

Implementing quality control and assurance methodology in manufacturing processes and quality management systems ensures that end products meet customer requirements and satisfaction. Surface defect detection systems can use image data to perform inspections and classifications for delivering high-quality products. With advancements in AI, real-time defect detection is streamlined and automated using sensors and pretrained AI models for replicable quality control.
Sweden-based company Sansera—a producer of connecting rods for diesel engines—collaborated with AI company Aixia to implement an automated, deep learning defect detection system in their production process using computer vision.
Found in buses, trucks, and ships, every rod in the manufacturing production process must be high quality, consistent, reliable, and documented. It is imperative that the high-resolution, visual inspection system detects and classifies defects in real time.
To help Sansera reach its manufacturing process quality control goals, Aixia developed and deployed a rod inspection and detection pipeline at Sansera’s production site. At the heart of the pipeline, is an NVIDIA Triton Inference Server deployed on the NVIDIA Jetson edge AI platform and data center servers. It is implemented on an x86 server with NVIDIA A10 GPUs for inference.
Using a quality vision inspection system, robots lift and display connecting rods to a set of AI-enabled cameras. The cameras take multiple photos to capture imprints and serial numbers, which are sent through AI-based computer vision models for inspection in a controlled lighting environment. The evaluations are performed in sequence and the results provide quality control documentation. Several deep learning inferences are performed per camera view.

Each connecting rod is inspected and documented properly before release. The job of this inference workflow is to detect the imprints, inspect their quality, and provide necessary details for the product documentation. The workflow is deployed and optimized on an NVIDIA Triton Inference Server, using different frameworks and consolidates quality use cases in a streamlined fashion.
Several models, in both pre-and post-processing, are consolidated within one server instance.
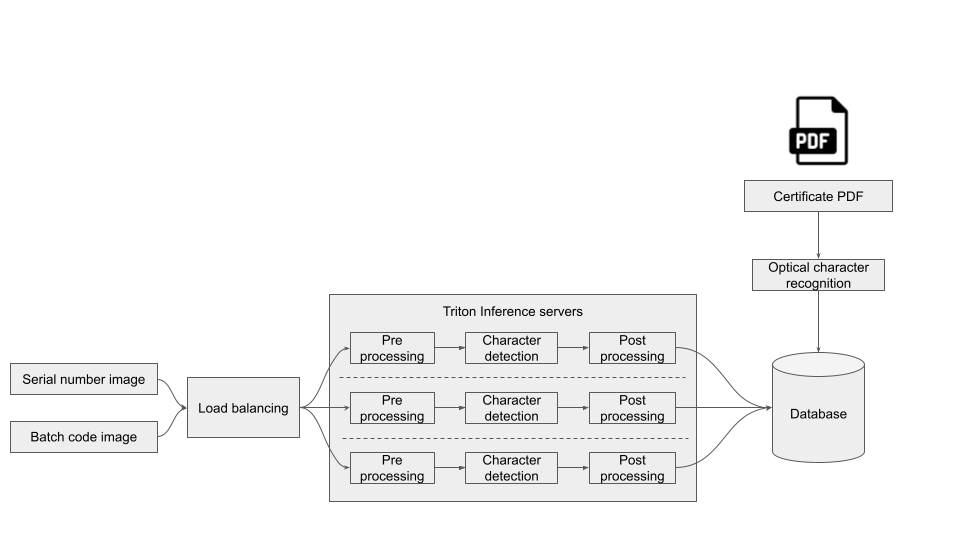
Using NVIDIA Triton, Aixia deploys optimized versions of the pretrained models, in the data center using high-performance GPUs, or on the edge close to the data using the Jetson edge AI platform.
Learn more about how NVIDIA Triton and NVIDIA Jetson can be used to run models at the edge.
