NVIDIA NeMo 是一个端到端平台,用于在任何云和本地的任何地方大规模开发多模式生成 AI 模型,最近发布了 Parakeet-TDT。Parakeet-TDT 是这个新成员的其中一个,它与之前的最佳模型相比,具有更高的准确度和 64%的速度。NeMo ASR Parakeet 模型系列包括 Parakeet-TDT 和 NeMo ASR Parakeet 模型系列。
本文介绍了 Parakeet-TDT,以及如何使用它生成具有高实时系数的高精度转录,在一秒内处理 10 分钟的音频。
Parakeet-TDT 模型概述
Parakeet-TDT (令牌和持续时间传感器) 是 NVIDIA 开发的一种新型序列建模架构。最新研究表明,与传统传感器相比较,TDT 模型在速度和识别精度的方面有显著提高。有关更多详细信息,请参阅 此论文。
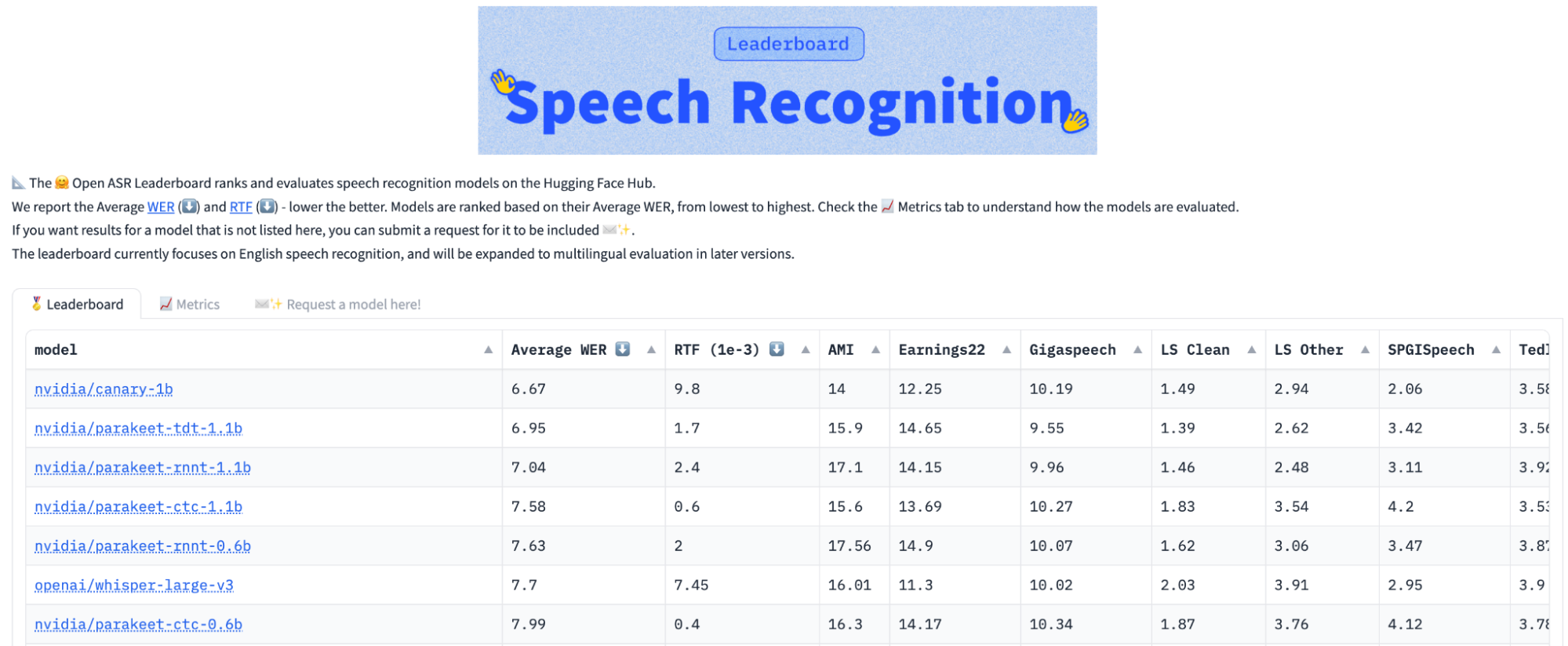
从正确性角度来看,具有 11 亿个参数的 Parakeet-TDT 在准确性方面优于类似大小的 Parakeet RNNT 1.1 B,同时运行速度快 64%,以基于 NVIDIA GPU 的 9 个基准测试的平均性能衡量。根据 HuggingFace 排行榜,Parakeet-TDT 的性能领先于其他模型。
值得注意的是,Parakeet-TDT 是首个在 Hugging Face 开放 ASR 排行榜上实现平均词错误率 (WER) 低于 7.0 的模型 (图 1)。其实时系数 (RTF) 比 Hugging Face 开放 ASR 排行榜快 40%,尽管 Parakeet RNNT 0.6 B 的模型大小约为模型大小的一半。
了解令牌和持续时间传感器模型
与传统传感器模型相比,TDT 模型取得了显著进步,因为它大幅减少了识别过程中的浪费计算。为了掌握这一改进,本部分将深入探讨典型传感器模型的工作原理。
Transducer 模型由编码器、解码器和 joiner 组成 (图 2)。在语音识别期间,编码器会处理音频信号,从每个帧中提取关键信息。解码器会从已预测的文本中提取信息。然后 joiner 会合并编码器和解码器的输出,并为每个音频帧预测文本令牌。
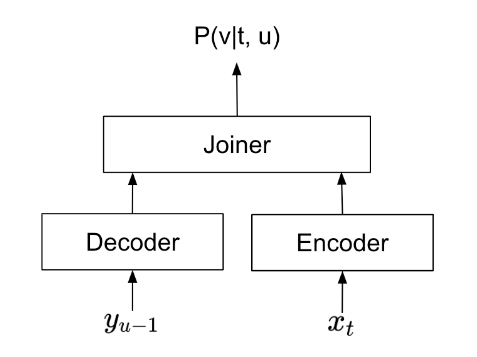
从细木工的角度来看,一帧通常会覆盖 40 到 80 毫秒的音频信号,而人们平均每 400 毫秒说一个词。由于这种差异,某些帧不会与任何文本输出相关联。对于这些帧,Transducer 会预测“空白”符号。Transducer 的典型预测序列如下所示:
“____ NVIDIA 是____a great place to work”
此处,`_`表示空白符号。要生成最终识别输出,模型将删除所有空白并生成输出:
“ NVIDIA 是理想的工作场所”
原始输出中的大量空白符号表明,Transducer 模型在“空白帧”上浪费了大量时间,即模型预测的不影响最终输出的空白帧。
TDT 旨在通过在识别过程中智能检测和跳过空白帧来减少计算浪费。如图 3 所示,当 TDT 模型处理帧时,它同时预测以下内容:
- 令牌概率
是应在当前帧中预测的令牌。
- 持续时间概率
是当前令牌在模型做出下一个令牌预测之前所持续的帧数。
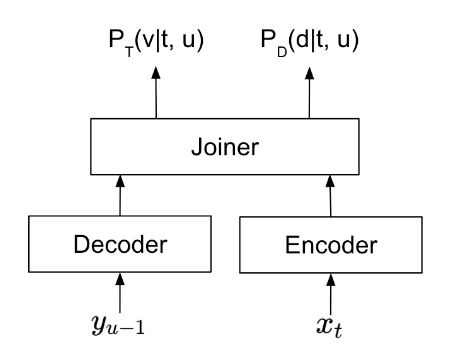
经过训练的 TDT 模型可使用持续时间预测最大限度地提高跳过的帧数,同时保持相同的识别准确性。在之前的示例中,与预测每个语音帧的令牌的传统传感器不同,TDT 模型可以按以下步骤简化该过程:
frame 1: predict token=_, duration=4 frame 5: predict token=NVIDIA, duration=5 frame 10: predict token=is, duration=4 frame 14: predict token=a, duration=3 frame 17: predict token=great, duration=6 frame 23: predict token=place, duration=5 frame 28: predict token=to, duration=1 frame 29: predict token=work, duration=4 frame 33: reach the end of audio, recognition completed. |
在该示例中,TDT 可以将模型必须作出的预测数量从 33 个减少到 8 个。对 TDT 模型进行的大量实验表明,这种优化确实会大幅提高识别速度。此外,与传统的 Transducer 模型相比,TDT 模型对文本中的杂语音和令牌重复表现出更强的可靠性。
请注意,为了更清晰地说明传感器和 TDT 之间的设计差异,本文简化了传感器模型的部分技术细节。有关更多技术细节,请参阅 高效序列转导:通过联合预测令牌和持续时间。
如何使用 Parakeet-TDT
为了使用 Parakeet-TDT 运行语音识别,您需要安装 NVIDIA NeMo。它可作为 pip 包安装。安装前,请确保已安装 Cython 和 PyTorch (2.0 及更高版本)。
pip install nemo_toolkit['asr'] |
安装 NeMo 后,您可以使用 Parakeet-TDT 识别音频文件,如下所示:
import nemo.collections.asr as nemo_asr asr_model = nemo_asr.models.ASRModel.from_pretrained(model_name="nvidia/parakeet-tdt-1.1b") transcript = asr_model.transcribe(["some_audio_file.wav"]) |
结束语
Parakeet-TDT 是 NVIDIA Omniverse 的 NeMo Parakeet ASR 模型系列中的一款。它通过结合出色的准确性与前所未有的速度,树立了新的基准,集中体现了语音识别的效率。更多信息请参阅 此处。
有关 Parakeet-TDT ASR 模型架构的详细信息,请参阅以下论文:
– Through Joint Prediction of Tokens and Durations for Efficient Sequence Transduction
– Fast Transformer with Linear Scalable Attention for Efficient Speech Recognition
– Research on End-to-End ASR Architectures for Long-Format Audio Transcription
Parakeet-CTC 模型现在已集成在最新版本的 NeMo ASR 中。未来,其他模型也将作为 NeMo ASR 的一部分提供。有关 NVIDIA Riva 的更多信息,请参阅 NVIDIA Riva。有关 Parakeet-TDT 模型的更多信息,请访问 NVIDIA/NeMo 的 GitHub 存储库。您还可以通过 NVIDIA API 目录 在本地使用 NVIDIA NIM。NVIDIA LaunchPad 提供必要的硬件和软件堆栈,以进行更深入的探索。