
NVIDIA NeMo 是一种端到端平台,用于开发和部署多模态 生成式 AI 模型。它可以随时随地进行大规模模型部署。
NeMo 团队最近发布了 Canary,这是一款多语言模型,可转录英语、西班牙语、德语和法语的语音,并添加标点符号和大写。Canary 还提供英语和其他三种受支持语言之间的双向翻译。
本文详细介绍了 Canary 模型及其使用方法。
Canary 概述
Canary 模型在 HuggingFace 开放 ASR 排行榜 中平均词错误率 (WER) 为 6.67%,其性能远远优于所有其他开源模型。
Canary 结合使用公共和内部数据进行训练。它使用 85000 小时的转录语音来学习语音识别。为了教授 Canary 翻译,我们使用 NVIDIA NeMo 文本翻译模型生成所有支持语言的原始转录的翻译。
尽管数据量比类似规模的模型少一个数量级,但 Canary 的性能优于 Whisper-large-v3 和 SeamlessM4T-Medium-v1 模型在 MCV 16.1 英语、西班牙语、法语和德语测试集上的 WER 分别为 5.77 (图 1)。
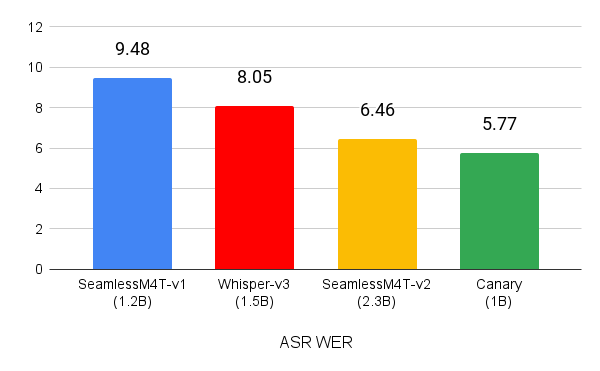
(越低越好)
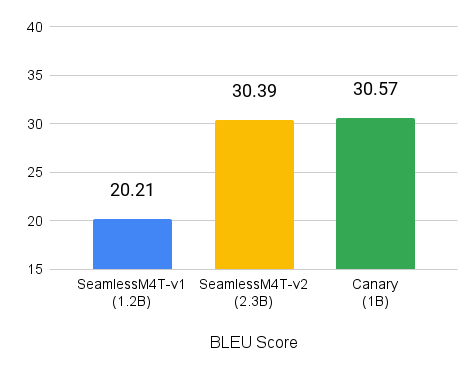
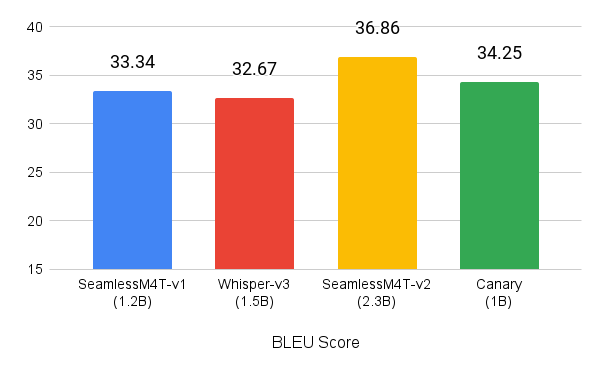
您可以尝试 canary-1b 模型的 Gradio 演示。有关如何在本地访问 Canary 并进行构建的更多信息,请参阅 NVIDIA/NeMo GitHub 库。
Canary 架构
Canary 是一种基于 NVIDIA 创新技术构建的编码器 – 解码器模型。
编码器 Fast-Conformer 是一种高效的 Conformer 架构,经过优化,可节省大约 3 倍的计算和大约 4 倍的内存。编码器以对数 – 梅尔频谱图特征的形式处理音频,Transformer 解码器以自动回归的方式生成输出文本标记。系统会提示解码器使用特殊标记来控制 Canary 执行转录还是翻译。
Canary 还集成了 连接的分词器,以提供对输出令牌空间的显式控制。
模型权重以研究友好型非营利 CC BY-NC 4.0 许可证分发,而用于训练此模型的代码可通过 Apache 2.0 许可证获得。许可证信息可参考 NeMo。
如何使用 Canary 转录
要使用 Canary,请将 NeMo 安装为 pip 包。在安装 NeMo 之前,请先安装 Cython 和 PyTorch (2.0 及更高版本)。
pip install nemo_toolkit['asr'] |
安装 NeMo 后,使用 Canary 转录或翻译音频文件:
# Load Canary modelfrom nemo.collections.asr.models import EncDecMultiTaskModelcanary_model = EncDecMultiTaskModel.from_pretrained('nvidia/canary-1b') # Transcribetranscript = canary_model.transcribe(audio=["path_to_audio_file.wav"])# By default, Canary assumes that input audio is in English and transcribes it.# To transcribe in a different language, such as Spanishtranscript = canary_model.transcribe( audio=["path_to_spanish_audio_file.wav"], batch_size=1, task='asr', source_lang='es', # es: Spanish, fr: French, de: German target_lang='es', # should be same as "source_lang" for 'asr' pnc=True )# To translate using Canary. For example, from English audio to French texttranscript = canary_model.transcribe( audio=["path_to_english_audio_file.wav"], batch_size=1, task='ast', source_lang='en', target_lang='fr', pnc=True ) |
结束语
我们所开发的 Canary 多语言模型已成为新标准,在英语、西班牙语、德语和法语的语音识别和翻译方面表现出色,准确度极高。
有关 Canary 架构的更多信息,请参阅以下资源:
要深入了解 canary-1b,您可以:
– 探索 Gradio 演示。
– 通过 NVIDIA/NeMo GitHub 库。
Parakeet-CTC 已经发布,其他模型将在 NVIDIA Riva 推出时发布。
通过 NVIDIA API 目录,您可以在本地使用 NVIDIA NIM。更多信息请参阅 NVIDIA LaunchPad,它提供了专用托管基础设施上的硬件和软件堆栈。
致谢:
感谢所有为本文做出贡献的模型作者:Krishna Puvvada、Piotr Zelasko、He Huang、(Steve) Oleksii Hrinchuk、Nithin Koluguri、Somshubra Majumdar、Elena Rastorgueva、Kunal Dhawan、Zhehuai Chen、Vitaly Lavrukhin、Jagadeesh Balam、Boris Ginsburg



