
NVIDIA 开发的语音和翻译 AI 模型正在推动性能和创新的发展。NVIDIA Parakeet 自动语音识别 (ASR) 模型系列以及 NVIDIA Canary 多语种、多任务 ASR 和翻译模型在 Hugging Face 开放 ASR 排行榜 上表现出色。此外,多语种 P-Flow 基于文本转语音 (TTS) 的模型在 LIMMITS 的 24 项挑战 中取得了优异成绩,使用简短的音频片段将说话者的声音合成为 7 种语言。
本文详细介绍了其中一些出色的模型如何在语音和翻译 AI (从语音识别到自定义语音创建) 领域开辟新天地。
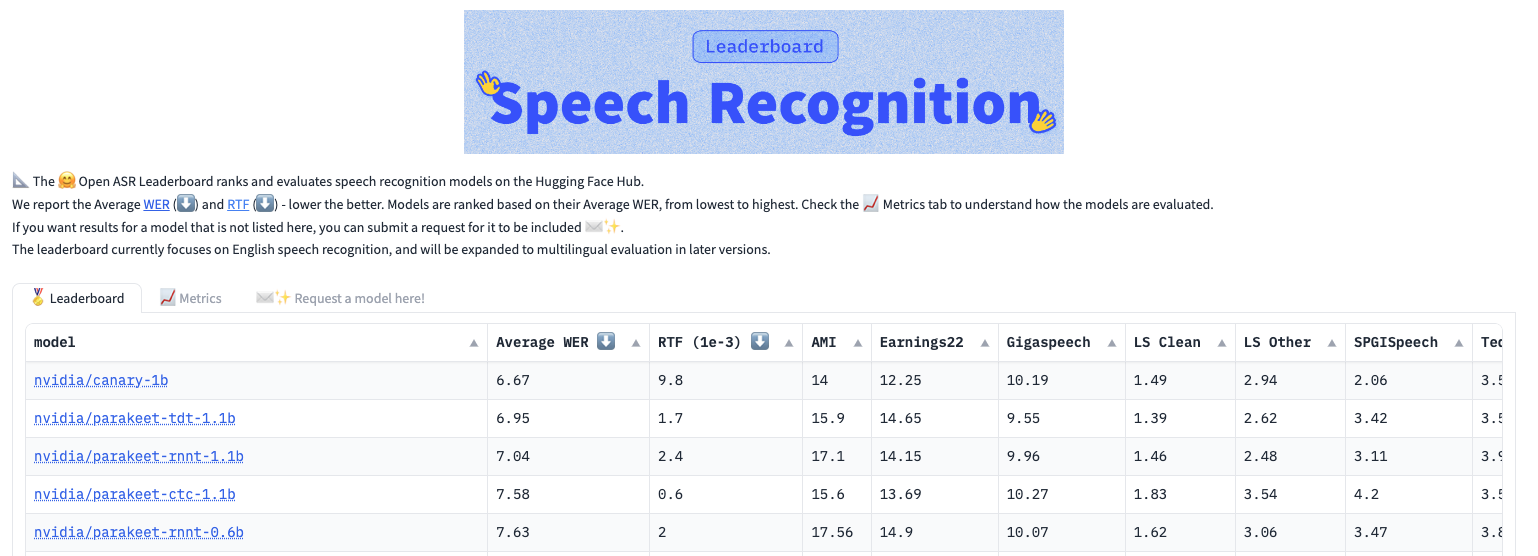
NVIDIA Parakeet 语音识别模型
NVIDIA Parakeet 模型系列包括 Parakeet CTC 1.1 B, Parakeet CTC 0.6 B, Parakeet RNNT 1.1 B, Parakeet RNNT 0.6 B 以及 Parakeet-TDT 1.1 B。这些模型提供可靠的英语语音转录,并针对不同的客户应用、准确性、速度和其他要求提供各种选项。这些模型有两种大小:6 亿个和 11 亿个参数。
Parakeet 模型的主要优势包括:
- 高准确性在不同音频来源和领域提供出色的词错误率(WER)。
- 推理速度快使用 Parakeet CTC 1.1 B、Parakeet TDT 1.1 B 和 Parakeet RNN-T 1.1 B 时,可在一小时内完成 1336 小时的音频转录。请注意,这些测量是在 Hugging Face 排行榜评估之外,使用额外的算法和 CUDA 级优化进行的。
- 出色的噪音鲁棒性到背景语音和非语音片段。
- 无缝集成和自定义:由于模型提供了即用型的预训练检查点,因此可以轻松地部署推理和微调任务。
Parakeet CTC 和 RNNT 模型的有效性在于使用快速变形器 (FC) 编码器、递归神经网络传感器 (RNNT) 和连接主义时序分类 (CTC) 解码器进行端到端训练。有关更多详细信息,请参阅 研究用于长格式音频转录的端到端 ASR 架构 和 具有线性可扩展注意力的快速变形器,可实现高效语音识别。
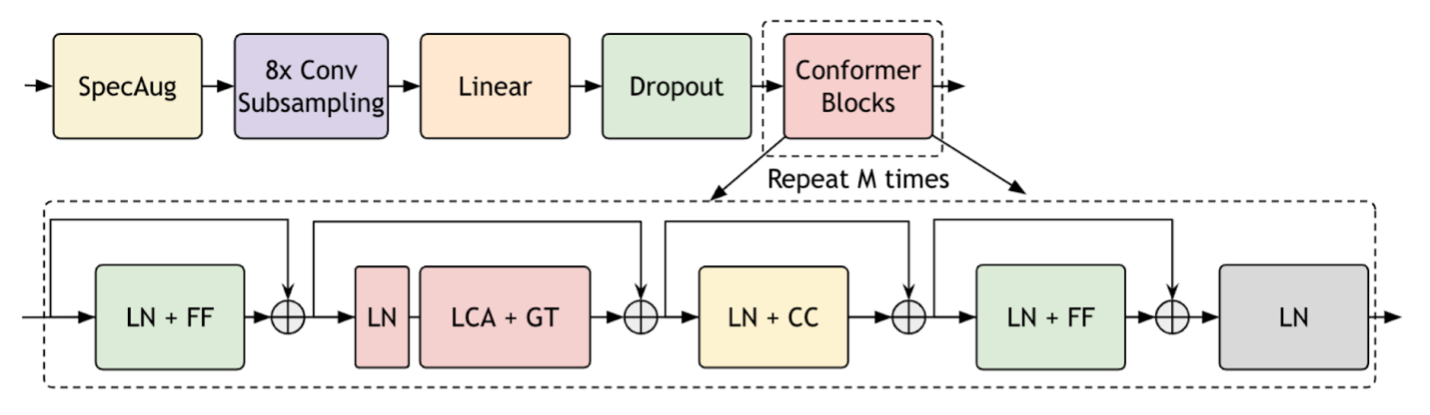
用于增强语音识别的 Parakeet-TDT 模型
我们发布的 Parakeet-TDT (令牌和持续时间传感器) 11 亿 模型在 Parakeet 系列中表现出色,它在转录英语口语时实现了最佳准确性。此外,根据 Hugging Face 排行榜的评估,该模型的运行速度比排名第二的 Parakeet 模型快 64%。
Parakeet-TDT 1.1 B 在速度和准确性方面表现优异,这得益于其 TDT 模型架构,这是一种由 NVIDIA 开发的新型序列建模架构。如需了解更多信息,请参阅 通过联合预测令牌和持续时间来高效进行序列转导。
Parakeet-TDT 1.1 B 将令牌和持续时间预测解,并使用持续时间输出跳过大多数空白预测。与传统的传感器模型相比,在识别过程中减少浪费性计算可显著加速推理,并增强对杂语音的可靠性。
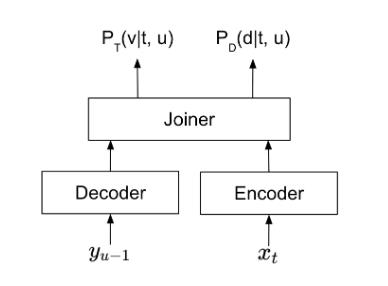
Canary 多语种语音识别和翻译模型
Canary 1B 是一个多语言多任务模型,在多个基准测试上表现出色。它能够转录英语、德语、法语和西班牙语的语音,无论是否有标点符号和大写(PnC)。它还支持德语、法语和西班牙语之间的双向英语翻译。Canary 的平均 WER 为 6.67%,这一表现远超目前所有其他模型,并在 Hugging Face 开放 ASR 排行榜 上名列前茅。
Canary 是一种基于多项创新而构建的编码器 – 解码器模型。编码器是一种快速的构象器,与构象器编码器相比,它已优化,可节省大约 3 倍的计算量和大约 4 倍的内存。
Canary 编码器处理音频的方式是对数梅尔频谱图,而 Transformer 解码器则以自动回归的方式生成输出文本标记。系统通过使用独特的标记来控制 Canary 是执行转录还是翻译。Canary 还包括连接的标记器,这使得对输出标记空间进行显式控制成为可能。想要了解更多信息,请参阅 基于连接标记器的代码交换语音识别和语言识别统一模型。
用于自定义语音创建的 P-Flow
NVIDIA 在 LIMMITS 的 24 小时语音挑战赛中夺冠,利用 P-Flow 零射 TTS 模型为扬声器创建定制的高质量个性化语音。P-Flow 可以使用短至 3 秒的语音提示。零射是指生成具有模型训练数据中未包含的扬声器语音特征的语音。P-Flow 模型创建的语音与语音提示中的语音相匹配,并且在人类肖像和语音相似性方面,与先进的同类产品相比,更受欢迎。
P-Flow 由两部分组成:用于说话者语音适应的语音提示文本编码器,以及用于快速、高质量语音合成的流匹配生成式解码器。编码器使用语音提示和文本输入来生成说话者特定的文本表示。解码器使用这种说话者特定的文本表示来合成高质量的个性化语音,其速度远超过实时语音。如需了解详情,请参阅 P-Flow:通过语音提示实现快速且数据高效的零样本 TTS。
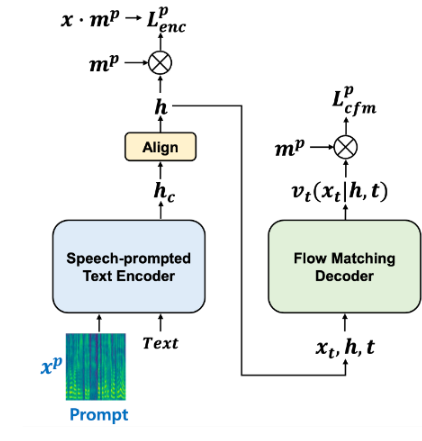
P-Flow 无需超大型数据集、复杂训练设置、表示量化步骤、预训练任务或慢自回归公式,即可创建高质量语音。
在语音挑战赛中, NVIDIA 团队将 P-Flow 的零样本 TTS 功能从其原始语言英语扩展到额外的七种印度语言。这有效地创建了一个多语言 TTS 系统,以便在 3 秒的语音提示下,不可见的说话者可以使用带有本地口音的七种目标语言中的任何一种。
以下示例展示了 NVIDIA 构建的基于 P-Flow 的多语种 TTS.首先是 Kannada 人的 3 秒钟语音样本,该模型产生的声音质量与本地印地语和英语口音相同。
输入
输入的内容是以 Kannada 为母语的人的 3 秒钟样本,他说:“得益于他们推动 AI 发展的工作,Akshit Arora 和 Rafael Valle 有朝一日可以用自己的母语与配偶的家人交谈。”
输出
输出是以印地语和英语提供的声音相似的合成语音读取输入文本。
印地语:
英语:
结束语
NVIDIA 的语音和翻译 AI 模型正在推动性能和创新的发展。借助 RNNT 和 CTC 变体,Parakeet 模型系列提供了一系列选项,可平衡准确性和速度,以满足不同的部署需求。TDT 模型将出色的准确性与前所未有的速度相结合,树立了新的基准,集中体现了语音识别的效率。
Canary 多语种模型 作为一个新的标准出现,在多种语言的语音识别和翻译方面表现出色,并且具有非常高的准确度。
我们使用 P-Flow 多语种模型支持创建自定义语音,为个性化语音合成提供快速且数据高效的解决方案。通过利用 P-Flow,NVIDIA 以出色的保真度和效率合成了多种语言的扬声器语音。
开创性的 Parakeet-CTC 和 P-Flow 模型现已推出,专为企业打造。此限制旨在防止 P-Flow 零射 TTS 可能被误用,例如,以公众人物和未经同意的个人的语音模拟的形式。
Parakeet-RNNT、Parakeet-TDT 和 Canary 模型即将作为 NVIDIA Riva 的一部分提供。通过 NVIDIA API 目录,这些模型可以在任何地方使用,无论是云、数据中心、工作站还是 PC。此外,NVIDIA NIM 提供了优化推理微服务,用于大规模部署 AI 模型。NVIDIA LaunchPad 提供了必要的硬件和软件堆栈,以便在私有基础设施上进行更多探索。
亲自或通过虚拟方式加入我们,参加 NVIDIA GTC 2024 会议,以深入了解 AI 驱动的通信的潜力:
- 语音 AI 揭秘
- 使用每种语言进行对话:TTS 模型的快速入门指南,用于有重音的多语种沟通
- 构建由 RAG 驱动的应用:使用人类语音界面
- 掌握语音 AI,实现多语种多媒体转型
- 视频会议中的安全 AI 驱动翻译
- 优化基于 Transformer 的 ASR 模型以适应电话对话
- 揭秘在 3D 场景中运行对话角色的幕后故事
- 使用 NVIDIA NeMo 工具包的多说话者 ASR:训练与推理



