
AI is rapidly changing industrial visual inspection. In a factory setting, visual inspection is used for many issues, including detecting defects and missing or incorrect parts during assembly. Computer vision can help identify problems with products early on, reducing the chances of them being delivered to customers.
However, developing accurate and versatile object detection models remains challenging for edge AI developers. Robust object detection models require access to comprehensive and representative datasets. In many manufacturing scenarios, real-world datasets fall short when capturing the complexity and diversity of actual scenarios. The constraints of narrow environments and limited variations pose challenges in training models to adapt to a range of situations effectively.
Teams can harness synthetic data for training models on diverse, randomized data that closely resemble real-world scenarios and address dataset gaps. The result is more accurate and adaptable AI models that can be deployed for a wide range of edge AI applications in industrial automation, healthcare, and manufacturing, to name a few.
From synthetic data generation to AI training
Edge Impulse is an integrated development platform that empowers developers to create and deploy AI models for edge devices. It supports data collection, preprocessing, model training, and deployment, helping users integrate AI capabilities into their applications effectively.
With NVIDIA Omniverse Replicator, a core extension of NVIDIA Omniverse, users can produce physically accurate and photorealistic, synthetically generated annotated images in Universal Scene Description, known as OpenUSD. These images can then be used for training an object detection model on the Edge Impulse platform.
NVIDIA Omniverse is a computing platform that enables individuals and teams to develop Universal Scene Description (OpenUSD)-based 3D workflows and applications.
OpenUSD is a highly versatile and interoperable 3D interchangeable and format that excels in synthetic data generation due to its scalability, performance, versioning, and asset management capabilities, making it an ideal choice for creating complex and realistic datasets. There’s a vast ecosystem of 3D content tools that connect to OpenUSD and USD-based SimReady assets that make it easy to integrate physically-based objects into scenes and accelerate our synthetic data generation workflows.
Omniverse Replicator enables randomization for USD data across several domains to represent scenarios that reflect real-world possibilities object detection models may encounter.
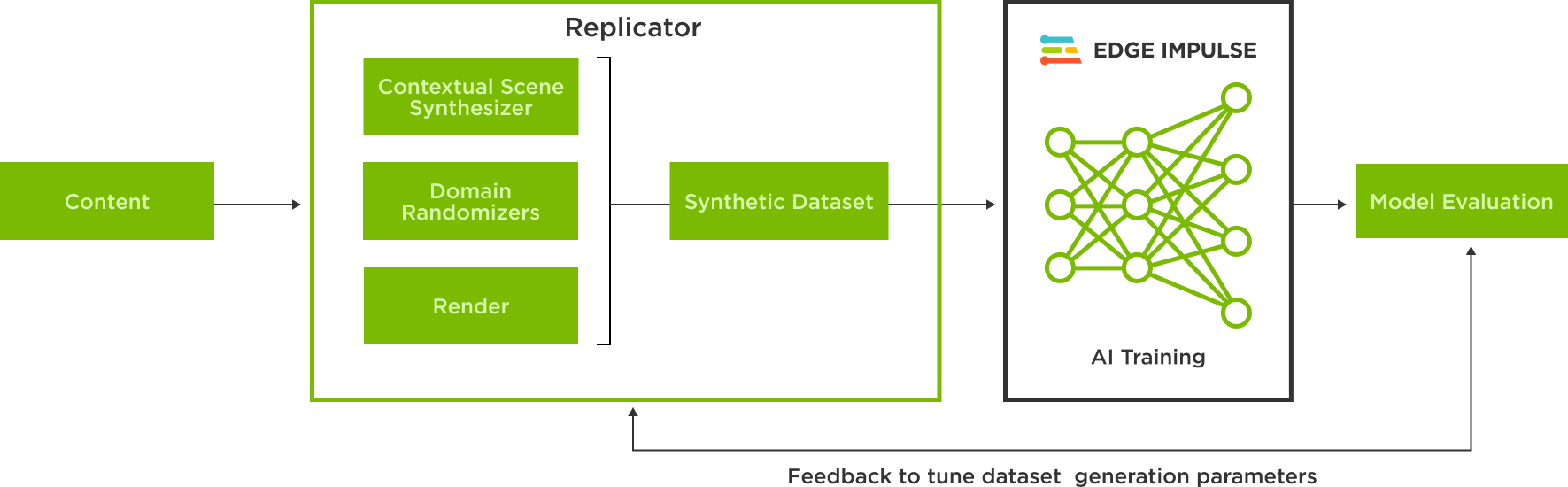
Using the synthetically generated images in USD to train models in Edge Impulse only takes a few clicks with the new Edge Impulse Omniverse extension.
Using the extension, which was developed using the Omniverse Kit Python extension template, users can connect to the Edge Impulse API and select the dataset to upload their synthetic data. The Kit Python extension template is a simple and self-explanatory resource for code snippet options and developing an extension quickly.
Generating synthetic data for an object detection model
To understand the workflow for generating synthetic data with Omniverse Replicator and using it to train a model in Edge Impulse, follow our example detecting soda cans model.

The first step in the process is building a virtual replica or a digital twin of the environment that represents the real scenario. The scene for generating synthetic images consists of movable and immovable objects. The immovable set includes lights, a conveyor belt, and two cameras, while the movable objects consist of soda cans. Employing domain randomization, you can alter many properties, including location, lighting, colors, texture, background, and foreground of select immovable and movable objects.
These assets are represented in Omniverse Replicator through OpenUSD. 3D model files can be converted into USD and imported into Omniverse Replicator using the Omniverse CAD Importer extension.
Lighting plays a pivotal role in realistic image generation. Rectangular lights can emulate light generated from a panel and a dome light brightens the entire scene. You can randomize various parameters for the lights like temperature, intensity, scale, position, and rotation of the lights.
The following script shows temperature and intensity randomized through sampling from normal distributions, with scales randomized by a uniform distribution. The position and rotation of lights are fixed to remain constant.
python
# Lightning setup for Rectangular light and Dome light
def rect_lights(num=1):
lights = rep.create.light(
light_type="rect",
temperature=rep.distribution.normal(6500, 500),
intensity=rep.distribution.normal(0, 5000),
position=(45, 110, 0),
rotation=(-90, 0, 0),
scale=rep.distribution.uniform(50, 100),
count=num
)
return lights.node
rep.randomizer.register(rect_lights)
def dome_lights(num=3):
lights = rep.create.light(
light_type="dome",
temperature=rep.distribution.normal(6500, 500),
intensity=rep.distribution.normal(0, 1000),
position=(45, 120, 18),
rotation=(225, 0, 0),
count=num
)
return lights.node
rep.randomizer.register(dome_lights)Most scenes have immovable objects important to the environment, like a table or in this case, a conveyor belt. The position of these objects can be fixed, while the material of the objects can be randomized to reflect real-world possibilities.
The following script generates a conveyor belt in USD that the cans will be placed upon. It also fixes its position and rotation. In this example, we don’t randomize the material of the conveyor belt.
python
# Import and position the conveyor belt
conveyor = rep.create.from_usd(CONVEYOR_USD, semantics=[('class', 'conveyor')])
with conveyor:
rep.modify.pose(
position=(0, 0, 0),
rotation=(0, -90, -90),
)To guarantee a high-quality dataset, it’s a good idea to use multiple cameras with different resolutions, and position them strategically in the scene. The position of the cameras can also be randomized. This script sets up two cameras of different resolutions strategically placed at various locations in the scene.
# Multiple setup cameras and attach to render products
camera = rep.create.camera(focus_distance=focus_distance, focal_length=focal_length,
position=cam_position, rotation=cam_rotation, f_stop=f_stop)
camera2 = rep.create.camera(focus_distance=focus_distance2, focal_length=focal_length2,
position=cam_position2, rotation=cam_rotation, f_stop=f_stop)
# Render images
render_product = rep.create.render_product(camera, (1024, 1024))
render_product2 = rep.create.render_product(camera2, (1024, 1024))
The last step is randomizing the position of the movable objects while also keeping them in the relevant area. In this script, we initialize five instances of 3D-can models, randomly selected from a collection of available can assets.
cans = list()
for i in range(TOTAL_CANS):
random_can = random.choice(cans_list)
random_can_name = random_can.split(".")[0].split("/")[-1]
this_can = rep.create.from_usd(random_can, semantics=[('class', 'can')])
with this_can:
rep.modify.pose(
position=(0, 0, 0),
rotation=(0, -90, -90)
)
cans.append(this_can)Then, the pose of the cans is randomized and scattered across two planes, keeping the cans on the conveyor belt while avoiding collisions.
with rep.trigger.on_frame(num_frames=50, rt_subframes=55):
planesList=[('class','plane1'),('class','plane2')]
with rep.create.group(cans):
planes=rep.get.prims(semantics=planesList)
rep.modify.pose(
rotation=rep.distribution.uniform(
(-90, -180, 0), (-90, 180, 0)
)
)
rep.randomizer.scatter_2d(planes, check_for_collisions=True)
Annotating data, building the model, and testing with real objects
After being generated, the images can be uploaded to Edge Impulse Studio in a few clicks with the Edge Impulse Omniverse extension. In Edge Impulse Studio, datasets can be annotated and trained using models, such as the Yolov5 object detection model. The version control system enables model performance tracking across different dataset versions and hyperparameters, to optimize precision.
To test model accuracy with real-world objects, you can stream live video and run the model locally using the Edge Impulse CLI tool.
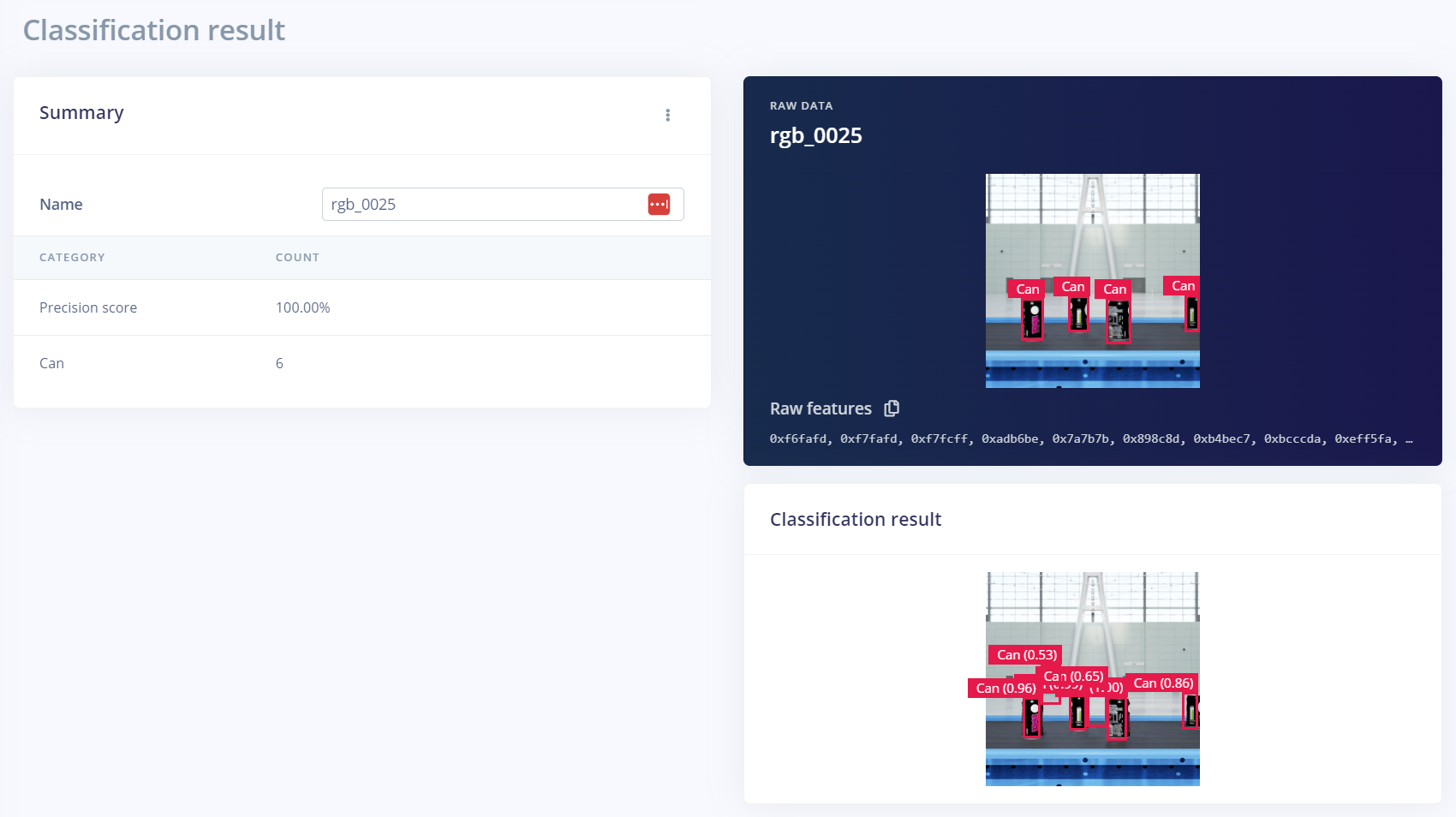
If the model does not detect the objects accurately, the model must be trained on additional datasets. This iterative process is the norm when it comes to AI model training. An added benefit of synthetic data is that required variations in subsequent iterations can be done programmatically.
In this example, an additional synthetic dataset was generated and used to train the model to improve performance. The additional dataset used a camera distance further from the conveyor. Other parameters like the angle of the camera and materials can be modified in additional datasets to improve performance.
Taking a data-centric approach, where you create more data around the failure points of the model, is crucial to solving ML problems. Additional training and fine-tuning of parameters can enable a model to generalize well across different orientations, materials, and other relevant conditions.
Get started training and deploying edge AI with synthetic data
Generating physically accurate synthetic data is easy with OpenUSD and NVIDIA Omniverse. Simply download Omniverse free and follow the instructions for getting started with Replicator in Omniverse Code.
With Edge Impulse, you can use synthetic data generated in Omniverse to train your ML models. Sign up and begin using embedded machine learning models today.
Stay up to date with NVIDIA Omniverse by subscribing to the newsletter, and following us on Instagram, Medium, LinkedIn, and Twitter. For more resources, check out our forums, Discord server, Twitch, and YouTube channels. See NVIDIA at CVPR 2024 to catch the latest research on synthetic data generation for computer vision.
