유도하는 데 없어서는 안 될 Math 도구입니다. cuTENSOR는 직접 텐서 축약, 텐서 축소, 원소별 텐서 연산을 위한 루틴을 제공하기 때문에 딥 러닝 훈련 및 추론, 컴퓨터 비전, 양자 화학, 계산 물리학 분야에서 성능을 높이는 데 사용됩니다.
cuTENSORMg
cuTENSOR 기능을 원하는 동시에 DGX A100을 사용할 때처럼 대규모 텐서를 싱글 노드의 멀티-GPU로 분산시켜야 한다면 cuTENSORMg가 적합합니다. 이 라이브러리는 혼합 정밀도를 광범위하게 지원할 뿐만 아니라 주요 계산 루틴에 직접 텐서 축약, 텐서 축소, 원소별 텐서 연산이 포함되어 있습니다. .
cuSOLVER를 통한 GPU 가속 LAPACK 기능
cuSOLVER 라이브러리는 cuBLAS 라이브러리와 cuSPARSE 라이브러리를 기반으로 선형대수 함수에 유용한 하이 레벨 패키지입니다. cuSOLVER는 행렬 인수분해, 밀집 행렬에 대한 삼각 풀이 루틴, 희소 최소제곱 솔버, 고유값 솔버 같이 LAPACK과 유사한 기능을 제공합니다.
cuSOLVER는 다음과 같이 세 가지 성분이 분리되어 있습니다.
- cuSolverDN은 밀집 행렬 인수분해에 사용됩니다.
- cuSolverSP는 희소 QR 인수분해를 기반으로 희소 루틴 세트를 제공합니다.
- cuSolverRF는 희소 재인수분해 패키지로 공유 희소성 패턴이 포함된 행렬의 순차를 풀이하는 데 유용합니다.
cuSOLVERMg
GPU 가속 ScaLAPACK 기능, 대칭형 고유 솔버, 1-D 컬럼 블록 순환 레이아웃 지원, cuSOLVER 기능에 대한 싱글-노드, 멀티-GPU 지원이 필요하다면 cuSOLVERMg를 고려해보십시오.
cuSOLVERMp
대규모 선형 방정식 체계를 풀이하려면 멀티-노드, 멀티-GPU 지원이 필요합니다. 이때는 LU 인수분해 기능과 Cholesky 인수분해 기능으로 잘 알려진 cuSOLVERMp가 효과적입니다.
cuRAND를 통한 대규모 난수 생성
cuRAND 라이브러리는 호스트(CPU) API 또는 디바이스(GPU) API에서 의사 난수 또는 유사 난수 생성기를 통해 집중적으로 난수를 생성합니다. 호스트 API는 오직 호스트에서 난수를 생성하여 호스트 메모리에 저장할 수 있습니다. 호스트에서 라이브러리를 호출하는 디바이스에서도 난수 생성이 가능하지만 이때는 난수가 디바이스에서 생성되어 전역 메모리에 저장됩니다.
디바이스 API는 난수 생성기 상태를 설정하고 난수 순차를 생성할 수 있는 함수를 정의합니다. 이렇게 생성된 난수는 읽어와서 전역 메모리에 작성할 필요 없이 사용자 커널에서 바로 사용됩니다. 몇 가지 물리 기반 문제들은 대규모 난수 생성이 필요한 것으로 알려져 있습니다.
몬테카를로 시뮬레이션도 GPU에서 난수 생성기가 필요한 사용 사례 중 하나입니다. CUDA Fortran에서 몬테카를로 애플리케이션에 필요한 GPU 기반 병렬 PRNG 개발이라는 논문을 보면 cuRAND를 응용하여 대규모 난수를 생성하는 방법이 자세하게 나와 있습니다.
cuFFT를 통한 고속 푸리에 변환 계산
CUDA Fast Fourier Transform(FFT)의 줄임말인 cuFFT 라이브러리는 NVIDIA GPU에서 손쉽게 FFT를 계산할 수 있는 인터페이스를 제공합니다. FFT는 복소수 또는 실수형 데이터 세트의 이산 푸리에 변환을 효율적으로 계산할 수 있는 분할-정복 알고리즘입니다. 또한 계산 물리학이나 일반 신호 처리에서 가장 널리 사용되는 수치 알고리즘 중 하나이기도 합니다.
cuFFT는 의료 영상 처리, 유체 동역학 등 광범위한 분야에서 사용됩니다. 광음향 현미경에서 정성적 혈류 영상 처리에 사용되는 병렬 컴퓨팅 논문을 보면 물리학 분야에 사용되는 cuFFT를 자세하게 설명하고 있습니다. 기존 FFTW 애플리케이션 사용자들도 코드를 손쉽게 NVIDIA GPU로 이식하려면 cuFFTW를 사용해야 합니다. cuFFTW 라이브러리는 FFTW3 API를 제공하여 기존 FFTW 애플리케이션을 어려움 없이 이식할 수 있도록 지원합니다.
cuFFTXt
FFT 계산 결과를 싱글 노드의 GPU로 분산시키고 싶다면 cuFFTXt가 좋습니다. 이 라이브러리에는 사용자가 멀티-GPU에서 데이터를 조작하고 데이터 순서를 추적할 수 있는 함수가 포함되어 있어서 최대한 효율적인 방법으로 데이터를 처리할 수 있습니다.
cuFFTMp
cuFFTMp는 단일 시스템에서 멀티-GPU를 지원할 뿐만 아니라 멀티 노드에서 멀티-GPU까지 지원합니다. 이 라이브러리는 MPI 구현체의 품질과 관련이 없기 때문에 어떤 MPI 애플리케이션에서든 사용 가능합니다. 그 밖에도 NVIDIA GPU를 고려해 설계된 OpenSHMEM 표준 기반 통신 라이브러리인 NVSHMEM을 사용합니다.
cuFFTDx
불필요한 전역 메모리 이동을 없애고 다른 연산을 사용해 FFT 커널을 융합하여 성능을 높이고 싶다면 cuFFTDx (cuFFT device extensions)를 추천합니다. Math Libraries Device Extensions에서 기본적으로 제공되는 이 라이브러리를 사용하면 애플리케이션이 사용자 커널 내에서 FFT를 계산할 수 있습니다.
CUDA Math API를 통한 표준 Math 함수 최적화
CUDA Math API는 NVIDIA GPU 아키텍처에 최적화된 표준 수학 함수를 모아놓은 컬렉션입니다. CUDA 라이브러리는 모두 CUDA Math 라이브러리를 이용합니다. CUDA Math API는 모든 C99 표준 부동 소수점 및 배정밀도 Math 함수를 비롯해 부동 소수점/배정밀도/모든 반올림 모드와 그 밖에 삼각 및 지수 함수(cospi, sincos), 추가 오차 역함수(erfinv, erfcinv) 같은 다양한 함수를 지원합니다.
C++ 템플릿을 CUTLASS와 함께 사용하는 코드 사용자 정의
행렬곱은 다양한 과학 계산에서 기본적인 역할을 합니다. 특히 딥 러닝 알고리즘을 효율적으로 구현하려면 반드시 필요한 것이 행렬곱입니다. cuBLAS와 마찬가지로 CUTLASS(CUDA Templates for Linear Algebra Subroutines) 역시 계산 및 스케일링 효율을 높일 수 있는 선형대수 루틴 세트로 구성됩니다.
여기에는 cuBLAS와 cuDNN을 구현할 때 사용되는 전략과 비슷한 계층적 분해 및 데이터 이동 전략이 포함되어 있습니다. 하지만 CUTLASS는 점차 모듈화 개념을 사용해 재구성된다는 점에서 cuBLAS와 다릅니다. GEMM에서 움직이는 부분을 C++ 템플릿 클래스로 사용할 수 있는 기초 성분 또는 블록으로 분해하기 때문에 알고리즘을 유연하게 사용자 정의할 수 있습니다. 지연 시간을 숨기고 데이터 재사용을 극대화할 목적으로 파이프라인이 구축됩니다. 따라서 충돌 없이 공유 메모리에 액세스하여 데이터 처리량을 극대화하고, 메모리 풋프린트를 제거하고, 애플리케이션을 원하는 대로 정확하게 설계할 수 있습니다. CUTLASS를 사용해 애플리케이션 성능을 높일 수 있는 방법에 대해 자세히 알고 싶다면 CUTLASS: CUDA C++의 고속 선형 대수를 참조하세요.
AmgX를 통한 미분 방정식 계산
AmgX는 GPU 가속 AMG(Algebraic Multi-Grid) 라이브러리를 제공하며, 분산 노드의 싱글 GPU 또는 멀티-GPU에서 지원됩니다. 따라서 사용자가 복합 중첩 솔버, 스무더, 프리컨디셔너를 생성할 수 있습니다. 이 라이브러리는 block-Jacobi, Gauss-Seidel, dense LU 등 다양한 스무더를 사용해 클래식 및 집계를 기반으로 대수적 멀티그리드 기법을 구현합니다.
이 라이브러리에는 PCG, BICGStab 같이 선조건자가 적용된 Krylov subspace 반복 계산법도 포함되어 있습니다 AmgX는 시뮬레이션에서 계산 집약적인 선형 솔버를 최대 10배까지 가속하기 때문에 내재적 비정렬 기법에 적합합니다.
AmgX는 특히 CFD 응용 분야를 고려해 개발되었지만 에너지, 물리학, 원자력 안전 같은 분야에서도 사용 가능합니다. 예를 들어 소규모 컴퓨팅 문제부터 대규모 컴퓨팅 문제에 이르기까지 푸아송 방정식의 해를 구할 때도 AmgX 라이브러리가 사용됩니다.
플라잉 스네이크 시뮬레이션 예를 보면 GPU에서 AmgX 래퍼를 사용해 CFD 코드를 가속했을 때 시간과 비용이 얼마나 줄어드는지 알 수 있습니다. 12코어 CPU 노드 1개와 비교했을 때 K20 GPU 1개에서 메시 포인트 300만 개로 21배까지 가속됩니다.
NVIDIA Math 라이브러리 시작하기
•cuBLAS, cuRAND, cuFFT, cuSPARSE, cuSOLVER, CUDA Math 라이브러리가 NVIDIA HPC SDK와 CUDA Toolkit에서 기본 제공됩니다.
- cuFFTDx(Math Library Device Extensions)는 MathDx 20.22에서 사용할 수 있습니다.
- cuTENSOR, cuSPARSELt, MathDx는 DevZone에서 찾아볼 수 있습니다.
- AmgX, CUTLASS는 GitHub에서 사용할 수 있습니다.
- cuBLASMg는 현재 CUDA Math Library Early Access 프로그램에서 기본 제공됩니다.
앞으로도 NVIDIA Math 라이브러리를 개선하기 위한 노력을 아끼지 않겠습니다. 궁금한 점이 있거나 새로운 기능을 요청하고 싶다면 제품 관리자인 Matthew Nicely에게 문의하시기 바랍니다.