

Today at an AI meetup in San Francisco, NVIDIA launched Jetson TX2 and the JetPack 3.0 AI SDK. Jetson is the world’s leading low-power embedded platform, enabling server-class AI compute performance for edge devices everywhere. Jetson TX2 features an integrated 256-core NVIDIA Pascal GPU, a hex-core ARMv8 64-bit CPU complex, and 8GB of LPDDR4 memory with a 128-bit interface. The CPU complex combines a dual-core NVIDIA Denver 2 alongside a quad-core Arm Cortex-A57. The Jetson TX2 module—shown in Figure 1—fits a small Size, Weight, and Power (SWaP) footprint of 50 x 87 mm, 85 grams, and 7.5 watts of typical energy usage.
Internet-of-Things (IoT) devices typically function as simple gateways for relaying data. They rely on cloud connectivity to perform their heavy lifting and number-crunching. Edge computing is an emerging paradigm which uses local computing to enable analytics at the source of the data. With more than a TFLOP/s of performance, Jetson TX2 is ideal for deploying advanced AI to remote field locations with poor or expensive internet connectivity. Jetson TX2 also offers near-real-time responsiveness and minimal latency—key for intelligent machines that need mission-critical autonomy.
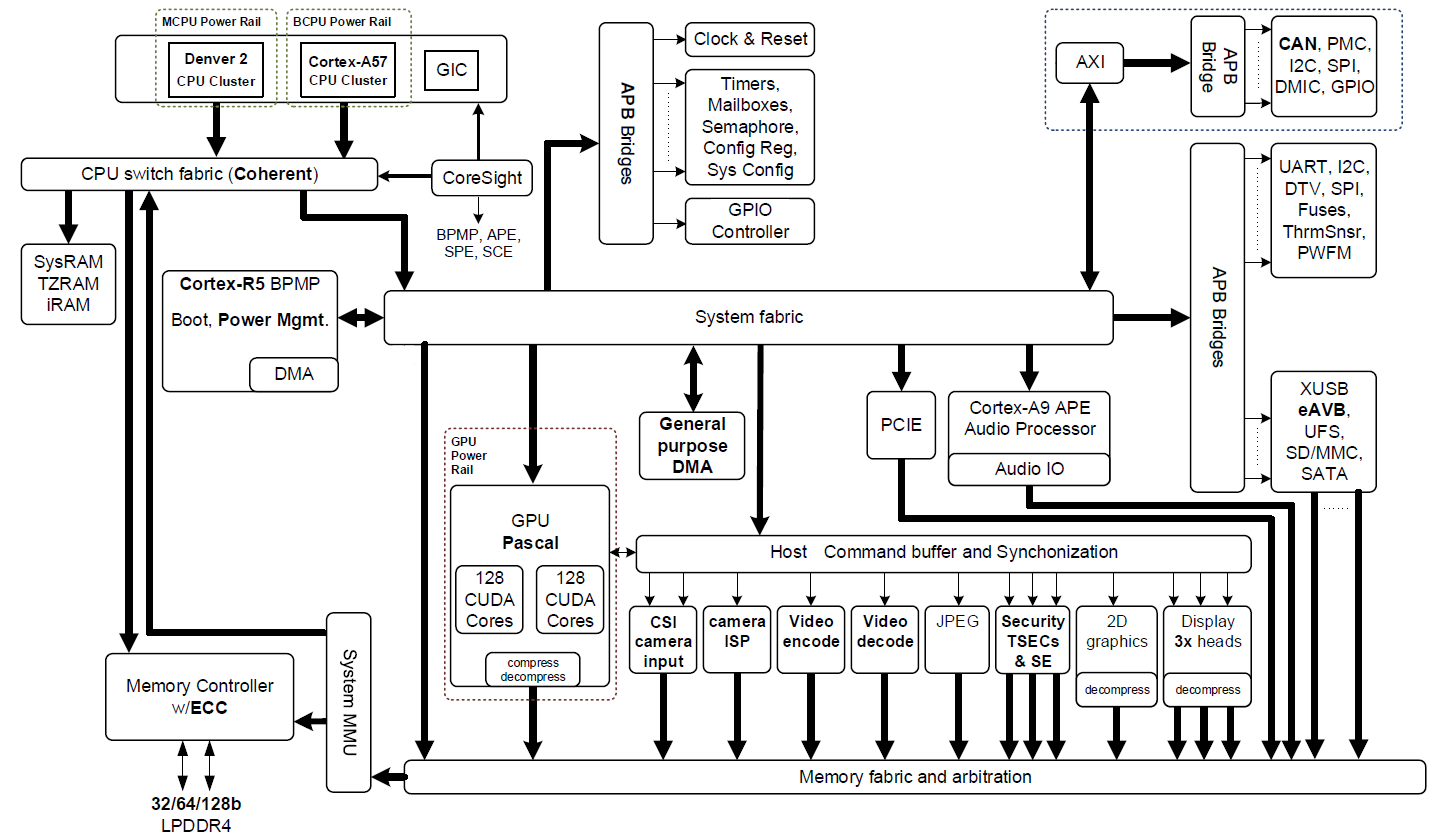
Jetson TX2 is based on the 16nm NVIDIA Tegra “Parker” system on a chip (SoC) (Figure 2 shows a block diagram). Jetson TX2 is twice as energy efficient for deep learning inference than its predecessor, Jetson TX1, and offers higher performance than an Intel Xeon Server CPU. This jump in efficiency redefines possibilities for extending advanced AI from the cloud to the edge.
Jetson TX2 has multiple multimedia streaming engines to keep its Pascal GPU fed with data by offloading sensor acquisition and distribution. These multimedia engines include six dedicated MIPI CSI-2 camera ports that provide up to 2.5 Gb/s per lane of bandwidth and 1.4 gigapixels/s processing by dual Image Service Processors (ISP), as well as video codecs supporting H.265 at 4K 60 frames per second.
Jetson TX2 accelerates cutting-edge deep neural network (DNN) architectures using the NVIDIA cuDNN and TensorRT libraries, with support for Recurrent Neural Networks (RNNs), Long Short-Term Memory networks (LSTMs), and online reinforcement learning. Its dual-CAN bus controller enables autopilot integration to control robots and drones that use DNNs to perceive the world around them and operate safely in dynamic environments. Software for Jetson TX2 is provided through NVIDIA’s JetPack 3.0 and Linux For Tegra (L4T) Board Support Package (BSP).
Table 1 compares the features of Jetson TX2 to those of the previous-generation Jetson TX1.
| NVIDIA Jetson TX1 |
NVIDIA Jetson TX2 |
|
|---|---|---|
| CPU | Arm Cortex-A57 (quad-core) @ 1.73GHz | Arm Cortex-A57 (quad-core) @ 2GHz + NVIDIA Denver2 (dual-core) @ 2GHz |
| GPU | 256-core Maxwell @ 998MHz | 256-core Pascal @ 1300MHz |
| Memory | 4GB 64-bit LPDDR4 @ 1600MHz | 25.6 GB/s | 8GB 128-bit LPDDR4 @ 1866Mhz | 59.7 GB/s |
| Storage | 16GB eMMC 5.1 | 32GB eMMC 5.1 |
| Encoder* | 4Kp30, (2x) 1080p60 | 4Kp60, (3x) 4Kp30, (8x) 1080p30 |
| Decoder* | 4Kp60, (4x) 1080p60 | (2x) 4Kp60 |
| Camera† | 12 lanes MIPI CSI-2 | 1.5 Gb/s per lane | 1400 megapixels/sec ISP | 12 lanes MIPI CSI-2 | 2.5 Gb/sec per lane | 1400 megapixels/sec ISP |
| Display | 2x HDMI 2.0 / DP 1.2 / eDP 1.2 | 2x MIPI DSI | |
| Wireless | 802.11a/b/g/n/ac 2×2 867Mbps | Bluetooth 4.0 | 802.11a/b/g/n/ac 2×2 867Mbps | Bluetooth 4.1 |
| Ethernet | 10/100/1000 BASE-T Ethernet | |
| USB | USB 3.0 + USB 2.0 | |
| PCIe | Gen 2 | 1×4 + 1 x1 | Gen 2 | 1×4 + 1×1 or 2×1 + 1×2 |
| CAN | Not supported | Dual CAN bus controller |
| Misc I/O | UART, SPI, I2C, I2S, GPIOs | |
| Socket | 400-pin Samtec board-to-board connector, 50x87mm | |
| Thermals‡ | -25°C to 80°C | |
| Power†† | 10W | 7.5W |
| Price | $299 at 1K units | $399 at 1K units |
Twice the Performance, Twice the Efficiency
In my post on JetPack 2.3, I demonstrated how NVIDIA TensorRT increased Jetson TX1 deep learning inference performance with 18x better efficiency than a desktop class CPU. TensorRT optimizes production networks to significantly improve performance by using graph optimizations, kernel fusion, half-precision floating point computation (FP16), and architecture autotuning. In addition to leveraging Jetson TX2’s hardware support for FP16, NVIDIA TensorRT is able to process multiple images simultaneously in batches, resulting in higher performance.
Jetson TX2 and JetPack 3.0 together take the performance and efficiency of the Jetson platform to a whole new level by providing users the option to get twice the efficiency or up to twice the performance of Jetson TX1 for AI applications. This unique capability makes Jetson TX2 the ideal choice both for products that need efficient AI at the edge and for products that need high performance near the edge. Jetson TX2 is also drop-in compatible with Jetson TX1 and provides an easy upgrade opportunity for products designed with Jetson TX1.
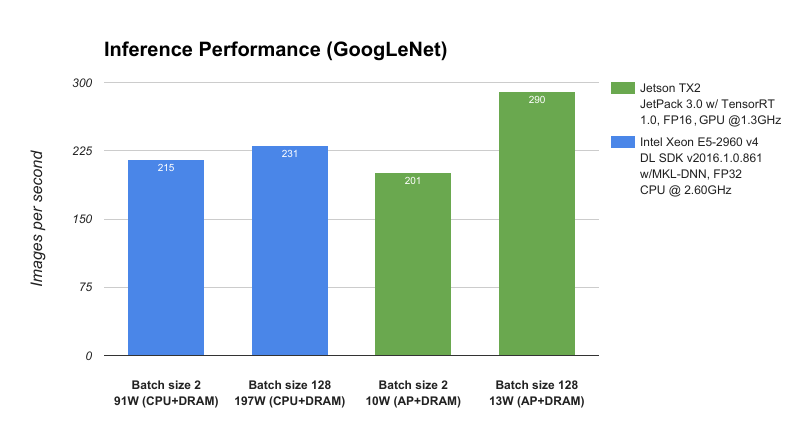
To benchmark the performance of Jetson TX2 and JetPack 3.0 we compare it against a server class CPU, Intel Xeon E5-2690 v4, and measure the deep learning inference throughput (images per second) using the GoogLeNet deep image recognition network. As shown Figure 3, Jetson TX2 operating at less than 15 W of power outperforms the CPU operating at nearly 200 W, enabling data center level AI capabilities on the edge.
This exceptional AI performance and efficiency of Jetson TX2 stems from the new Pascal GPU architecture and dynamic energy profiles (Max-Q and Max-P), optimized deep learning libraries that come with JetPack 3.0, and the availability of large memory bandwidth.
Max-Q and Max-P
Jetson TX2 was designed for peak processing efficiency at 7.5W of power. This level of performance, referred to as Max-Q, represents the peak of the power/throughput curve. Every component on the module including the power supply is optimized to provide highest efficiency at this point. The Max-Q frequency for the GPU is 854 MHz, and for the Arm A57 CPUs it’s 1.2 GHz. The L4T BSP in JetPack 3.0 includes preset platform configurations for setting Jetson TX2 in Max-Q mode. JetPack 3.0 also includes a new command line tool called nvpmodel for switching profiles at run time.
While Dynamic Voltage and Frequency Scaling (DVFS) permits Jetson TX2’s Tegra “Parker” SoC to adjust clock speeds at run time according to user load and power consumption, the Max-Q configuration sets a cap on the clocks to ensure that the application is operating in the most efficient range only. Table 2 shows the performance and energy efficiency of Jetson TX2 and Jetson TX1 when running the GoogLeNet and AlexNet deep learning benchmarks. The performance of Jetson TX2 operating in Max-Q mode is similar to the performance of Jetson TX1 operating at maximum clock frequency but consumes only half the power, resulting in double the energy efficiency.
Although most platforms with a limited power budget will benefit most from Max-Q behavior, others may prefer maximum clocks to attain peak throughput, albeit with higher power consumption and reduced efficiency. DVFS can be configured to run at a range of other clock speeds, including underclocking and overclocking. Max-P, the other preset platform configuration, enables maximum system performance in less than 15W. The Max-P frequency is 1122 MHz for the GPU and 2 GHz for the CPU when either Arm A57 cluster is enabled or Denver 2 cluster is enabled and 1.4 GHz when both the clusters are enabled. You can also create custom platform configurations with intermediate frequency targets to allow balancing between peak efficiency and peak performance for your application. Table 2 below shows how the performance increases going from Max-Q to Max-P and the maximum GPU clock frequency while the efficiency gradually reduces.
| NVIDIA Jetson TX1 |
NVIDIA Jetson TX2 |
||||
|---|---|---|---|---|---|
| Max Clock (998 MHz) |
Max-Q (854 MHz) |
max-P (1122 MHz) |
Max Clock (1302 MHz) |
||
|
GoogLeNet |
Perf | 141 FPS | 138 FPS | 176 FPS | 201 FPS |
| Power (AP+DRAM) | 9.14 W | 4.8 W | 7.1 W | 10.1 W | |
| Efficiency | 15.42 | 28.6 | 24.8 | 19.9 | |
| GoogLeNet batch=128 |
Perf | 204 FPS | 196 FPS | 253 FPS | 290 FPS |
| Power (AP+DRAM) |
11.7 W | 5.9 W | 8.9 W | 12.8 W | |
| Efficiency | 17.44 | 33.2 | 28.5 | 22.7 | |
| AlexNet batch=2 |
Perf | 164 FPS | 178 FPS | 222 FPS | 250 FPS |
| Power (AP+DRAM) | 8.5 W | 5.6 W | 7.8 W | 10.7 W | |
| Efficiency | 19.3 | 32 | 28.3 | 23.3 | |
| AlexNet batch=128 |
Perf | 505 FPS | 463 FPS | 601 FPS | 692 FPS |
| Power (AP+DRAM) | 11.3 W | 5.6 W | 8.6 W | 12.4 W | |
| Efficiency | 44.7 | 82.7 | 69.9 | 55.8 | |
Jetson TX2 performs GoogLeNet inference up to 33.2 images/sec/Watt, nearly double the efficiency of Jetson TX1 and nearly 20X more efficient than Intel Xeon.
End-to-End AI Applications
Integral to Jetson TX2’s efficient performance are two Pascal Streaming Multiprocessors (SMs) with 128 CUDA cores each. The Pascal GPU architecture offers major performance improvements and power optimizations. TX2’s CPU Complex includes a dual-core 7-way superscalar NVIDIA Denver 2 for high single-thread performance with dynamic code optimization, and a quad-core Arm Cortex-A57 geared for multithreading.
The coherent Denver 2 and A57 CPUs each have a 2MB L2 cache and are linked via high-performance interconnect fabric designed by NVIDIA to enable simultaneous operation of both CPUs within a Heterogeneous Multiprocessor (HMP) environment. The coherency mechanism allows tasks to be freely migrated according to dynamic performance needs, efficiently utilizing resources between the CPU cores with reduced overhead.
Jetson TX2 is the ideal platform for the end-to-end AI pipeline for autonomous machines. Jetson is wired for streaming live high-bandwidth data: it can simultaneously ingest data from multiple sensors and perform media decoding/encoding, networking, and low-level command & control protocols after processing the data on the GPU. Figure 4 shows common pipeline configurations with sensors attached using an array of high-speed interfaces including CSI, PCIe, USB3, and Gigabit Ethernet. The CUDA pre- and post-processing stages generally consist of colorspace conversion (imaging DNNs typically use BGR planar format) and statistical analysis of the network outputs.
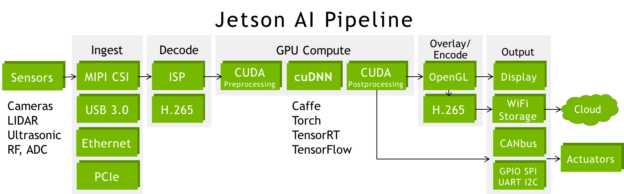
With double the memory and bandwidth than Jetson TX1, Jetson TX2 is able to capture and process additional streams of high-bandwidth data simultaneously, including stereo cameras and 4K ultra-HD inputs and outputs. Through the pipeline deep learning and computer vision fuse together multiple sensors from varying sources and spectral domains, increasing perception and situational awareness during autonomous navigation.
Getting Started with the Jetson TX2 Developer Kit
To get started, NVIDIA provides the Jetson TX2 Developer Kit complete with a reference mini-ITX carrier board (170 mm x 170mm) and a 5-megapixel MIPI CSI-2 camera module. The Developer Kit includes documentation and design schematics and free software updates to JetPack-L4T. Figure 5 pictures the Developer Kit, showing the Jetson TX2 module and standard PC connections including USB3, HDMI, RJ45 Gigabit Ethernet, SD card, and a PCIe x4 slot, which make it easy to develop applications for Jetson.

To move beyond development to custom deployed platforms, you can modify the reference design files for the Developer Kit carrier board and camera module to create a custom design. Alternatively, Jetson ecosystem partners offer off-the-shelf solutions for deploying Jetson TX1 and Jetson TX2 modules, including miniature carriers, enclosures, and cameras. The NVIDIA Developer Forums offer technical support and a home for collaboration with the community of Jetson builders and NVIDIA engineers. Table 3 lists principal documentation and helpful resources.
| Embedded Developer Portal : developer.nvidia.com/embedded | |
|---|---|
| Jetson TX2 Module Datasheet | Jetson TX2 OEM Design Guide |
| Jetson TX2 Thermal Design Guide | Jetson Developer Kit Carrier Specification |
| Jetson TX1-TX2 Interface Comparison and Migration | Jetson Developer Kit Carrier Design Files |
| L4T Accelerated GStreamer Guide | Jetson Camera Module Design Guide |
| Jetson TX2 Developer Forums | Jetson TX2 Wiki – eLinux.org/Jetson_TX2 |
The Jetson TX2 Developer Kit is available for preorder for $599 through the NVIDIA Online Store. Shipments begin March 14 in North America and Europe, with other regions to follow. The Jetson TX2 Education Discount is also available: $299 for affiliates of academic institutions. NVIDIA has reduced the price of the Jetson TX1 Developer Kit to $499.
JetPack 3.0 SDK
The latest NVIDIA JetPack 3.0 enables Jetson TX2 with industry-leading AI developer tools and hardware-accelerated API’s (see table 4) including the NVIDIA CUDA Toolkit version 8.0, cuDNN, TensorRT, VisionWorks, GStreamer, and OpenCV, built on top of the Linux kernel v4.4, L4T R27.1 BSP, and Ubuntu 16.04 LTS. Jetpack 3.0 includes the Tegra System Profiler and Tegra Graphics Debugger tools for interactive profiling and debugging. The Tegra Multimedia API includes low-level camera capture and Video4Linux2 (V4L2) codec interfaces. While flashing, JetPack automatically configures Jetson TX2 with the selected software components, enabling a complete environment out of the box.
| NVIDIA JetPack 3.0 — Software Components | |
|---|---|
| Linux kernel 4.4 | Ubuntu 16.04 LTS aarch64 |
| CUDA Toolkit 8.0.56 | cuDNN 5.1.10 |
| TensorRT 1.0 GA | GStreamer 1.8.2 |
| VisionWorks 1.6 | OpenCV4Tegra 2.4.13-17 |
| Tegra System Profiler 3.7 | Tegra Graphics Debugger 2.3 |
| Tegra Multimedia API | V4L2 Video Codec Interfaces |
Jetson is the high-performance embedded solution for deploying deep learning frameworks like Caffe, Torch, Theano, and TensorFlow. These and numerous other deep learning frameworks already integrate NVIDIA’s cuDNN library with GPU acceleration and require minimal migration effort to deploy on Jetson. Jetson adopts NVIDIA’s shared software and hardware architecture typically found in PC and server environments to seamlessly scale and deploy applications across the enterprise from the cloud and datacenter to devices at the edge.
Two Days to a Demo
NVIDIA Two Days to a Demo is an initiative to help anyone get started with deploying deep learning. NVIDIA provides computer vision primitives including image recognition, object detection + localization, and segmentation and neural network models trained with DIGITS. You can deploy these network models to Jetson for efficient deep learning inferencing with NVIDIA TensorRT. Two Days to a Demo provides example streaming apps to help you experiment with live camera feeds and real-world data, as Figure 6 shows.

Two Days to a Demo code is available on GitHub, along with easy to follow step-by-step directions for testing and re-training the network models, extending the vision primitives for your custom subject matter. The tutorials illustrate powerful concepts of the DIGITS workflow, showing you how to iteratively train network models in the cloud or on a PC and then deploy them to Jetson for run-time inferencing and further data collection.
Using pre-trained networks and transfer learning, this workflow makes it easy to tailor the base network to your tasks with custom object classes. Once a specific network architecture has been proven for a certain primitive or application, it’s often significantly easier to repurpose or retrain it for specific user-defined applications, given example training data containing the new objects.
As discussed in this Parallel Forall blog post, NVIDIA has added support for segmentation networks to DIGITS 5, now available for Jetson TX2 and Two Days to a Demo. The segmentation primitive uses a fully-convolutional Alexnet architecture (FCN-Alexnet) to classify individual pixels in the field of view. Since the classification occurs at the pixel-level, as opposed to the image level as in image recognition, segmentation models are able to extract comprehensive understanding of their surroundings. This overcomes significant hurdles faced by autonomously navigating robots and drones that can directly use the segmentation field for path planning and obstacle avoidance.
Segmentation-guided free space detection enables ground vehicles to safely navigate the ground plane, while drones visually identify and follow the horizon and sky planes to avoid collisions with obstacles and terrain. Sense & avoid capabilities are key for intelligent machines to interact safely with their environments. Processing the computationally-demanding segmentation networks onboard with TensorRT on Jetson TX2 is essential for the low response latency needed to avoid accidents.

Two Days to a Demo includes an aerial segmentation model (figure 7) using FCN-Alexnet, along with the corresponding first-person view (FPV) dataset of the horizon. The aerial segmentation model is useful as an example for drones and autonomous navigation. You can easily extend the model with custom data to recognize user-defined classes like landing pads and industrial equipment. Once augmented in this way, you can deploy it onto Jetson-equipped drones like the ones from Teal and Aerialtronics.
To encourage development of additional autonomous flight control modes, I’ve released the aerial training datasets, segmentation models, and tools on GitHub. NVIDIA Jetson TX2 and Two Days to a Demo make it easier than ever to get started with advanced deep learning solutions in the field.
Jetson Ecosystem
Jetson TX2’s modular form factor makes it deployable into a wide range of environments and scenarios. NVIDIA’s open-source reference carrier design from the Jetson TX2 Developer Kit provides a starting point for shrinking or modifying the design for individual project requirements. Some miniaturized carriers have the same 50x87mm footprint as the Jetson module itself, enabling compact assembly, as Figure 8 shows. Make your own using the documentation and design collateral available from NVIDIA or try an off-the-shelf solution. In April, NVIDIA will be offering the Jetson TX1 and TX2 modules for $299 and $399 respectively, in volumes of 1000 or more units.

Ecosystem partners ConnectTech and Auvidea offer deployable miniature carriers and enclosures compatible with the Jetson TX1 and TX2 shared socket, as seen in Figure 8. Imaging partners Leopard Imaging and Ridge Run provide cameras and multimedia support. Ruggedization specialists Abaco Systems and Wolf Advanced Technology provide MIL-spec qualifications for operating in harsh environments.

In addition to compact carriers and enclosures intended for deployment into the field, the reach of Jetson’s ecosystem extends beyond that of typical embedded applications. Jetson TX2’s many-core Arm/GPU architecture and exceptional compute efficiency also has the high-performance computing (HPC) industry taking note. High-density 1U rack mount servers are now available with 10 Gigabit Ethernet and up to 24 Jetson modules each. Figure 9 shows an example scalable array server. Jetson’s low power footprint and passive cooling are attractive for lightweight, scalable cloud tasks including low-power web servers, multimedia processing, and distributed computing. Video analytics and transcoding backends—often working in tandem with Jetsons deployed in the field on smart cameras and IoT devices—can benefit from Jetson TX2’s increased ratio of simultaneous data streams and video codecs supported per processor.
AI at the Edge
Jetson TX2’s unparalleled embedded compute capability brings cutting-edge DNNs and next-generation AI to life on board edge devices. Jetson TX2 delivers server-grade performance at high energy efficiency in the palm of your hand. It outperforms Intel Xeon in raw deep learning performance by 1.25X and compute efficiency by a factor of nearly 20X. Jetson’s compact footprint, compute capacity, and JetPack software stack with deep learning enables developers to solve 21st-century challenges using AI. Get started today to deploy your own advanced AI today with Jetson TX2. Preorders are available through March 14, or apply for the Academic Discount online. NVIDIA’s Embedded Developer portal has more information.
