
Today, NVIDIA released JetPack 3.1, the production Linux software release for Jetson TX1 and TX2. With upgrades to TensorRT 2.1 and cuDNN 6.0, JetPack 3.1 delivers up to a 2x increase in deep learning inference performance for real-time applications like vision-guided navigation and motion control, which benefit from accelerated batch size 1. The improved features allow Jetson to deploy greater intelligence than ever, enabling a generation of autonomous machines including delivery robots, telepresence, and video analytics. To further spur development in robotics, NVIDIA’s recently introduced Isaac Initiative is an end-to-end platform for training and deploying advanced AI to the field.

AI at the Edge
Earlier this spring when NVIDIA launched Jetson TX2, the de-facto platform for edge computing received a significant boost in capabilities. As exemplified by the Wave Glider platform in Figure 1, remote Internet-of-Things (IoT) devices at the edge of the network frequently experience degraded network coverage, latency, and bandwidth. While IoT devices typically serve as gateways for relaying data to the cloud, edge computing reframes the possibilities of IoT with access to secure onboard compute resources. NVIDIA’s Jetson embedded modules deliver server-grade performance with 1 TFLOP/s on Jetson TX1, and double the AI performance on Jetson TX2 in under 10W of power.
JetPack 3.1
JetPack 3.1 with Linux For Tegra (L4T) R28.1 is the production software release for Jetson TX1 and TX2 with long-term support (LTS). The L4T Board Support Packages (BSPs) for TX1 and TX2 are suitable for customer productization, and their shared Linux kernel 4.4 code-base provides compatibility and seamless porting between the two. Starting with JetPack 3.1, developers have access to the same libraries, APIs, and tool versions on both TX1 and TX2.
| NVIDIA JetPack 3.1 — Software Components | |
|---|---|
| Linux For Tegra R28.1 | Ubuntu 16.04 LTS aarch64 |
| CUDA Toolkit 8.0.82 | cuDNN 6.0 |
| TensorRT 2.1 GA | GStreamer 1.8.2 |
| VisionWorks 1.6 | OpenCV4Tegra 2.4.13-17 |
| Tegra System Profiler 3.8 | Tegra Graphics Debugger 2.4 |
| Tegra Multimedia API | V4L2 Camera/Codec API |
In addition to upgrading from cuDNN 5.1 to 6.0 and a maintenance update to CUDA 8, JetPack 3.1 includes the latest vision and multimedia APIs for building streaming applications. You can download JetPack 3.1 to your host PC to flash Jetson with the latest BSP and tools.
Low-latency Inference with TensorRT 2.1
The latest version of TensorRT is included in JetPack 3.1 so you can deploy optimized run-time deep learning inference on Jetson. TensorRT increases inference performance with network graph optimizations, kernel fusion, and half-precision FP16 support. TensorRT 2.1 includes key features and enhancements, such as multi-weight batching, that further increase the deep learning performance and efficiency of Jetson TX1 and TX2 and reduce latency.
Performance for batch size 1 has been significantly improved, resulting in reduced latency down to 5ms for GoogLeNet. For latency-sensitive applications, batch size 1 offers the lowest latency, since each frame is processed as soon as it arrives in the system (rather than waiting to batch up multiple frames). As shown in Figure 2 on Jetson TX2, using TensorRT 2.1 achieves double the throughput of TensorRT 1.0 for GoogLeNet and ResNet image recognition inference.
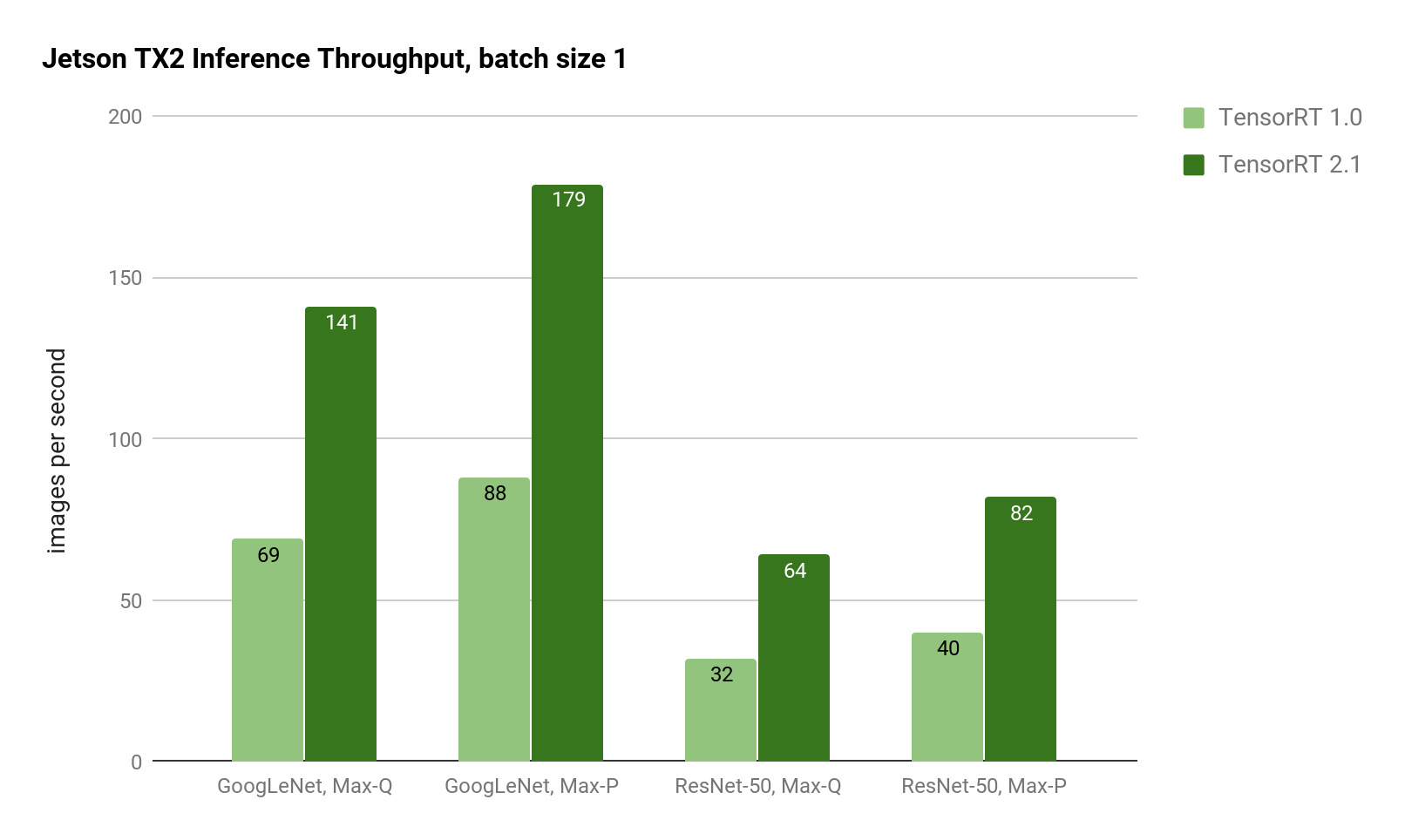
The latencies in Table 2 show a proportional reduction with batch size 1. With TensorRT 2, Jetson TX2 achieves 5ms latency for GoogLeNet In Max-P performance profile, and 7ms latency while running in Max-Q efficiency profile. ResNet-50 has 12.2ms latency in Max-P and 15.6ms latency in Max-Q. ResNet is typically used for improved accuracy in image classification beyond GoogLeNet, which gets more than 2x run-time performance increase using TensorRT 2.1. And with Jetson TX2’s 8GB memory capacity, large batch sizes up to 128 are possible even on complex networks like ResNet.
| NETWORK | LATENCY | SPEEDUP | |
|---|---|---|---|
| TensorRT 1.0 | TensorRT 2.1 | ||
| GoogLeNet, Max-Q | 14.5ms | 7.1ms | 2.04x |
| GoogLeNet, Max-P | 11.4ms | 5.6ms | 2.04x |
| ResNet-50, Max-Q | 31.4ms | 15.6ms | 2.01x |
| ResNet-50, Max-P | 24.7ms | 12.2ms | 2.03x |
The reduced latency allows deep learning inference approaches to be used in applications that demand near-real-time responsiveness, like collision avoidance and autonomous navigation on high-speed drones and surface vehicles.
Custom Layers
With support for custom network layers via a user plugin API, TensorRT 2.1 is able to run the latest networks and features with expanded support including residual networks (ResNet), Recurrent Neural Networks (RNN), You Only Look Once (YOLO), and Faster-RCNN (Regional Convolutional Neural Network). Custom layers are implemented in user-defined C++ plugins which implement the IPlugin interface as in the following code.
#include "NvInfer.h"
using namespace nvinfer1;
class MyPlugin : IPlugin
{
public:
int getNbOutputs() const;
Dims getOutputDimensions(int index, const Dims* inputs,
int nbInputDims);
void configure(const Dims* inputDims, int nbInputs,
const Dims* outputDims, int nbOutputs,
int maxBatchSize);
int initialize();
void terminate();
size_t getWorkspaceSize(int maxBatchSize) const;
int enqueue(int batchSize, const void* inputs,
void** outputs, void* workspace,
cudaStream_t stream);
size_t getSerializationSize();
void serialize(void* buffer);
protected:
virtual ~MyPlugin() {}
};
You can build your own shared object with a custom-defined IPlugin similar to the code above. Inside the user’s enqueue() function, you can implement custom processing with CUDA kernels. TensorRT 2.1 uses this technique to implement a Faster-RCNN plugin for enhanced object detection. Additionally, TensorRT provides new RNN layers for Long Short Term Memory (LSTM) units and Gated Recurrent Units (GRU) for improved memory-based recognition of time-series sequences. Providing these powerful new layer types out of the box accelerates your deployment of advanced deep learning applications in embedded edge applications.

NVIDIA Isaac Initiative
With AI capabilities at the edge increasing quickly, NVIDIA has introduced the Isaac Initiative for advancing the state of the art in robotics and AI. Isaac is an end-to-end robotics platform for developing and deploying intelligent systems to the field, including simulation, autonomous navigation stack, and embedded Jetson for deployment. To get started with developing autonomous AI, Isaac supports the Robotic Reference Platforms shown in Figure 3. These Jetson-powered platforms include drones, unmanned ground vehicles (UGVs), unmanned surface vehicles (USVs), and human support robots (HSR). The reference platforms provide a Jetson-powered base ready for experimentation in the field, and the program will expand over time to include new platforms and robots.

Get Started Deploying AI
JetPack 3.1 includes cuDNN 6 and TensorRT 2.1. It’s available now for both Jetson TX1 and TX2. With double the low-latency performance for single-batch inference and support for new networks with custom layers, the Jetson platform is more capable than ever for edge computing. To get started developing AI, see our Two Days to a Demo series on training and deploying deep learning vision primitives like image recognition, object detection, and segmentation. JetPack 3.1 substantially improves the performance of these deep vision primitives. For more info, tune into my on-demand webinar, Breaking New Frontiers in Robotics and Edge Computing with AI.