Tutorials

June 16, 2026
Build Your Own Transaction Foundation Model for Financial Intelligence

June 16, 2026
How to Optimize Transformer-Based Models for Low-Precision Training

June 15, 2026
Boosting MoE Training Throughput with Advanced Fusion Kernels
News

June 16, 2026
Build On-Device AI Companions with the NVIDIA ACE Game Agent SDK and Unreal Engine 5 Plugins

June 16, 2026
NVIDIA Blackwell Tops MLPerf Training 6.0 with Industry-Leading Scale and Performance

June 12, 2026
NVIDIA Achieves Leading Agentic Coding Performance on First Agentic AI Benchmark

June 12, 2026
Deploy Long-Context Reasoning and Agentic Workflows with MiniMax M3 on NVIDIA Accelerated Infrastructure
Training
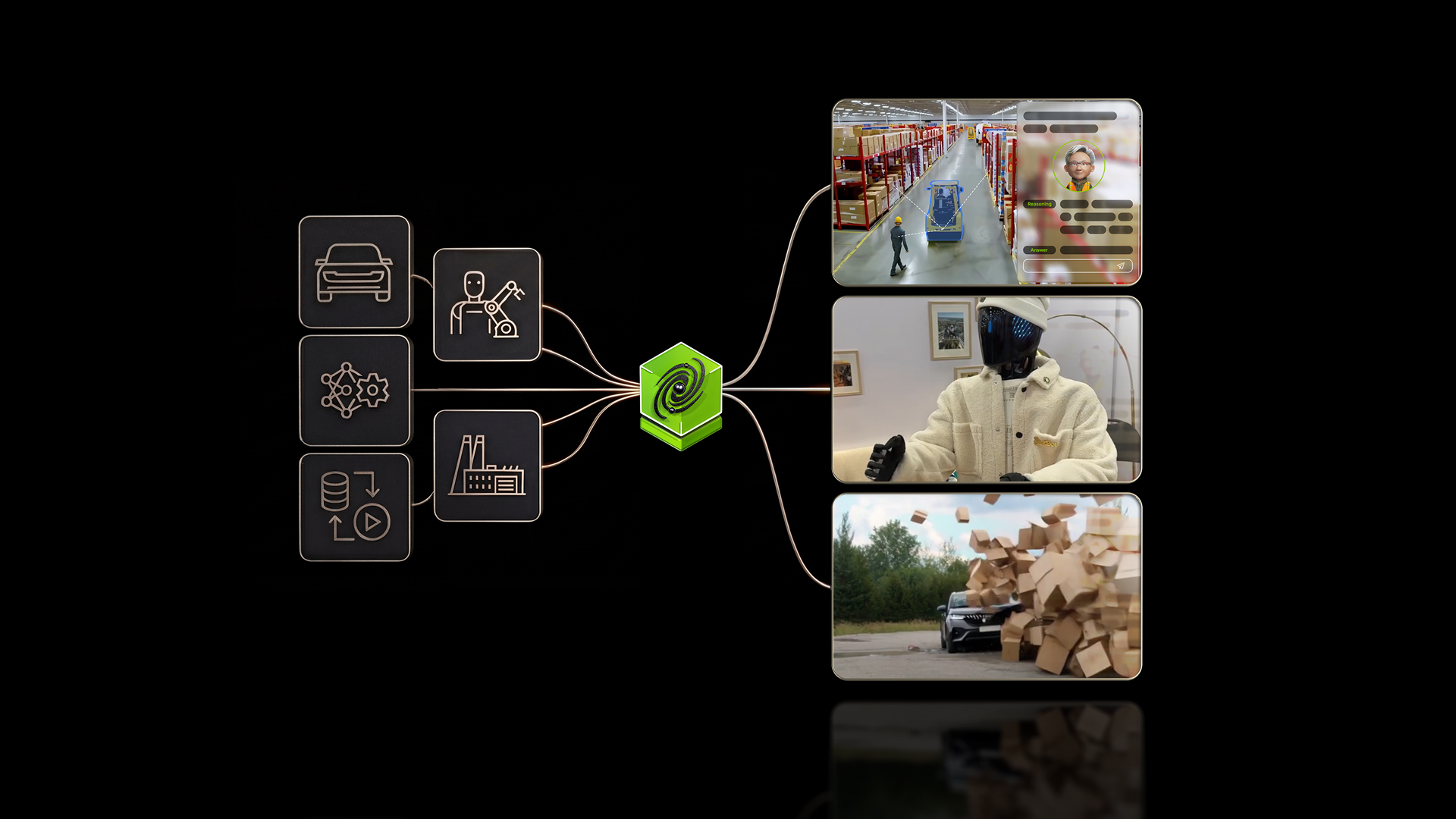
The NVIDIA Cosmos Cookoff Is Here

Global Webinar: What's New With NVIDIA Certification in 2026