
According to the American Society of Quality (ASQ), defects cost manufacturers nearly 20% of overall sales revenue. The products that we interact with on a daily basis—like phones, cars, televisions, and computers—must be manufactured with precision so that they can deliver value in varying conditions and scenarios.
AI-based computer vision applications are helping to catch defects in the manufacturing process much faster and more effectively than traditional methods, enabling companies to increase yield, deliver products with consistent quality, and reduce false positives. In fact, 64% of manufacturers today have deployed AI to help with day-to-day activities, and 39% of those use AI for quality inspection, according to a Google Cloud Manufacturing report.
The AI models that power these vision applications must be trained and tuned to predict specific defects across many use cases such as the following:
- Automotive manufacturing defects like cracks, paint flaws, or misassembly
- Semiconductor and electronics defects like misaligned components on PCB, broken or excess solder joints, or foreign bodies such as dust or hair
- Telecommunications defects like cracks, corrosion on cellular towers, and poles
Training perception AI models requires collecting images of specific defects, which is difficult and expensive to do in a production environment.
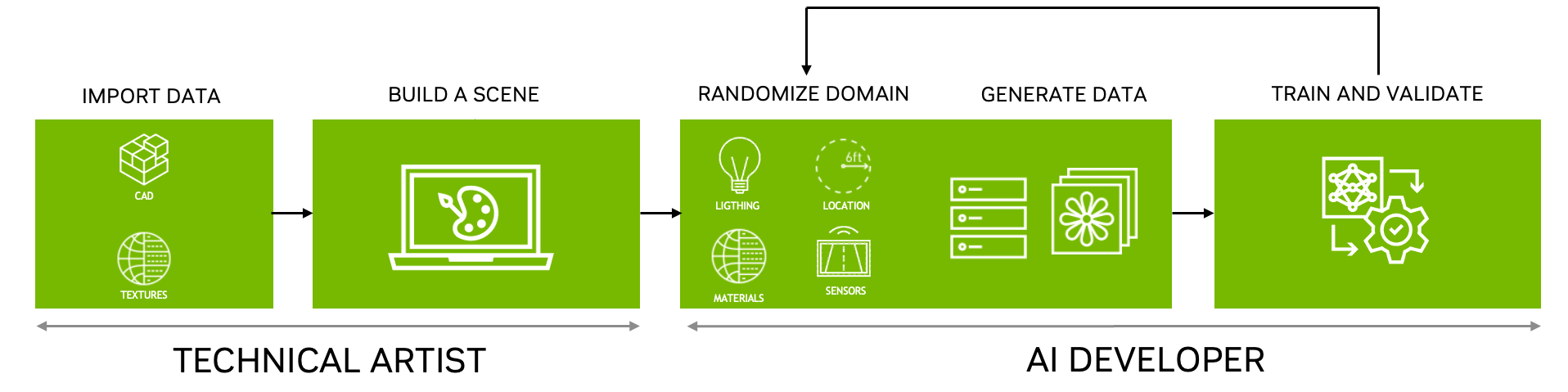
NVIDIA Omniverse Replicator can help overcome the data challenge by generating synthetic data to bootstrap the AI model training process. Replicator is an extensible foundation application in NVIDIA Omniverse, a computing platform that enables individuals and teams to develop Universal Scene Description (USD)–based 3D workflows and applications.
You can use Omniverse Replicator to easily generate diverse data sets by varying many parameters such as types of defects, locations, ambient lighting, and more to bootstrap and speed up model training and iteration of the model. For more information, see Develop on NVIDIA Omniverse.
This post explains how you can train an object detection model entirely with synthetic data, further improve its accuracy with limited ground truth data, and validate it against images that the model has never seen before. Using this method, we demonstrate the value of overcoming the lack of real data with synthetic data and show how to reduce the simulation-to-reality gap during model training.
Developing the defect detection model
This example generates scratches on a car panel (front nose cone), as shown in Figure 1. This workflow requires the following resources:
- Adobe Substance 3D Designer or a pre-generated library of scratches
- NVIDIA Omniverse
- A downloaded USD-based sample

The overall workflow starts with creating a set of defects—scratches, in this case—in Adobe Substance 3D Designer and importing these with a CAD part into NVIDIA Omniverse. The CAD part is then placed into a scene (a manufacturing floor or a workshop, for example) with sensors or cameras placed in the desired location.
After the scene is set up, defects are procedurally applied onto the CAD part using NVIDIA Omniverse Replicator, which generates annotated data that is then used to train and evaluate the model. This iterative process continues until the model has achieved the desired KPIs.
Creating a scratch
Scuffs and scratches are common surface defects that occur in manufacturing. A texture-mapping technique called a normal map is used to represent these textures in a 3D environment. A normal map is an RGB image representation of height information that corresponds directly with the X, Y, and Z axes relative to a surface in a 3D space.
The normal maps used for this example were created in Adobe Substance 3D Designer, but it is also possible to generate them in most modeling software, such as Blender or Autodesk Maya.

Although it is possible to randomize the size and position of the scratch after it has been brought into Omniverse, it is better to build an entire library of normal maps saved into a folder to generate a robust set of synthetic data. These normal maps should be of various shapes and sizes, representing scratches of varying severity.
Setting up the scene
Now, it is time to set up the scene. First, open Omniverse Code to import the CAD model of the part. For this example, we imported a SOLIDWORKS.SLDPRT file of the nose panel of the RX3 racer from Sierra Cars.

After importing the CAD file into Omniverse, set up the background of the scene to be as close to the environment of the ground truth data as possible. In this case, we used a LiDAR scan of the workshop.
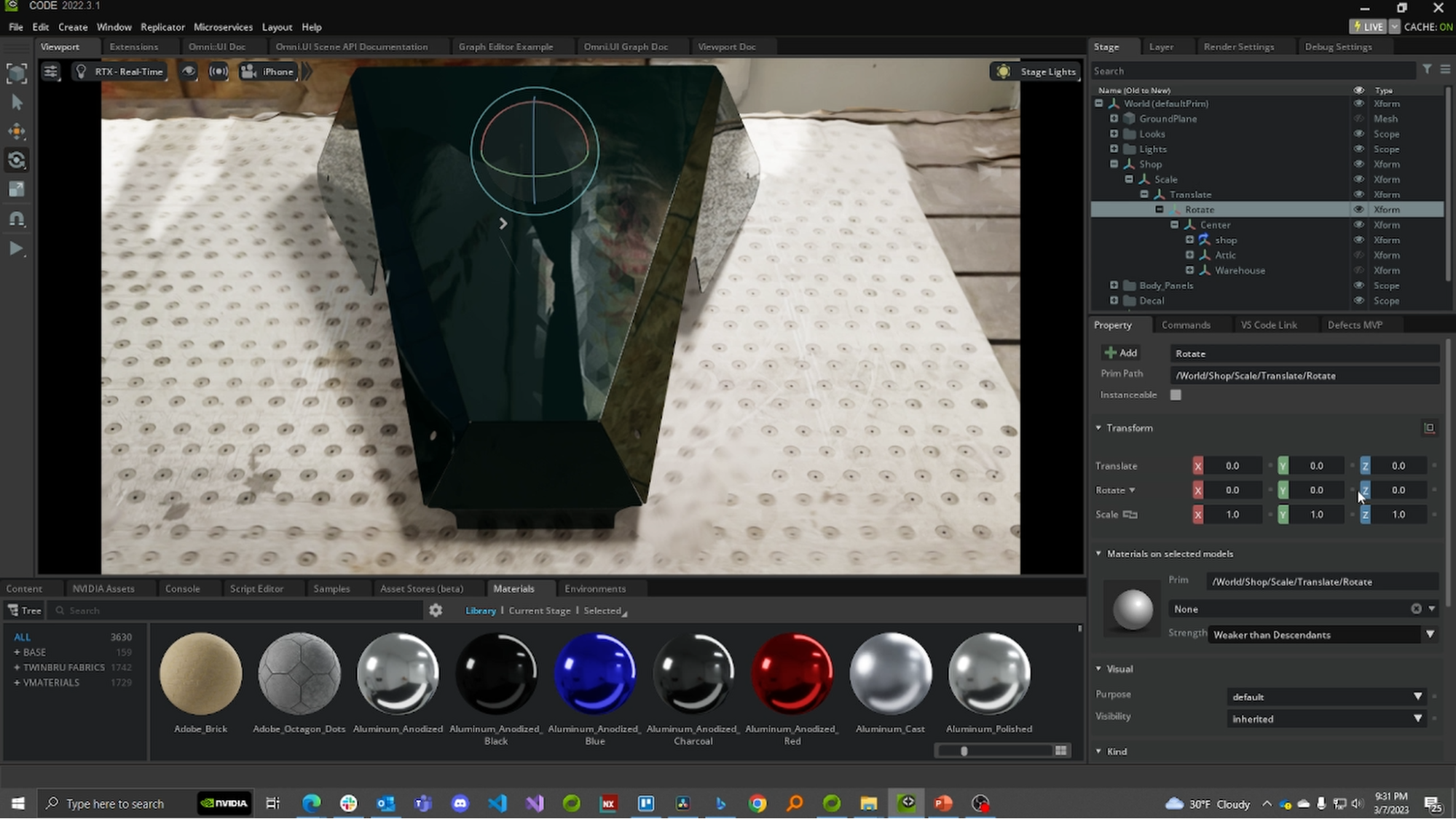
For ease of replication, we consolidated the background and CAD model into a USD scene available for download on Omniverse Exchange.
Use an extension to randomize the scratch
To create a diverse set of training data for the model, it is necessary to generate a variety of synthetic scratches. This example uses a reference extension built on Omniverse Kit to randomize the location, size, and rotation of the scratches. For more information, see NVIDIA-Omniverse/kit-extension-sample-defectsgen on GitHub.
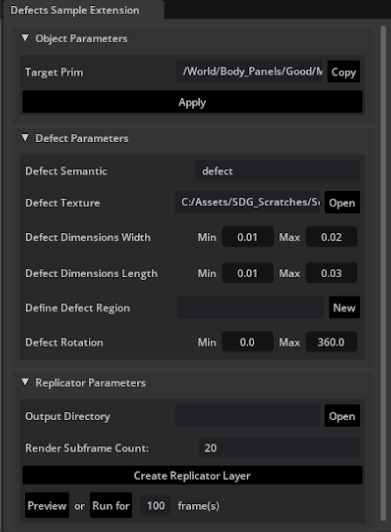
This reference extension was built to manipulate a proxy object that projects the normal map as a texture onto the surface of the CAD part. By changing the parameters in the extension, it is actually changing the size and shape of the cube projecting the texture.

After running the extension with the desired parameters, the output is a set of annotated reference images saved into a folder (which can be defined through the extension) as .png, .json, and .npy files.
Model training and validation
The outputs from the Omniverse extension are standard file formats that can be used with many local or cloud-based model training platforms, but a custom writer may be built to format the data for use with specific models and platforms.
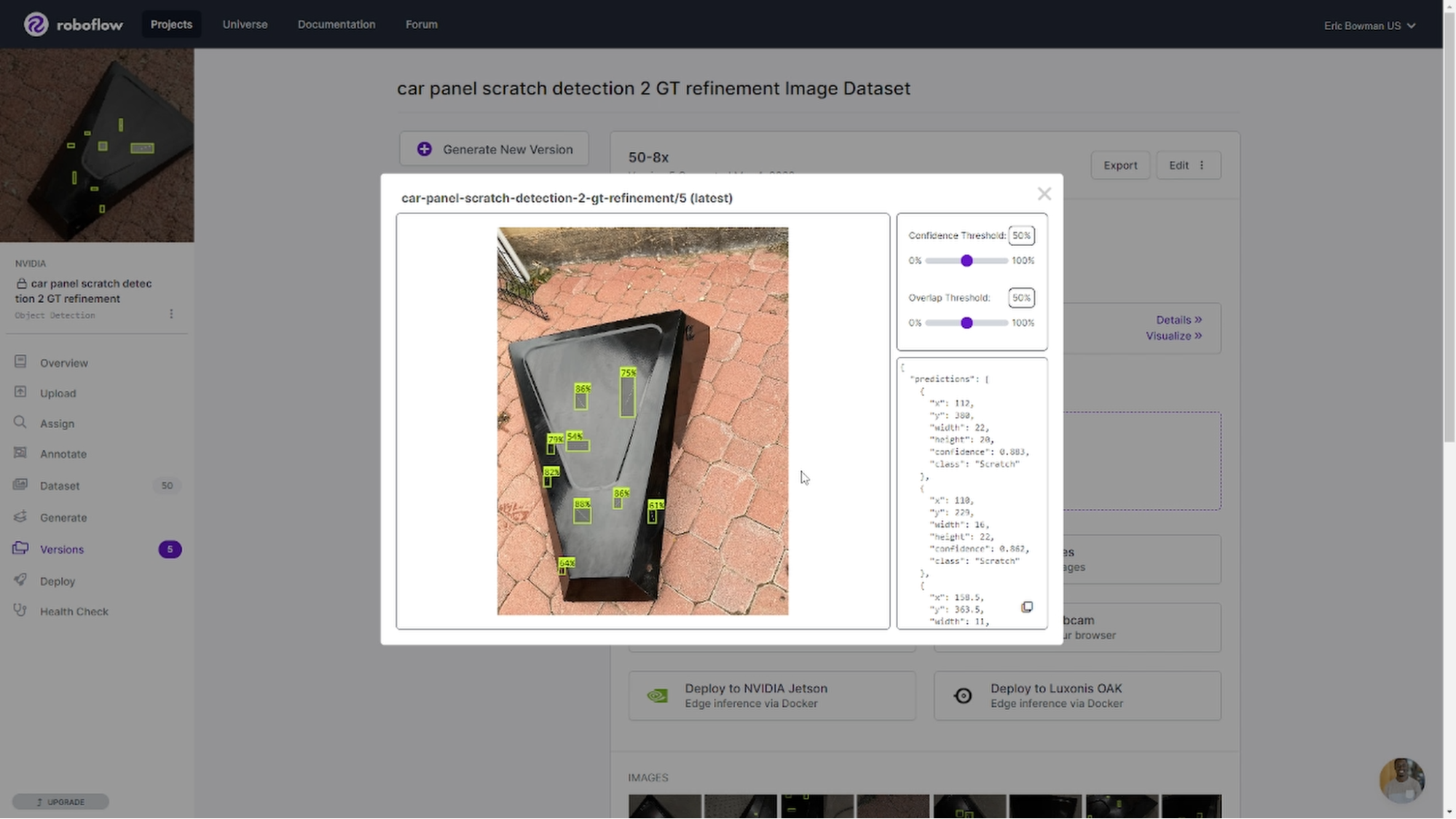
For this demonstration, we built a custom COCO JSON writer to bring the outputs into Roboflow, a browser-based platform for training and deploying computer vision models.
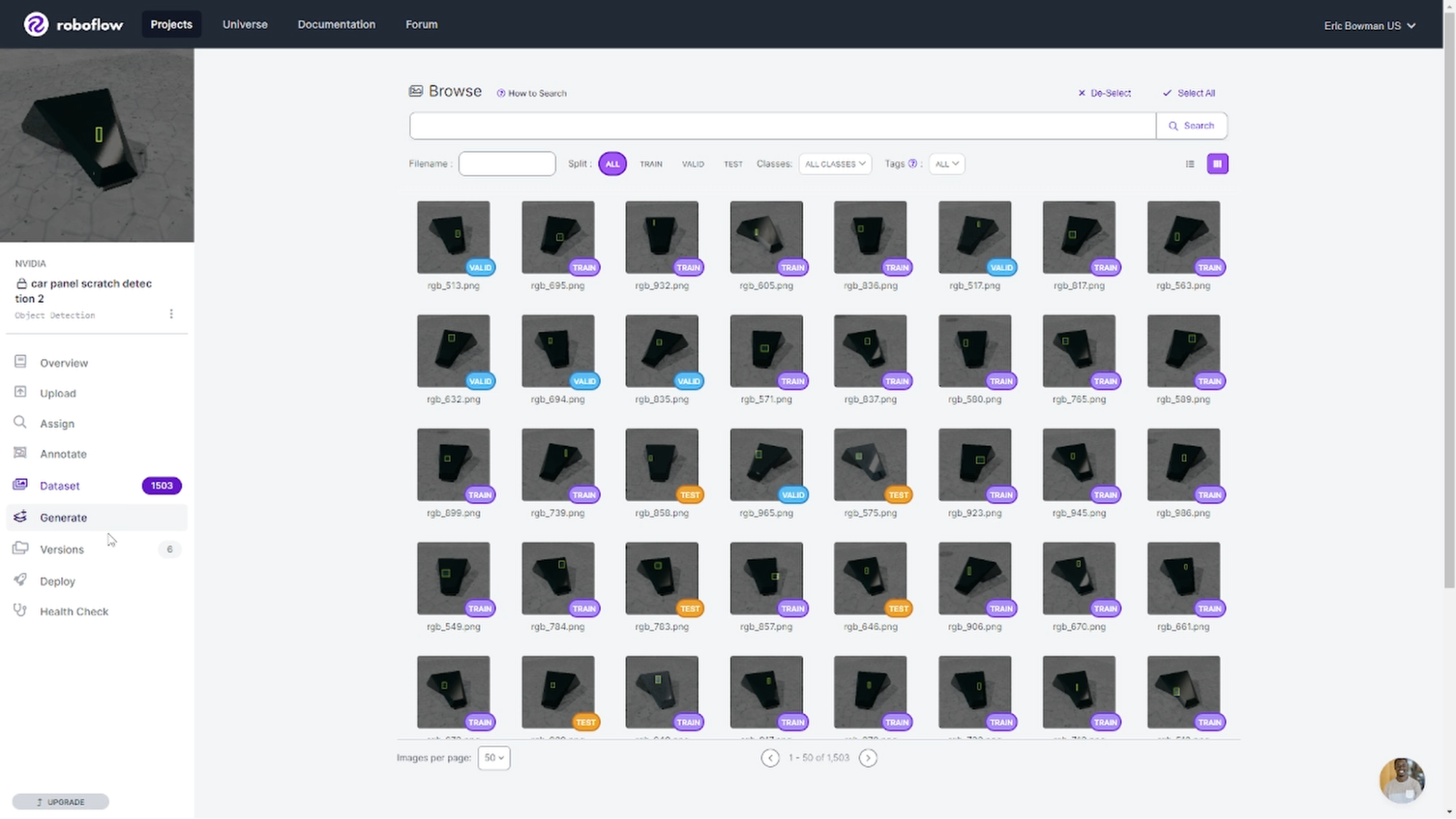
Through the Roboflow user interface, we started with a set of 1,000 synthetic images to train a YOLOv8 model, chosen for its object detection speed. This was just a starting point to see how the model performed with this data set. Given that the model training is an iterative process, it is good practice to start small and build on improving the size and diversity of the data set with each iteration.

The results of the initial models were promising, but not perfect (Figure 9). A few observations with the initial model include the following:
- Long scratches were not detected well
- Reflective edges were captured
- Scratches on the workshop floor were also included
Here are some possible remediation steps to address each of these issues:
- Adjusting extension parameters to include longer scratches
- Including more angles of the part within the generated scene
- Varying the lighting and background scenes
Augmenting the synthetic data with ground truth images is another tactic. Although the files from Replicator were automatically annotated, we used the Roboflow built-in tools for manual annotation.
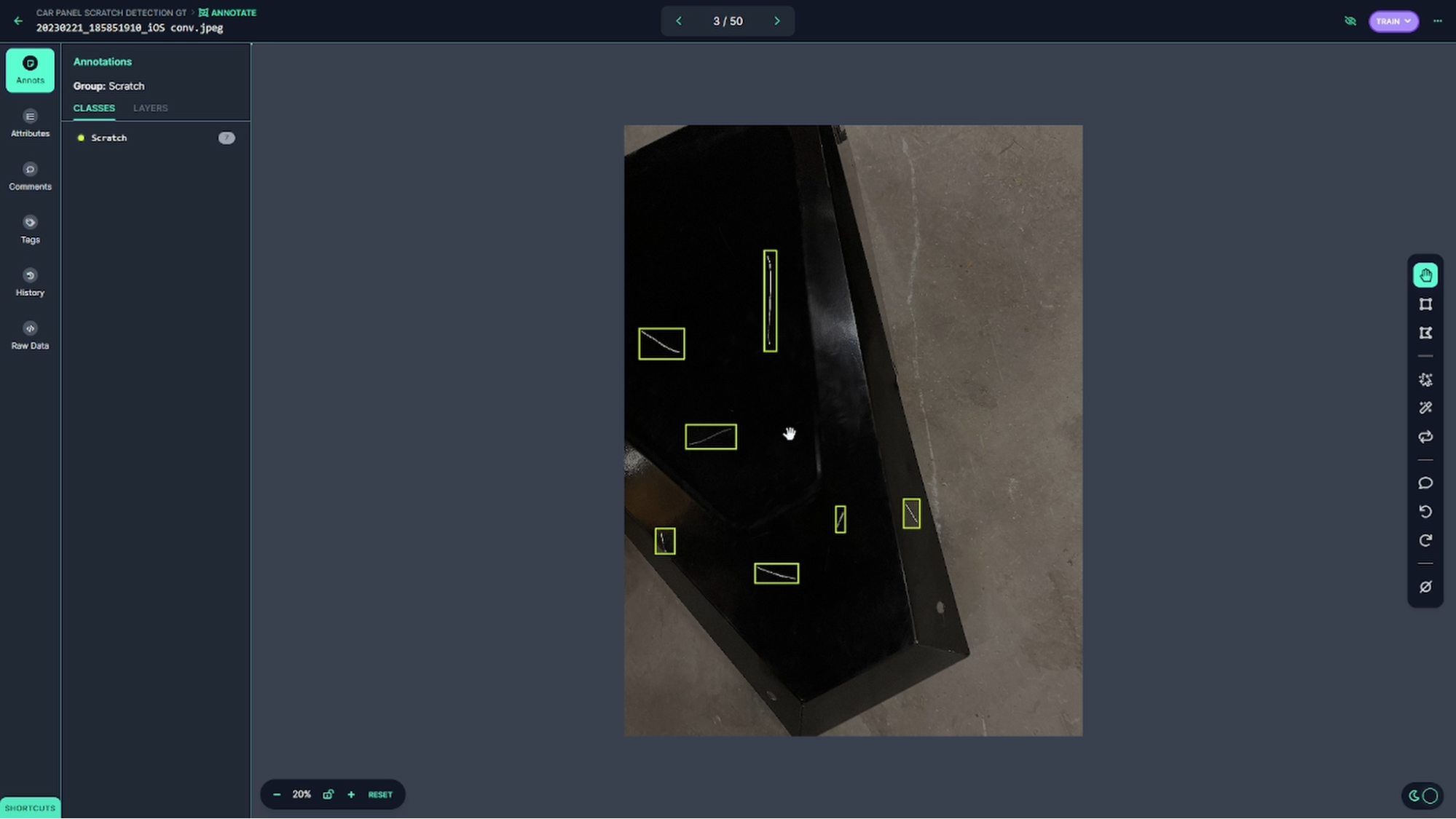
With some of the tweaking described earlier, we trained the model to pick up more scratches on each validation image, even at higher confidence thresholds.
Get started
In a real-world setting, it is not always possible to acquire more ground truth images. You can close the sim-to-real gap using synthetic data generated with NVIDIA Omniverse Replicator.
To get started generating synthetic data on your own, download NVIDIA Omniverse.
You can download and install the reference extension from GitHub and use Omniverse Code to explore the workflow. Then build your own defect detection generation tool by modifying the code. Accompanying USD files and sample content can be accessed through the Defect Detection demo pack on Omniverse Exchange. For more information about the extension, see Defect Detection.
Get started with NVIDIA Omniverse by downloading the standard license for free, or learn how Omniverse Enterprise can connect your team. If you are a developer, get started with Omniverse resources. Stay up to date on the platform by subscribing to the newsletter, and following NVIDIA Omniverse on Instagram, Medium, and Twitter. For resources, check out our forums, Discord server, Twitch, and YouTube channels.
